В этой главе мы продолжим наше исследование на тему о том, как совершенствовать методы проектирования с учетом использования сетей. В главе 11 мы изучили особенности проектирования баз данных
Oracle для модели клиент/сервер. Логично, что теперь необходимо рассмотреть, какое влияние на проектирование оказывает распределение функций хранения данных и управления ими между несколькими серверами.Когда использовать распределенные базы данных?
Существует много причин, которые могут подтолкнуть вас к мысли об использовании распределенной базы данных. Наиболее важными из них, на наш взгляд, являются следующие:
• Необходимость разместить часто используемые данные близко к клиентским приложениям, которым нужно к ним обращаться, и таким образом свести к минимуму число сообщений в сети и время доступа.
• Желание расположить изменчивые данные в одном месте, сведя таким образом к минимуму проблемы, связанные с наличием нескольких обновляемых копий таких данных.
• Стремление уменьшить влияние единичного отказа, например отключения сервера.
Если эти факторы являются ключом к успешной работе ваших приложений, то распределенная база данных может быть именно тем, что нужно. Однако следует учитывать, что и проектирование распределенной базы данных, и ее сопровождение после ввода в эксплуатацию нельзя назвать тривиальными задачами.
Существует много способов организации распределения данных. В этой главе мы рассмотрим большинство из них и, надеемся, что, изучив приведенный здесь материал, вы сможете принять обоснованное и продуманное решение.
В главе 11 содержится пример трехуровневой архитектуры типа клиент-сервер-сервер. Это сделано для того, чтобы показать, как локальный сервер, пользуясь преимуществом быстрой реакции локальной сети, может удовлетворять запросы на доступ к относительно статическим данным, которые реплицированы на него посредством среднего уровня. При этом более изменчивые данные размещены на центральном сервере (серверах), где легче организовать их совместное использование.
Однако в главе 11 мы не исследовали все последствия от применения такой модели. В примере, приведенном на рис. 12.1, показаны два связанных центральных сервера, каждый из которых непосредственно соединен с рядом промежуточных серверов. Давайте предположим, что связь, показанная между этими двумя серверами, необходима. Это означает, что центральные данные нельзя разделить таким образом, чтобы все записи, интересующие клиентов А и В, можно было держать на сервере X, а данные, интересующие клиентов С, — на сервере
Y.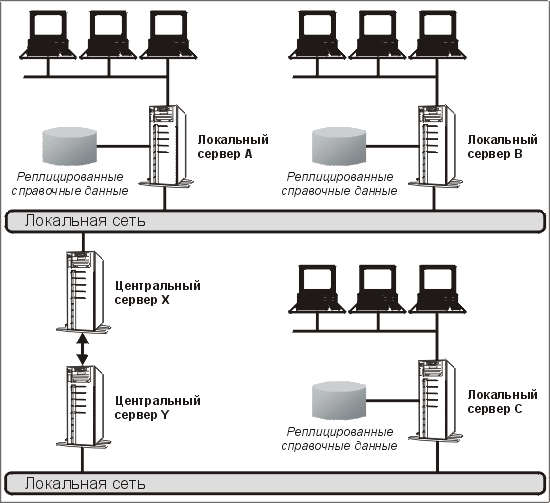
Рис. 12.1. Типичная сетевая топология
Тогда рис. 12.1 становится иллюстрацией распределенной базы данных — она содержит пять экземпляров справочных данных и два экземпляра рабочих данных. Несмотря на простоту топологии, с помощью этого примера можно показать особенности и проблемы, характерные для приложений распределенных баз данных. Так, например, в распределенных средах необходимо обеспечить:
• Непротиворечивость данных: вне зависимости от того, какой клиент используется в данный момент времени, пользователю должны быть предоставлены правильные и непротиворечивые данные, и все обновления, сделанные с этого клиента, должны быть защищены при фиксации.
• Производительность: и общая пропускная способность, и время реакции приложения на каждом клиенте должны соответствовать поставленным требованиям.
• Работоспособность: приложение должно быть достаточно надежным.
Эволюция средств поддержки распределения данных
OracleOracle стала предлагать частичную поддержку распределенных баз данных начиная с продуктов Oracle версии 5.1 и SQL*Net, которые позволяли производить удаленные запросы по каналам связи баз данных. При надлежащей конфигурации SQL*Net элементы словаря данных, создающиеся в следующем примере, можно использовать для достижения двоякой цели — обеспечения прозрачности расположения и независимости расположения.
CREATE PUBLIC DATABASE LINK elsewhere
CONNECT TO system IDENTIFIED BY manager
USING 'T:hp34:appdev';
CREATE PUBLIC SYNONYM dept FOR scott.dept@elsewhere;
CREATE PUBLIC SYNONYM emp FOR scott.emp@elsewhere;
Что это означает? При наличии этих элементов в словаре данных приведенный ниже SQL-запрос выберет необходимые данные из таблиц EMP и DEPT так, будто эти таблицы находятся в базе данных, к которой подключен пользователь. Расположение этих таблиц (т.е. базы данных, в которой они находятся) прозрачно для автора запроса, хотя оно должно быть известно администратору, создавшему элементы словаря данных. Кроме того, необходимые элементы были созданы независимо от целевой базы данных и таблиц.
SELECT d.dname
, e.ename
FROM emp e
, dept d
WHERE d.deptno = 10
AND d.deptno = e.deptno;
Каналы связи базы данных
Каналы связи базы данных могут использоваться неявно с помощью синонима (как в предыдущем примере) или явно, как в следующем примере:
SELECT ename FROM emp@elsewhere WHERE empno = 7319;
Каждый канал связи базы данных требует установления соединения с соответствующей удаленной БД. В
Oracle соединения с базой данных обходятся дорого — как с точки зрения ресурсов центрального процессора, затрачиваемых на их создание, так и с точки зрения памяти, используемой для их сопровождения. Например, для выполнения приведенного ниже запроса необходимо четыре соединения с базой данных — одно исходное и три через каналы связи БД.SELECT c.cust_name — выбрать покупателя, название и количество
, р.prod_name — товара для случая, когда куплено и оплачено
, SUM(l.qty) - более 100 единиц
FROM custs@hq с
, ordrs@sales о
, lines@sales l
, prods@mktg p
WHERE o.cust_id = c.cust_id
AND l.ord_id = о.ord_id
AND p.prod_id = l.prod_id
AND l.qty_id >= 100
AND o.status = 'PAID'
Для "популярных" серверов, т.е. серверов, которые являются объектом множества открытых каналов связи БД, число одновременно открытых Oracle-соединений может стать таким большим, что вызовет чрезмерную подкачку страниц памяти. Более поздние версии
Oracle7 не только позволяют администратору устанавливать, какое максимальное число каналов связи БД может быть открыто для процесса (через параметр DB_LINKS в файле init.ora), но и разрешают сеансу закрывать канал связи БД, занимающий ресурсы на удаленном сервере. Вот команды для этого примера:ALTER SESSION CLOSE DATABASE LINK hq;
ALTER SESSION CLOSE DATABASE LINK sales;
ALTER SESSION CLOSE DATABASE LINK mktg;
К сожалению, для установления соединения с
Oracle необходимы большие затраты времени центрального процессора на серверной стороне канала, поэтому при сколько-нибудь значительной вероятности того, что этот канал в ближайшем будущем понадобится вновь, вряд ли эффективно его закрывать. "Замораживание" одного-двух мегабайтов памяти на удаленном сервере может оказаться меньшим злом, чем затраты на подключение и отключение, которые придется понести потом. Если же удаленные серверы имеют ограниченные ресурсы и вы знаете, что какие-либо каналы вряд ли еще будут использоваться, то их закрытие позволит увеличить объем доступных ресурсов. Однако при этом также разрушится прозрачность расположения и потребуется более богатое функциональными возможностями приложение, чем то, которое захотят реализовать большинство проектировщиков и программистов.Распределенные соединения
В
Oracle версий 5 и 6 удаленный доступ по каналам БД был возможен только для запросов. Кроме того, существовал ряд проблем с производительностью, которые, в частности, влияли на соединения. Во многих случаях приходилось передавать по сети целые таблицы, чтобы выполнить соединение на сервере, к которому был подключен пользователь. Для 14-строчной таблицы ЕМР это серьезной проблемы не представляло, но для обеспечения масштабируемости приложений, использующих распределенные запросы, было большим препятствием.Примечание
Решение задачи с удаленными соединениями в примере с таблицами ЕМР и
Мы не рекомендуем использовать какие-либо распределенные соединения без предварительного тестирования их с реальными объемами данных. Если производительность неудовлетворительна, можно рассмотреть следующие варианты:
• Создать соединение так, чтобы обеспечить ссылку на одно или несколько представлений, как сказано в примечании, и переместить ключевые элементы оптимизации запросов на серверы, где их можно оптимизировать с большей эффективностью.
• Выполнить соединение средствами приложения с использованием удаленного
• Изменить распределение данных, использованных в соединении, перенеся одну или несколько таблиц в другую базу данных (или каким-либо
образом реплицировав эти данные). Это решение требует фундаментального изменения в структуре, и для поиска эффективной стратегии распределения, возможно, потребуется перебрать несколько вариантов. Именно поэтому мы так настаиваем на тестировании распределенного соединения на ранних этапах создания проекта.Последнее решение подводит нас к сути проектирования распределенных баз данных:
Стратегия распределения данных должна определяться требованиями
Наш опыт показывает, что руководители предприятий часто диктуют стратегию распределения данных, но очень редко предпринимают меры (если вообще предпринимают) для обеспечения ее осуществимости. Во многих случаях на практике стратегия распределения данных формулируется на основе принадлежности данных — совершенно бесполезного, но близкого большинству высших руководителей понятия. Многие руководители страдают навязчивым стремлением поближе разместить свои данные. Наверно, в детстве они привыкли прижимать к себе своих плюшевых мишек и отказывались спать без них.
Если вам не удается помешать руководству обсуждать привязку разных отделов и сотрудников к частям домена данных, попытайтесь ознакомить его с такими понятиями, как ответственность и требования доступа. Если вам говорят, что данные о запасах комплектующих деталей принадлежат какому-то отделу и в силу этого они должны физически располагаться на главном складе, то задайте руководителю такие вопросы:
• Несет ли заведующий складом персональную ответственность за точность
• Теряли ли когда-нибудь складские работники файлы на своих ПК?
• Несет ли заведующий складом персональную ответственность за обеспечение безопасного доступа к данным о деталях?
Статус стороннего консультанта часто помогает
реализовать качественно спроектированное приложения — в этом случае гораздо легче задавать такие острые вопросы!Удаленное обновление
Неспособность
Oracle версий 5 и 6 поддерживать удаленное обновление, конечно, можно очень просто преодолеть при помощи языков третьего поколения путем создания явных соединений с несколькими экземплярами базы данных. Установив эти соединения, программа может обновлять данные где угодно. Однако она также должна выдать явную команду фиксации в каждый из экземпляров, в который она выдала DML-команды. Этот подход можно использовать и в текущих версиях Oracle, однако разработчики редко пользовались им по двум веским причинам: ни на каких курсах (по крайней мере, на тех, о которых нам известно) множественные соединения не преподают, и никакие средства УРП эти соединения непосредственно не поддерживают. Как результат, их можно получить только при помощи языков третьего поколения. * Необходимые операции показаны ниже (в них используются поддерживаемые Рго*С конструкции SQL).ЕХЕС
SQL CONNECT :user_and_passwd AT :local_db;Однако при этом возникает один (скорее, теоретический) вопрос: что делать, если не выполнится вторая фиксация? Ведь к тому времени первую фиксацию нельзя отменить, и мы уже "осиротим" записи (сотрудников, подразделение которых больше не существует). Какие бы шаги мы не предприняли для решения этой проблемы, никуда не деться от неприятного факта: по крайней мере в течение некоторого времени для других пользователей будет доступна противоречивая база данных.
Мы называем эту проблему теоретической, так как вся проверка в
Oracle выполняется на этапе выдачи DML-операдий, поэтому вероятность невыполнения фиксации очень низка. Это происходит, как правило, лишь в случае, если по какой-то причине невозможно осуществить запись в журнал. Тем не менее, если взять все семейство проблем, связанных с этим решением (особенно когда задействовано несколько экземпляров базы данных), то мы наверняка захотим, чтобы их решила за нас система управления базой данных. Выход состоит в использовании двухфазной фиксации, которую часто обозначают как 2ФФ.Двухфазная фиксация
Используя двухфазную фиксацию, мы можем переписать наш пример так;
EXEC SQL CONNECT :user_and_passwd;
...
ЕХЕС SQL DELETE FROM dept@remote_db WHERE deptno = :dept;
EXEG SQL DELETE FROM emp WHERE deptno = :dept;
...
EXEC SQL COMMIT WORK;
В данном случае не только обеспечивается гарантия, что для транзакции будет выполнена либо полная фиксация, либо полный откат, но и то, что мы можем (если потребуется) вновь пользоваться преимуществами прозрачности и независимости расположения, применяя синонимы вместо каналов связи БД.
Принцип работы двухфазной фиксации — тема очень объемная, и в одном из следующих разделов мы подробнее рассмотрим некоторые особенности средств поддержки 2ФФ
Oracle. Здесь же мы просто опишем в общих чертах действие этого механизма. Когда выдается команда фиксации, один из экземпляров базы данных, участвующий в транзакции, принимает на себя роль координатора. Этот экземпляр выбирает один из экземпляров в качестве точки фиксации и дает всем остальным задействованным экземплярам (среди которых может быть и он сам, если он не является точкой фиксации) указание приготовиться. Фактически от спрашивает:"Если я попрошу вас выполнить фиксацию, вы сможете это сделать?"
Это — первая фаза.
После того как все другие экземпляры согласятся на фиксацию, точке фиксации предлагается выполнить обычную фиксацию. В зависимости от результата этой фиксации координатор просит все остальные экземпляры либо зафиксировать транзакцию, либо выполнить ее откат.
Это — вторая фаза.
Конечно, и в этом случае возможны всякого рода сбои. В любой момент могут отказать как отдельные серверы, так и сетевые каналы связи, но, невзирая ни на что, программное обеспечение должно гарантировать целостность данных. В итоге не только возникает значительный трафик сообщений, но и создаются потенциально устойчивые блокировки на уровне блоков.
Средства распределения данных
Oracle7После того как в
Oracle версии 7.0 была обеспечена реализация двухфазной фиксации, эта возможность была использована для создания ряда средств, помогающих реализовать в проектах распределение данных. Ниже перечислены самые важные из них. В скобках указывается номер версии, в которой впервые появилось соответствующее средство:• удаленный
• синхронные удаленные вызовы процедур (7.0);
• снимки (7.0);
• возможность иметь неограниченное количество триггеров на одной таблице (7.1);
• асинхронные удаленные вызовы процедур (7.1.6);
• непротиворечивые снимки (7.1.6);
• обновляемые снимки (7.1.6);
• асинхронная симметричная репликация (7.1.6);
• синхронная симметричная репликация (7.3).
Ниже мы рассмотрим каждое из этих средств. Для всех них, за исключением четвертого в списке, требуется покупка лицензии и инсталляция средства
Distributed Option от Oracle, а для последних трех средств также необходима инсталляция Data Replication Support. И Distributed Option, и Data Replication Support обычно поставляются за дополнительную плату. Информацию о существующих в данный момент правилах Oracle относительно цен и комплектования этих компонентов можно получить у своего администратора, отвечающего за учет.Шесть свойств сущностей, которые важны для обеспечения распределения данных
Перед тем как изучать, какие проблемы проектирования возникают при использовании каждого из перечисленных выше средств
Oracle, нужно подумать, какие результаты анализа могут оказать нам помощь в определении того, как распределять данные внутри приложения. Конечно, в документации, подготовленной на этапе анализа, описаны сущности, а не таблицы. Однако аналитики должны определить для каждой сущности следующие свойства, имеющие отношение к планированию распределения данных:Готовность
В течение какого времени должна быть доступна информация.
Достоверность
Насколько важно иметь доступ к актуальному значению.
Видимость
Насколько широкие полномочия предоставляются при запросе.
Доступность
Как часто необходимо запрашивать информацию.
Мутируемость
Насколько широкие полномочия предоставляются при изменении.
Изменчивость
Как часто требуется изменять информацию.
Если сущность можно разбить на несколько частей, то анализ также должен дать схему фрагментации, в которой описаны:
• все соответствия, которые могут использоваться для разбиения сущности на части;
• порядок определения частей;
• точка, из которой будет запрашиваться и обновляться каждая часть, т.е. видимость, готовность, мутируемость и изменчивость части сущности. Если ни одно из этих свойств от части к части не изменяется, то необходимость разбиения сомнительна.
Мы назвали эти свойства шестью "-остями ".
При наличии для каждой сущности всех шести "-остей" и схем фрагментации некоторые решения о распределении данных принять очень просто. Отважный проектировщик (при отсутствии такового это будем мы или вы) берет логическую схему доступа к данным и с ее помощью принимает, решение о физическом расположении данных в сети. При этом проектировщик должен обеспечить контроль избыточности, минимизировать влияние выхода из строя системы и сети, а также обеспечить поддержку точности данных, оптимальное время реакции и простоту администрирования всей распределенной среды.Давайте возьмем данные нескольких типов и посмотрим, каковы их свойства.
Пример: справочные таблицы
Как мы упоминали ранее, приложение часто содержит ссылочные, или справочные, таблицы. У этих таблиц есть несколько важных характеристик:
• они постоянно используются всеми пользователями;
• они вряд ли когда-либо изменяются;
• если они изменяются, то только одним человеком, занимающим соответствующую должность;
• не обязательно иметь самую последнюю версию таких таблиц.
Сущности, на которых построены эти таблицы, описываются как имеющие следующие свойства:
• максимальную готовность;
• низкую достоверность;
• высокую видимость;
• высокую доступность;
• минимальную мутируемость;
• очень низкую изменчивость.
Экземпляры справочных данных могут располагаться на каждом сервере в сети при условии, что существуют надежные средства распространения изменений. В этом случае можно также считать все копии этих данных, кроме одной, неизменяемыми — за исключением ситуации, когда изменения копируются из обновляемой копии в другие.
То, что распределение возможно, вовсе не означает, что мы должны его использовать. Если это поможет сократить число обращений по глобальной сети, то такое решение выглядит привлекательно. Изменение распределенных данных можно реализовать при помощи механизма снимков
Oracle (который подробно описан далее). Снимки можно сконфигурировать так, чтобы при регенерации снимка распространялись только изменения. Такое распределение данных показано на рис. 12.2.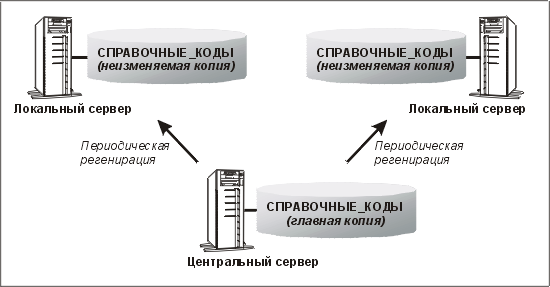
Рис. 12.2. Распределение справочных данных
Пример: данные о служащих
Теперь рассмотрим другой случай, когда нам нужно иметь данные о служащих, при запросах к которым должны возвращаться только актуальные значения. Эти данные используются только при расчете месячной заработной платы и руководителями подразделений в нерегламентированных запросах. Руководители подразделений могут получать доступ к записям только о своих подчиненных, а изменять эти данные могут только бухгалтеры подразделений. Сущности, на основе которых строятся такие данные, имеют следующие свойства:
• среднюю готовность;
• максимальную достоверность;
• минимальную видимость (потому что доступ ограничен конкретным подразделением);
• среднюю доступность;
• низкую мутируемость;
• низкую изменчивость.
Эти данные должны находиться только на том сервере, на котором ведется учет заработной платы по подразделениям. Таким образом, за исключением резервного копирования, никаких требований о наличии копий на других серверах нет. Эти данные горизонтально секционированы, и особой поддержки со стороны БД не требуется. Секционирование обеспечивает также некоторые требования к доступу и безопасности, так как руководители подразделений должны видеть только данные о заработной плате, находящиеся на сервере, к которому они подключены. В этом примере мы предполагаем, что каждый региональный сервер имеет собственное локальное приложение для расчета заработной платы. В противном случае возникают требования к поддержке приложений. Описанная конфигурация представлена на рис. 12.3.
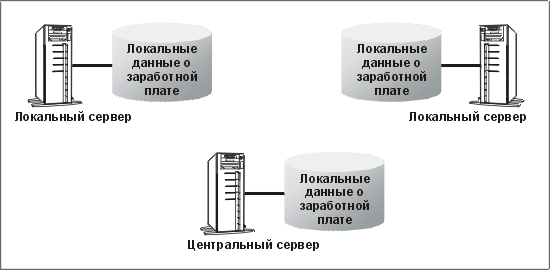
Рис. 12.3. Горизонтально секционированные данные
Часто в одном приложении встречаются оба рассмотренных нами типа данных. Например, можно ожидать, что в системе расчета заработной платы, помимо записей о служащих (сопровождение которых обеспечивает узел, отвечающий за эти данные), используется ряд кодовых наборов (с централизованным сопровождением). Возможно, нам потребуется передавать данные-сводки на центральный сервер или сервер штаб-квартиры.
В настоящее время средства распределенных баз данных
Oracle не обеспечивают непосредственную поддержку такой централизации итоговых данных, хотя и можно настроить структуры данных таким образом, чтобы механизм обновляемых снимков Oracle мог передавать итоговые данные в "центр". Однако в этом случае главную систему необходимо защитить от обновления.Пример: выплата страхового возмещения
Один из авторов недавно работал над проектом создания приложения, представляющего собой систему обработки выплат страхового возмещения, в которой требования о выплате создаются одним из семи региональных офисов и принадлежат ему. Сам головной офис требования не создает, но выполняет аудиторские и ИУС-запросы по всем требованиям. Вероятно, эта схема будет реализована (пока она находится на этапе проектирования) с помощью обновляемых снимков, причем главная таблица будет находиться в системе головного офиса, а в каждом из регионов будет свой горизонтальный срез.
Все вставки и обновления в такой схеме выполняются над снимками, а главная таблица используется только для запросов. Одно из удобств этой системы состоит в том, что в случае (редком), если требование пересылается из одного региона в другой, простое обновление снимка (изменение данных в столбце региона, определяющем сегментацию) приводит к удалению требования из одной горизонтальной секции и быстрому появлению его в другой. Единственная проблема здесь в том, что
в промежутке между исчезновением и повторным появлением требование не принадлежит ни одному региону и может быть найдено только с помощью непосредственного запроса к главной таблице. Предлагаемая структура показана на рис. 12.4.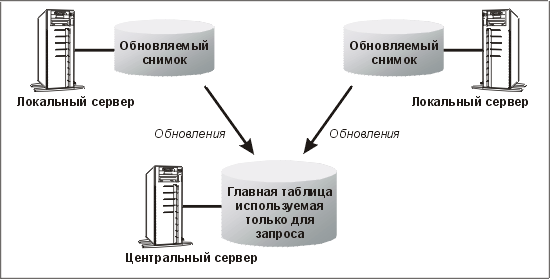
Рис. 12.4. Использование обновляемых снимков для распространения итоговых данных
Мы предпочитаем локально реализованную структуру, в которой может использоваться, а может и не использоваться двухфазная фиксация. На наш взгляд, должен быть некоторый предел тому, до какой степени можно "изгибать" структуру с целью использования возможностей продукта, когда явно видно, что разумнее реализовать специализированное решение.
Пример: обновление через глобальную сеть
В качестве еще одного примера давайте рассмотрим систему бронирования авиабилетов, в которой для обновления текущих данных необходим доступ по глобальной сети. Самый простой и эффективный выход в данном случае — вообще не распределять данные, а пересылать все запросы доступа на центральный сервер, который обладает достаточной мощностью и способен справиться с глобальной нагрузкой. Если вы когда-нибудь задавали себе вопрос, как мэйнфрейм ухитряется выжить в разукрупненном, распределенном мире открытых систем, то сейчас вы, вероятно, знаете ответ. На текущий момент все еще крайне сложно при помощи одной базы данных
Oracle обслуживать свыше 2000 одновременно работающих пользователей.Почти так же сложно поддерживать 100000 одновременно работающих пользователей на одном мэйнфрейме, но этот уровень сервиса необходим ряду предприятий, и они изо дня в день обеспечивают его вот уже несколько лет, причем время работы в таком режиме превышает 99%.
Вы (или ваше руководство) можете, отвергнуть вариант с мэйнфреймом по ряду понятных причин:
• высокая стоимость аппаратных средств;
• большой сетевой трафик;
• высокая стоимость разработки;
• большие сроки разработки.
Если вариант с мэйнфреймом отпадает, то речь может идти о симметричной репликации. При этом создается несколько копий (главных), в которые можно вносить изменения. Затем эти изменения (асинхронно или синхронно) будут распространяться в другие главные копии. Однако мы должны предупредить, что если не подходить к таким проектам с большой осторожностью (не говоря уже о здоровом скептицизме), то экономия затрат на разработку и сокращение сроков разработки будут гораздо меньше ожидаемых. Попытка реализовать открытую систему реляционными методами может обойтись дороже, чем проект на базе мэйнфрейма, если при этом используются средства ускоренной разработки приложений (УСП), которые ранее применялись лишь к небольшим приложениям масштаба подразделения. Что поделаешь, такова жизнь.
В некоторых случаях распределение данных навязывается давней тенденцией к использованию серверов подразделений. Если новое приложение, работающее на новом сервере, нуждается в доступе к старым данным, хранящимся на существующем сервере, то некоторая форма распределения данных неизбежна. Способ реализации этого распределения подскажет анализ шести "-остей", о которых мы говорили выше. В некоторых случаях новая система может работать со своей собственной копией "разделяемых" данных, обновление которых производится не очень часто, например раз в месяц. В таком режиме обычно работают хранилища данных и ИСР, где вообще не выполняется обновление. Иногда степень трансформации данных при пересылке настолько высока, что результат уже нельзя классифицировать как распределенную базу данных. Его можно рассматривать, скорее, как данные, которые переданы из одного приложения в другое с использованием традиционного способа 60-х годов, предполагающего обработку данных на лентах. Если каждому из двух приложений нужно вносить изменения в данные, которые доступны другому приложению в оперативном режиме, то при принятии решения о числе копий данных — одна или две — необходимо учитывать объемы запросов и обновлений с каждого сервера.
Выбор стратегии распределения данных
До сих пор мы рассматривали общие принципы распределения данных. Мы также узнали, что для принятия правильного решения о распределении данных в конкретном приложении необходимо, чтобы для каждой сущности в аналитической документации были указаны шесть "-остей". Теперь мы готовы более подробно изучить средства поддержки удаленного обновления
Oracle и посмотреть, как применять эту поддержку в различных ситуациях.Перед тем как углубиться в детали и рассматривать каждое средство по отдельности, давайте сначала определим, почему может возникнуть вопрос о распределении данных. Распределение данных в проекте осуществляется с целью:
• сократить нагрузку на сеть или сервер или
• повысить уровень готовности.
И все. Других причин для того, чтобы рассматривать даже возможность распределения данных, нет. Для каждой рассматриваемой топологии распределения данных мы должны тщательно проверить, не создастся ли при этом неприемлемая нагрузка на какую-либо ветвь сети, сервер или сетевую плату и не снизится ли готовность до уровня, ниже допустимого.
Примечание
В этой главе мы мало говорим о шлюзах, предлагаемых
В качестве "патологического" примера рассмотрим систему обработки заказов, в которой заказы хранятся на локальном сервере в офисе, ближайшем к адресу доставки заказа, но записи о клиентах хранятся в отделе сбыта, принявшем первый заказ от данного клиента. По идентификатору клиента нельзя определить, на каком сервере находится данная запись, поэтому для поиска клиента, отсутствующего на локальном сервере, необходимо опросить все остальные серверы. Обычно это делается через представление, которое определяется следующим образом:
CREATE VIEW all_customers (cust_loc, cust_id, cust_name, ...) AS
SELECT 'LOCAL', cust_id, cust_name,...
FROM customers - из локальной базы данных в Нью Йорке
UNION ALL
SELECT 'LONDON', cust_id, cust_name,...
FROM customers@london
UNION ALL
SELECT 'TOKYO', cust_id, cust_name,...
FROM customers@tokyo
UNION ALL
SELECT 'SYDNEY', cust_id, cust_name,...
FROM customers@sydney
UNION ALL
SELECT 'LOS ANGELES', cust_id, cust_name,...
FROM customers@la;
Имея такое представление, создать запрос на поиск клиента очень просто. Однако, чтобы найти клиента, необходимо посетить все базы данных. Если какая-нибудь из нужных баз данных не работает, то запрос выдаст ошибку.
Обновлять запись о клиенте после того, как она выбрана, труднее, потому что программа (или, по крайней мере,
PL/SQL, неявно или явно вызванный ею) должна направить обновление на соответствующий сервер — вот почему в представлении присутствуют данные о местоположении.И представление, и синонимы, используемые в запросах, создающих представление, на каждом узле должны быть разными, если только вы не хотите писать запрос в локальной базе данных с помощью канала связи БД. Это отрицательно скажется на производительности, потому что запрос должен будет установить второе соединение с локальной базой данных вместо того,
чтобы использовать уже имеющееся, абсолютно работоспособное, соединение.Однако все эти проблемы меркнут перед тем, какое влияние оказывает представление на производительность и готовность. Даже если используется
Parallel Query Option (см. главу 14), запросы параллельно не выполняются. Каждый запрос производится только после того, как разрешен предыдущий, и вы можете получить сообщение об ошибке, если какая-либо база данных к запросу не готова.Таким образом, рассматриваемый вариант принять нельзя — он будет работать хуже, чем при хранении базы данных клиентов на одном назначенном сервере, да и готовность его будет ниже. Меры, при помощи которых можно повысить жизнеспособность такой системы, существуют, но все они предполагают написание дополнительного кода, единственная задача которого — уменьшить отрицательные последствия непродуманного и ненужного проектного решения. Нам кажется, что проще попытаться исправить само решение.
Материал, предлагаемый в следующих разделах, призван помочь вам это "сделать. Однако помните, что для успешного использования описанных средств вы должны знать шесть "-остей" своих данных. Работая вслепую, вы в лучшем случае ничего не улучшите, а в худшем — сделаете проектируемую систему неработоспособной.
Подробнее о двухфазной фиксации
Ранее в этой главе мы уже описывали, как осуществляется двухфазная фиксация. Этот же механизм используют и средства ее поддержки в
Oracle. Однако с ними связан ряд проблем, о которых должен знать каждый проектировщик.Потребность в двухфазной фиксации
Первая проблема — настоящая "Уловка-22". Когда начинается процесс фиксации, координатор спрашивает у каждого экземпляра, "посещенного" в данной транзакции, производил ли он изменения и применял ли блокировки. Экземпляры, которые не производили изменения и не применяли блокировки, никакой роли в последующих событиях не играют. Предположим, что мы выдаем всего одну команду, используя канал связи БД
Chicago:UPDATE emp@chicago SET sal=sal*1.05 WHERE deptno = 26;
Если в отделе 26, зарегистрированном в чикагской версии таблицы, служащих нет, то, когда координатор спросит у чикагского экземпляра, вносил ли он изменения, экземпляр ответит отрицательно. В результате этого, если транзакция вносит изменения только в один (даже удаленный) экземпляр базы данных, двухфазная фиксация не требуется. "Уловка-22" состоит в том, что в
Oracle необходимо иметь компонент Distributed Option (включающий двухфазную фиксацию), чтобы определить, что двухфазная фиксация не требуется. Другими словами, если двухфазная фиксация не инсталлирована, то нельзя обновить данные через канал связи БД даже в тех случаях, когда двухфазная фиксация не требуется.Сомнительные данные
Вторая проблема состоит в том, что в промежутке времени между подготовкой и фиксацией данные считаются сомнительными. Когда база данных, в которой выполнено обновление, получает команду подготовки, то до тех пор, пока координатор не просигнализирует о второй фазе фиксацией или откатом, никак нельзя определить, зафиксированы данные или нет. По этой причине
Oracle с помощью блокировки на уровне блока предотвращает доступ к этим данным, поскольку не может определить, следует ли применять согласованность по чтению. Обычно в среде локальной сети эти блокировки существуют всего несколько миллисекунд, а в глобальной сети — несколько сот миллисекунд. Тем не менее, если какая-то проблема (например, сбой в сети) не дает завершить вторую фазу, то сомнительные данные остаются недоступными до тех пор, пока проблема не будет решена. Решить ее можно либо с помощью встроенного в Oracle механизма восстановления, либо путем вмешательства администратора БД, который должен выдать SQL-предложение COMMIT FORCE или ROLLBACK FORCE.Предупреждение
Эти устойчивые блокировки "выживают" при закрытии экземпляра и продолжают действовать после его перезапуска. Они предотвращают все виды доступа (включая запросы) к данным соответствующего блока.
Экземпляр, выполняющий традиционную фиксацию, называется точкой фиксации. Он не обязан переводить блоки в категорию сомнительных. Естественно, чем важнее база данных, тем меньше должен быть риск появления в ней сомнительных данных. Поэтому в файле init.ora Oracle предусмотрен специальный параметр — COMMIT_POINT_STRENGTH, и в любой распределенной транзакции точкой фиксации будет экземпляр с наибольшим значением этого параметра. Однако мы рекомендуем тщательно проверить документацию на предмет важного исключения из этого правила — когда сами удаленные операции включают удаленные операции.
Последовательные операции
Есть еще и третья проблема. При оценке вероятной продолжительности двухфазной фиксации (а особенно двухфазного отката транзакции) необходимо иметь в виду, что требуемые операции выполняются последовательно, а не параллельно. Так, двухфазная фиксация, координирующая три удаленных экземпляра (каждый из которых связан через Х.25 со временем отклика 500 мс), вполне может занять четыре секунды (если координирующий экземпляр является и точкой фиксации).
Предупреждение
К откату транзакции следует относиться внимательно по той причине, что в Oracle откат всегда длится дольше, чем фиксация. Фактически Oracle никогда не помещает элемент отката в журнал — когда экземпляр получает команду об откате транзакции, он читает цепочку элементов отката данной транзакции. Для каждого такого элемента он создает запись в журнале, поэтому при восстановлении будут проведены те же самые изменения, выбраны требуемые блоки данных, а данные будут восстановлены в обратном порядке. Затем, когда будут обработаны все элементы сегмента отката, экземпляр запишет фиксацию в журнал и очистит буфер.
При фиксации просто нужно записать элемент фиксации в журнал и очистить буфер (а в версии 7.3 еще снять блокировки уровня строки, если измененные блоки все еще находятся в памяти). Отметим также, что для обеспечения восстановимости
Oracle применяет журнальные записи и выполняет действия по откату транзакции в порядке, который кажется "неверным". Элементы журнала и элементы отката транзакции создаются перед внесением изменения, к которому они относятся. Благодаря этому изменение производится только при наличии защищающих его элементов.Удаленные DML-операции
Мы уже несколько раз использовали термин "удаленные DML-операции". Под DML-операциями
(Data Manipulation Language — язык манипулирования данными) мы подразумеваем только те операции, которые задаются следующими SQL-предложениями:INSERT
UPDATE
DELETE
SELECT...FOR UPDATE
LOCK
Имеющиеся в
Oracle средства поддержки распределенных баз данных не обеспечивают непосредственную поддержку удаленных DCL-операций (Data Control Language — язык управления данными), таких как GRANT и REVOKE, и удаленных DDL-операций (Data Definition Language — язык определения данных), например CREATE, ALTER, DROP. Однако средства поддержки симметричной репликации включают PL/SQL-пакет под названием DMBS_REPCAT, который способен выполнять удаленные DDL-операции, необходимые для настройки схемы распределенной репликации.Однако несмотря на это, если прикладная логика потребует, чтобы процесс мог создавать таблицы, выдавать разрешения, усекать таблицы — короче, выполнять все, помимо запросов и пяти вышеупомянутых DML-операций, вы не сможете выполнить соответствующие операции на удаленном узле. Мы, конечно, можем ответить вопросом: а почему вы думаете, что вам понадобится выполнять такие операторы в рамках обычных транзакций? Мы бы напомнили также, что в
Oracle DDL-операции имеют две неявные фиксации:• когда выдается DDL-операция, фиксируются все текущие транзакции данного сеанса;
• когда DDL-операция завершается, то она фиксируется (или откатывается, если обнаружена ошибка).
Таким образом, DDL-операция всегда вызывает завершение текущей транзакции.
Синхронные удаленные вызовы процедур (RPC)
Помимо возможности выдавать удаленные DML-операции, мы также можем вызывать удаленную процедуру — либо через синоним, либо явно задавая канал связи БД:
success := stock.alloc@stores ( cust_id => 'C155'
, part_no => 'AC7/95'
, qty => 6
);
Это исключительно мощный способ выдачи удаленных DML-операций и даже удаленных запросов, потому что, во-первых, при этом сокращается число сообщений, передаваемых по сети (требуется всего одна пара сообщений независимо от объема работы, которую нужно выполнить на удаленном узле), а во-вторых, обеспечивается инкапсуляция. В локальной среде мы должны знать только то, что нужно сделать, а не то, какие структуры данных необходимы для этого.
К сведению
Мы настоятельно рекомендуем программировать все ссылки между приложениями с использованием RPC, чтобы предотвратить возникновение так называемой взаимозависимости схем. Она может возникнуть в случае, когда несколько приложений используют удаленные запросы и удаленные DML-операции для доступа к данным друг друга. Если доступ осуществляется непосредственно через
Используя вместо
SQL вызовы процедур, мы можем создать один уровень изоляции, который поможет облегчить проблему взаимозависимости схем. Применение пакетных процедур и функций позволяет дополнительно уменьшить масштабы этой проблемы, так как дает возможность прибегнуть к перегрузке. Предположим, что мы решили ввести новую версию функции alloc, в которой требуемая дата (NEEDED) является обязательным параметром. После выполнения перегрузки нет необходимости переделывать существующие вызовы — они будут работать. Это иллюстрирует приведенный ниже код.Учтите, что и вызывающие, и вызываемые базы данных должны поддерживать
Distributed Option, следовательно, функция alloc сама может производить удаленные запросы, DML-операции и вызовы процедур. Отметим также, что этот процесс может быть многоуровневым, что серьезно влияет как на время реакции, так и на готовность....
FUNCTION alloc ( cust_id IN NUMBER - новый формат идентификатора пользователя
, part_no IN VARCHAR2 - номер детали
, qty IN NUMBER - необходимое число единиц
, needed IN DATE - требуемая дата
) RETURN BOOLEAN IS
BEGIN
...
END; - alloc
- для совместимости сверху вниз мы даем старый формат
- с идентификатором пользователя в виде строки и без необходимой
- даты, чтобы распределение осуществлялось из запаса, уже
- находящегося на складе
FUNCTION alloc ( cust_id IN NUMBER
, part_no IN VARCHAR2
, qty IN NUMBER
) RETURN BOOLEAN IS
BEGIN
RETURN alloc(TO_NUMBER(cust_id, part_no, qty, TRUNK(SYSDATE));
END; - alloc
В версиях 7.0, 7.1 и 7.2
RPC имеют еще одну, довольно странную, особенность: они могут вызывать ошибки, которые таинственным образом исчезают при следующей попытке выполнить ту же операцию. На первый взгляд, эта особенность может показаться очень удобной. Действительно, если бы при вторичном запуске процесса все ошибки пропадали, программирование значительно облегчалось бы. Почему эта ситуация возникает при использовании RPC — вопрос, скорее, не к проектировщику, а к администратору БД, поэтому мы не будем здесь объяснять, почему так бывает, а просто предостережем проектировщиков: знайте, что если удаленно вызываемые процедуры или пакеты изменяются, то для обеспечения нормальной работы необходимо перекомпилировать весь остальной код, вызывающий эти фрагменты. Для ссылок в одном и том же словаре данных это происходит автоматически, но механизм запуска перекомпиляции на удаленных узлах в ранних версиях не так изящен.Снимки
Как следует из названия, снимок — это копия таблицы (или таблиц), снятая в некоторый момент времени. Он определяется запросом к таблице или к совокупности таблиц (главной таблице снимка) и может быть простым либо сложным. Механизм снимков позволяет администратору БД определять другие схемы, в которых этот снимок будет регенерироваться с некоторым заданным интервалом.
Простой снимок строится на запросе, который не выполняет соединение и не содержит никаких итоговых функций. Сложный снимок может иметь одну или обе эти особенности. Важное различие между ними состоит в том, что сложные снимки можно регенерировать только путем полной их перезагрузки, тогда как простые снимки могут быть объектом ускоренной регенерации, при которой передаются только изменения.
На первый взгляд, снимки кажутся весьма полезными для сопровождения в масштабах всей сети копий таких объектов, как таблицы кодов, т.е. часто используемых, но редко обновляемых таблиц. При помощи фразы
WHERE в определяющем запросе можно создавать простые снимки, не содержащие некоторые строки главной таблицы (которые, возможно, на удаленном узле не нужны). Кроме того, используя список SELECT, можно удалить некоторые столбцы — из соображений безопасности или просто из-за того, что они не нужны. Таким образом, простой снимок может быть как горизонтальным, так и вертикальным подмножеством главной таблицы (или и тем, и другим), как показано на рис. 12.5.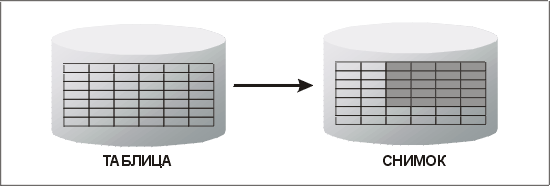
Рис. 12.5. Снимок, который является и вертикальным, и горизонтальным подмножеством таблицы
Основные проблемы со снимками касаются их эффективности (даже при ускоренной регенерации) и того факта, что, делая ссылку на снимок из программы, вы не можете быть уверены, что получите самые последние данные. Если надежность значения не имеет (насколько правдоподобно это звучит?), а сервер, на котором расположена главная таблица, может выдержать нагрузку от работы триггеров, выполняющих регистрацию всех внесенных изменений, то простые снимки с ускоренной регенерацией могут быть очень эффективны. Если же вносятся большие объемы изменений, а затем главная таблица остается стабильной в течение продолжительного времени, то, возможно, лучше подождать завершения внесения изменений и сразу после этого вручную (или программным способом) принудительно выполнить полную регенерацию.
Предупреждение
До версии 7.3 для записи изменений при ускоренной регенерации использовался идентификатор строки. Любая форма сопровождения снимка, при которой выполнялась его реорганизация (например, экспорт с последующим импортом), приводила к тому, что ссылки становились недействительными.
Еще одна проблема с первыми средствами поддержки снимков в
Oracle возникала потому, что, поскольку все снимки регенерировались независимо, обеспечить их соответствие друг другу было невозможно. Так, если главными таблицами для двух простых снимков были родительская и дочерняя, нельзя было поддерживать ссылочную целостность между такими снимками (даже, если она полностью поддерживалась между главными таблицами). Это происходило по очень простой причине: нельзя было гарантировать, что снимки делаются в абсолютно одной и той же точке согласованности по чтению. Конечно, изобретательный администратор БД мог решить эту проблему, если частота регенерации снимков была не слишком высока и обновления на сервере с главными таблицами выполнялись нечасто. Однако, несмотря на это, стало ясно, что средства поддержки Oracle в этой важной области неудовлетворительны. На решение данной проблемы было нацелено введение групп снимков, которые описаны ниже.Предупреждение
Устанавливая интервал регенерации снимка, следует помнить о проблеме "ползучего отставания". Она возникает, когда регенерация фактически выполняется не так часто, как планировалось при определении интервала. Это может происходить по нескольким причинам. В частности, потому, что интервал определен как время с момента завершения одной регенерации до начала следующей и, следовательно, при этом не учтена средняя продолжительность регенерации. Кроме того, следует учитывать, что фоновые задачи, выполняющие регенерацию
Непротиворечивые снимки
Как мы говорили, для преодоления сложностей, связанных со снимками, построенными на родительских и дочерних таблицах,
Oracle ввела группы снимков. Группы снимков являются объектом непротиворечивой регенерации, когда каждый член группы регенерируется по состоянию на один и тот же момент времени. Возможность применения этого средства обязательно стоит рассматривать для кодовых структур, имеющих связи по внешнему ключу.Обновляемые снимки
Мы уже видели, как при помощи снимков, которые могут быть горизонтальными или вертикальными секциями таблицы, можно разместить части центральной главной таблицы на разных серверах.
В версии 7.1.6 снимки стали факультативно обновляемыми. Это означает, что простой снимок, включающий столбцы типа
NOT NULL главной таблицы, можно обновлять, и все внесенные изменения будут распространяться обратно в родительскую таблицу. Это распространение выполняется позже с помощью механизма, который похож на рассматриваемый ниже в разделе "Асинхронная симметричная репликация". Если главная таблица никогда не обновляется и отдельные таблицы-снимки не пересекаются, то это совершенно безопасный подход. Он обеспечивает удобную схему для управления данными в случае, когда ответственность за разные подмножества может быть возложена на разные серверы, а запросы требуется выполнять ко всей популяции данных.Однако, как только становится возможным обновлять одну и ту же запись (строку) более чем в одной физической базе данных, любой асинхронный метод может вызвать конфликты. Мы опишем эти конфликты и способы их разрешения в следующем разделе.
Если вы пользуетесь обновляемыми снимками, то должны знать о следующих двух наиболее важных "ловушках":
• Когда создается обновляемый снимок, ограничения из главной таблицы не наследуются (включая ограничения
• Необходимо соблюдать осторожность при создании триггеров на обновляемых снимках. Предположим, что у нас есть триггер на таблице ORDER_LINES, который обновляет суммарную стоимость заказа в таблице ORDERS (денормализованный столбец). Например, в триггере BEFORE INSERT мы прибавляем к общей стоимости заказа стоимость нового элемента заказа. Мы хотим, чтобы это происходило на всех узлах, и поэтому помещаем триггер не только на главную таблицу, но и на SNAP$-таблицы всех остальных узлов. Коды триггеров одинаковы, и на узлах-снимках они фактически обновляют представление таблицы ORDER. Мы включаем снимки на базе таблиц ORDERS и ORDER_LINES в группу, чтобы они обновлялись одновременно. Есть, правда, одна проблема: группа снимков гарантирует, что эти две таблицы будут обновляться в один момент времени, однако изменения будут применяться в произвольном порядке. Если заказ обновляется до строки заказа, то при вставке строки заказа сработает триггер на главной таблице и аддитивный триггер добавит стоимость этой позиции заказа вторично (и сделает стоимость неверной).
• Чтобы избежать повторного применения триггера, можно воспользоваться функцией DBMS_SNAPSHOT.AM_I_A_REFRESH, но здесь есть более глубокая проблема. Происходит распространение большого объема данных, поэтому стоит рассмотреть такой вариант: не создавать триггер на SNAP$-таблице и выполнять фильтрацию изменений на главном узле. Этот вариант предпочтителен, если можно продолжить работу с неверной суммой заказа до тех пор, пока снимок не будет полностью синхронизирован с главной таблицей. Поскольку это вряд ли возможно, то в данном случае, вероятно, стоит вообще воздержаться от денормализации.
При проектировании распределенных баз данных вы встретите много таких головоломок, поэтому будьте внимательны и попытайтесь их избежать!
Неограниченное число триггеров на одной таблице
Запись изменений в главные таблицы выполняется с помощью триггеров на соответствующих таблицах. В версии 7.0 это вызывало серьезную проблему. Если инсталляционный скрипт какого-то фрагмента ПО хотел поместить триггер на таблицу (например, триггер
BEFORE INSERT уровня строки), а такой триггер уже существовал, то возникший в результате конфликт можно было разрешить только путем слияния этих двух триггеров. К принятию этого решения склонялись очень немногие авторы инсталляционных скриптов (а то и вообще таких не было), поэтому возможность иметь на таблице несколько триггеров с одинаковыми временными параметрами оказалась очень кстати.Пытаясь отбить у создателей триггеров охоту вводить какую-либо зависимость от других существующих триггеров,
Oracle специально характеризует порядок срабатывания триггеров как "неопределенный". Мы — убежденные сторонники этого подхода. Вся идея наличия множества триггеров состоит в том, чтобы позволить разным приложениям выполнять определенные действия на основании конкретного типа изменения, вносимого в конкретную таблицу.И снимки, и репликация требуют создания триггеров на таблицах, в которые предстоит распространять изменения. Поскольку теперь позволено иметь несколько триггеров по каждому из 12 возможных событий, то вы можете определять триггеры, не создавая проблем для других триггеров, уже срабатывающих по этому же событию.
Асинхронные удаленные вызовы процедур
Описывая распределенную среду, мы несколько раз упоминали о проблемах с большим числом сообщений и проблемах, которые могут создаваться в результате сбоев в сети и закрытий экземпляров. Ясно, что если приложению, работающему на одном сервере, нужны данные, хранящиеся на другом сервере (и только на нем), то оно сможет получить к ним доступ только в случае, если работают и сеть, и второй сервер. Другое дело — обновление. Если приемлема ситуация, когда обновление может некоторое время (а то и вообще) не выполняться, то вы можете существенно повысить и готовность, и пропускную способность путем использования асинхронных
RPC.Ваш процесс вызывает локальный сервис, который отмечает необходимый вызов и ставит его в очередь. Затем в будущем элементы очереди будут скопированы на удаленный сервер и помечены как переданные (с помощью двухфазной фиксации). Конечно, нет никакой гарантии, что удаленный сервер сможет выполнить эти задачи успешно.
Таким образом, если планировать использование асинхронных RPC в примере с отпуском деталей со склада, то было бы разумным заставить удаленную процедуру выдавать обратно на оригинальный сервер асинхронный RPC с результатом операции. Каждые несколько часов (или несколько минут, или несколько дней, в зависимости от активности) можно составлять
отчет, отражающий все операции с деталями, которые либо закончились неудачей, либо не сопровождались подтверждением. Эта задача может быть частью основного приложения или же, что более удобно, выполняться каким-нибудь средством управления приложениями, например PATROL фирмы ВМС. В любом случае она представляет собой чистое проектирование. Нужно довести эту информацию до сведения аналитиков и согласовать вопрос о том, как решать эту ситуацию на бизнес-уровне. Исходя из нашего опыта работы с бизнес-аналитиками, их мнение можно предугадать: операции необходимо производить в оперативном режиме, чтобы эта проблема не возникала!Получив такой ответ, следует вернуться к шести "-остям" и найти компромиссное решение, которое лучше удовлетворяет самым важным требованиям.
Асинхронная симметричная репликация
Средства асинхронной симметричной репликации позволяют нескольким копиям одной таблицы одновременно существовать в разных базах данных и, следовательно, на разных серверах. Ни одна из копий не является главной: все они равны, или симметричны. Можно вносить изменения в отдельные реплицированные таблицы, и эти изменения распространяются асинхронно в остальные копии этой же таблицы. Время, необходимое для
распространения изменения, зависит от различных параметров, установленных администратором БД, а также от готовности баз данных, в которые распространяются изменения. В результате могут, естественно, возникать конфликты обновления. Для их устранения в Oracle имеются как средства обнаружения конфликтов, так и средства их разрешения, в том числе возможность реализовать набор специализированных правил в PL/SQL.Обнаружение конфликтов при обновлениях в
Oracle осуществляется просто, поскольку распространяются и старые, и новые значения. Если на каком-либо узле строка в текущий момент не содержит распространенное старое значение, это говорит о наличии конфликта обновления. Легко и просто. Со многими приложениями установленные правила разрешения конфликтов работают хорошо, особенно аддитивное правило типа: "Изменить значение на ту же самую величину".Предположим, на складе есть 50 единиц детали 37В и мы выдаем 20 из них. При этом мы распространяем изменение, которое гласит, что для детали 37В количество сначала было равно 50, а теперь 30. Если где-то на другой машине обнаруживается, что эта деталь имеется в количестве 40 единиц, мы просто уменьшаем эту величину до 20, производя такое же относительное изменение, которое мы выполнили сначала. В конечном итоге изменение, в результате которого число деталей на удаленной машине сократилось с 50 до 40, будет распространено обратно на исходную машину, где тем же способом наша цифра будет уменьшена с 30 до 20. Все счастливы, если только у нас нет правила, согласно которому число деталей не может быть меньше 30!
Предупреждение
Мы все же должны предостеречь вас от использования времени в качестве базы для разрешения конфликтов. Почему? Потому что во всех средах, кроме распределенной вычислительной среды
Приоритет узлов также таит в себе опасность, если в сети больше двух узлов. Рассмотрим пример на рис. 12.6. При определенном стечении обстоятельств синхронность узлов нарушается, и узел С не согласуется с узлами А и В. Поскольку А определен как приоритетный узел, это предполагает, что данные узла С неверны.
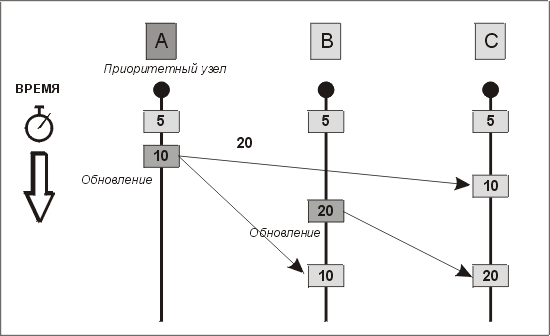
Рис. 12.6. Потенциальная проблема при разрешении конфликта по приоритету узлов
Существуют приложения (в их числе почти все финансовые программы), где единственный приемлемый путь разрешения конфликтов — их своевременное предотвращение. Один из методов, которым это можно сделать, носит невероятное название — посредничество в правах обновления.
При использовании этого подхода каждая строка имеет атрибут данных (столбец), определяющий, какому серверу разрешается обновлять этот столбец. Это право обычно подразумевается. Так, в системе обработки заказов
посредничество в правах обновления может осуществляться через столбец ORDER_STATUS, как показано в табл. 12.1.Таблица 12.1. Использование столбца статуса для определения прав обновления
|
Статус |
Смысл |
Права обновления |
|
IP CFD СFI |
Заказ еще не создан Готовится Готов к отправке Готов к фактурированию (отгружен) |
Сервер подразделения, отвечающий за обработку заказов Сервер подразделения, отвечающий за обработку заказов Сервер подразделения, отвечающий за отгрузку Сервер финансового отдела |
Этот метод работает хорошо при условии, что права обновления можно проталкивать, когда их нужно перенести с одного сервера на другой. Так, когда сервер, отвечающий за отгрузку, изменяет статус на
CFI, эта запись становится для этого сервера необновляемой. Более того, в течение как минимум нескольких секунд, а может быть, и нескольких часов (пока изменение не распространено на финансовый сервер) эта строка будет необновляемой для любого сервера. Анализ шести "-остей" позволяет определить, создает это проблему или нет. Данное решение хорошо подходит для приложения автоматизации деловых процедур, где часть работы переходит из отдела в отдел как результат заранее определенных транзакционных событий и лишь потом архивируется.Предположим теперь, что приложению нужно вытягивать права обновления, т.е. ему необходимо обновить запись, но сервер, на котором работает приложение, не имеет прав на обновление этой записи. В этом случае лучшая рекомендация, которую мы можем дать, — это имитировать структуру
Sybase Replication Server. Определите, у какого сервера нет прав на обновление, и произведите удаленное обновление на этом сервере с помощью двухфазной фиксации. В зависимости от степени вашего упрямства, вы можете либо просто изменить права обновления, подождать, пока они будут распространены и внести требуемые изменения, либо произвести полное изменение с помощью удаленного соединения.Мы предпочитаем второй метод, даже несмотря на то, что при этом только что внесенное изменение не будет сразу же отображаться в копии на том сервере, с которого оно было внесено. Если для вас это серьезная проблема, ее можно решить:
• с помощью дополнительных таблиц — они содержат значения первичных ключей строк, которые были удаленно обновлены.
• с помощью процедурных методов поиска — здесь с дополнительными таблицами сверяется первичный ключ каждой выбранной строки, а затем осуществляется переход на сервер, где было внесено изменение, для выборки данной версии как обновленной.
Решения этого типа очень сложны и подвержены ошибкам, которые трудно устранять и еще труднее объяснять пользователям. Если вы окажетесь на этом пути, то лучше поставьте под сомнение первоначальные решения о распределении данных. Конечно, это сделать гораздо легче, если эти решения принимал кто-то другой и если этот кто-то — не ваш непосредственный начальник или иное лицо, обладающее правом определять ваши перспективы в плане заработной платы!
Есть еще одна альтернатива — использовать транзакцию с двухфазной фиксацией для одновременного изменения прав обновления и в локальной копии таблицы, и в копии с текущими правами обновления. К сожалению, при этом одно и то же изменение приходится реплицировать в обоих направлениях, что может (в лучшем случае) вызвать путаницу.
Этот раздел будет неполным без упоминания о конфликтах вставки и конфликтах удаления. Последние большой проблемы не представляют: если при распространении удаления обнаруживается, что данная строка уже удалена в какой-то другой главной таблице, то это в принципе приемлемо. Все складывается так, как нам хотелось бы — в том плане, что данных там больше нет. Конфликт вставки — более серьезная вещь. Он возникает, когда две вставляемые строки имеют одно и то же значение первичного ключа. При проектировании приложений нужно стремиться предотвратить это, но если такая ситуация возникла, то о ней наверняка придется сообщить пользователям, чтобы они могли устранить проблему вручную, даже если две эти строки идентичны.
Синхронная симметричная репликация
Поддержка синхронной симметричной репликации на момент написания этой книги была новой возможностью. В настоящее время ни один из нас не имеет практического опыта работы с этим средством, и, кроме того, нам не удалось найти ни одного человека вне корпорации
Oracle, который бы им пользовался. Правда, мы участвовали в реализации проекта на базе версии 7.0 с аналогичными функциональными возможностями, и он успешно был сдан в эксплуатацию.В приложениях, где необходимо иметь несколько обновляемых копий одной таблицы в разных базах данных и где целостность данных имеет первостепенную важность, все копии нужно изменять в масштабах транзакции. Синхронная симметричная репликация позволяет достичь этой цели, хотя при значительном объеме
обновлений последствия из-за нагрузки на сеть и сервер могут быть довольно серьезными.Невзирая на это, синхронная симметричная репликация — все же наилучшее средство, позволяющее осуществлять эффективную выборку последних данных на любом из узлов. Она обеспечивает абсолютную надежность и более высокую готовность, чем использование одной главной таблицы,
потому что для запросов необходимо наличие только локальной копии. Производительность обработки запросов оптимальна, так как все запросы можно выполнять локально. Самый неприятный момент, связанный с этим методом, наступает, когда проектировщику приходится решать, по какому пути пойти в случае недоступности одной или нескольких баз данных и что делать, если недоступна часть сети.В первой ситуации (недоступна одна или несколько баз данных), как правило, необходимо продолжать работу с теми серверами, которые выжили, при условии, что можно будет вернуть отсутствующие базы данных в строй, когда их готовность восстановится.
Во второй ситуации (недоступна часть сети) необходимо установить ряд правил относительно того, каким подмножествам пользователей разрешается работать в случае отказов сети. Для обеспечения абсолютной надежности эти правила должны устанавливать, что если какое-то подмножество работает с разрешенным обновлением, то оно должно являться единственным работающим подмножеством. Более того, все остальные копии таблицы должны быть ресинхронизированы перед тем, как они станут доступны для использования. Сделать все это нелегко.
Комбинирование и сопоставление методов
Как мы уже говорили, необходимо рассмотреть каждую таблицу (или группу родственных таблиц) и выполнить для нее (или для них) фрагментационный анализ. Нужно решить, где в таблице должны быть расположены данные, чтобы оптимизировать и производительность, и готовность для тех пользователей, которым необходимо видеть эти данные и оперировать ими. Если в результате этого анализа принимается решение о том, что данные следует физически расположить на нескольких узлах, то нужно определить, как разбить или реплицировать данные между этими узлами. Сделав это, можно выбирать один из вариантов, которые мы предложили в этой главе (помня о шести "-остях").
Конечно, метод, который хорош для одной таблицы, может не быть оптимальным для другой. Поэтому вполне допустимо решение, в котором (обоснованно) комбинируются разные технологии. Комбинация обновляемых и необновляемых снимков плюс набор удаленных вызовов процедур — вполне жизнеспособное решение. Обычно существовало ограничение, запрещавшее смешивать снимки и реплицированные таблицы в одной схеме базы данных. Как нам кажется, в версии 7.3 этого ограничения уже нет. Тем не менее рекомендуем всем, кто думает над использованием комбинированных методов, тщательно проанализировать степень сложности поддержки такой конфигурации и задачу ее администрирования.
Кошмар администратора БД
Распределенные базы данных, особенно новейшие их разновидности, ставят перед администратором БД интересные задачи — еще до того, как начинают происходить сбои в сети! Создание схем — задача, конечно, не из тривиальных, хотя ее и существенно облегчает утилита
Replication Manager (часть Oracle Enterprise Manager в Oracle версии 7.3). Хотя Oracle Enterprise Manager поставляется со всеми платформами, он работает только под MS Windows NT.Без
Replication Manager настройка средств репликации требует от администратора БД выполнения ряда процедур, большинство из которых имеют очень длинные имена, например;DMBS_REPCAT_AUTH.GRANT_SURROGATE_REPCAT('REMOTESYS');
К тому же важное значение имеет порядок выполнения этих процедур. Более того, большинство CASE-продуктов не поддерживает определение распределенной схемы и генерируют DDL-операции, предполагающие, что все объекты будут определены в одной схеме. Для того чтобы добиться соответствия требованиям проектируемой распределенной системы, необходимо выполнить доводку вручную.
Примерные сценарии
Теперь, когда мы ознакомились с различными вариантами реализации распределенной базы данных, давайте рассмотрим, какие из них лучше использовать в определенных ситуациях. Для этого мы возьмем очень простые топологию сети и таблицу и с их помощью проиллюстрируем факторы, которые влияют на выбор технологии. Топология сети показана на рис. 12.7, а модель данных — на рис. 12.8. Для упрощения предположим, что на каждом узле работает один экземпляр базы данных, имя которого совпадает с именем узла.
Рис. 12.7. Простая топология сети
Рис. 12.8. Простая модель данных
Сценарий 1
Филиалы организации работают автономно и не испытывают необходимости получать данные от других филиалов. Каждый узел отвечает за свои локальные данные о служащих и отделах. Но при этом пользователю в Чикаго нужно выдавать периодические отчеты, в которых применяются данные обо всех служащих организации.
Этот сценарий прост, потому что программам составления сводных отчетов нужно лишь читать данные. В этом случае применяются удаленные запросы с каналами связи базы данных. В Чикаго необходимо создать два канала связи БД с Лондоном и Гонконгом, создать представление, которое является объединением трех таблиц служащих, и запустить программу составления отчетов, работающую с этим представлением. Конечно, если такие отчеты составляются не очень часто, можно вообще не использовать распределенную базу данных, периодически получать из Лондона и Гонконга дампы таблиц (например, путем экспорта) и загружать их в Чикаго. Как однажды сказал один администратор БД,
FedEx — самый лучший сетевой транспортный уровень, который мы смогли найти для пересылки больших файлов.Сценарий 2
Наша организация приняла на работу нового вице-президента по кадрам, который заметил, что если местный начальник отдела кадров отсутствует (вероятно, играет в гольф), то все изменения в таблицах приходится откладывать до его возвращения. Вице-президент поставил задачу обеспечить возможность обновления из Чикаго таблиц служащих и отделов в отсутствие местного начальника отдела кадров.
Этот сценарий также относительно прост, потому что обновление удаленных данных осуществляется отдельными транзакциями, в которых задействуется мало узлов. Используя канал связи БД, созданный для сценария 1, вице-президент может для удаленного сопровождения подключиться к удаленной системе, указав в конце строки соединения
@hong_kong или @london.Сценарий 3
Теперь наш вице-президент, реализуя свои властные полномочия, требует, чтобы обновления в столбец с заработной платой вносились только отделом кадров в Чикаго.
Здесь можно использовать то же решение, что и в сценарии 2, и просто управлять привилегиями обновления с помощью триггеров на таблицах. Однако предположим, что наш требовательный вице-президент хочет выполнять просмотр и обновление из одной экранной формы. В этом случае мы можем для просмотра данных использовать представление, описанное в сценарии 1, но, конечно, обновлять данные через это представление будет нельзя. Поэтому придется включить в представление псевдостолбец, содержащий сведения о местоположении строки, и с помощью этих данных и динамического
SQL генерировать соответствующее предложение UPDATE. Однако теперь мы обязаны выполнить двухфазную фиксацию.Теперь давайте рассмотрим новую модель данных, поскольку рассматриваемая до сих пор модель вряд ли может проиллюстрировать более сложное распределение данных по узлам. Вспомните, ранее мы говорили о том, что единственными причинами для распределения данных являются стремление сократить сетевую нагрузку или повысить готовность, а в этом примере вряд ли может идти речь о какой-либо из них. Наша новая модель показана на рис. 12.9.
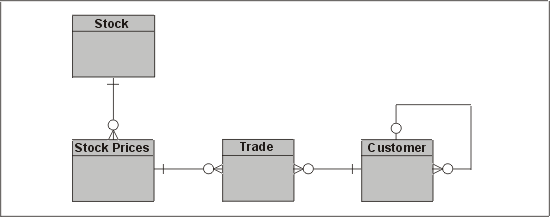
Рис. 12.9. Модель данных для более сложных распределенных сценариев
Сценарий 4
В каждой стране торгуют в основном товарами, которые находятся на местном складе. Существуют и международные компании, действующие во всех трех странах. Они должны иметь возможность вызывать любой локальный офис и получать информацию о своем глобальном портфеле заказов по состоянию на предыдущий вечер (по местному времени).
Давайте сначала рассмотрим сущность
Customer ("Покупатель"). У нее имеется рефлексивное отношение ("свиное ухо"), показывающее, что покупатель может иметь материнскую компанию (Company). Более того, эта компания может находиться в другой стране. Необходимо иметь возможность соединять локального покупателя с удаленным. Однако это не критичная по времени операция, и можно спокойно жить, не выполняя немедленного обновления для нелокальных покупателей. Поскольку данные о покупателях распределены по узлам и ярко выраженный главный узел отсутствует, мы, скорее всего, остановимся на мультимастер-таблице, которая реплицируется асинхронно. Единственный конфликт, который нужно здесь учесть, возникает, когда один из пользователей связывает компанию с уже удаленной родительской таблицей из другой страны. Однако эта ситуация маловероятна.В этом сценарии каждый узел интересует только локальная информация о запасах
(Stock) и ценах (Stock Price), поэтому для этих сущностей можно реализовать отдельные нераспределенные таблицы. С видами торговли (Trade), возможно, будет труднее, учитывая требование, что каждая страна должна предоставлять достаточно точную информацию, необходимую для оценки состояния всей международной корпорации. Лучший вариант для этих данных — реализовать сущность Trade как локальную таблицу и создать в таблице CUSTOMERS денормализованный столбец, содержащий текущее положение (он должен обновляться при каждой сделке). Вести этот столбец можно простым триггером. Если у покупателя есть материнская компания, должен срабатывать еще один триггер, обновляющий эту компанию. В этом случае конфликт более вероятен. Рекомендуем использовать аддитивный метод разрешения конфликтов.Сценарий 5
Этот сценарий похож на предыдущий, но здесь разрешена торговля товарами с иностранных складов. Поэтому при ведении торговли существенно важно знать курсы валют и использовать самую последнюю цену.
Таблицы
CUSTOMERS и TRADES могут оставаться в той же форме, что и в предыдущем примере, но поскольку цены товаров всегда должны быть полностью синхронизированы, у нас есть только один выбор: использовать для них синхронную симметричную репликацию. Однако если часть сети откажет, мы не сможем обновить цены ни в одной системе. Чтобы ослабить влияние этого фактора, придется либо покупать дополнительное оборудование, либо создать свою собственную форму синхронной симметричной репликации, которая при определенных управляемых условиях способна выдерживать системные отказы и откладывать синхронизацию. Еще один вариант — иметь всего одну копию данных, а деньги вложить в быстродействующую сеть!Использование распределенных баз данных для перехода в аварийный режим
Некоторые организации стремятся оправдать реализацию распределенной структуры лишь тем, что она отличается устойчивостью к отказам и обеспечивает возможность работы при выходе из строя сервера. При внимательном проектировании этого, конечно, добиться можно. Если же это главное требование, то более дешевым (и более простым) выходом может быть приобретение дополнительного оборудования.
Существует простое правило: если обязательным условием фиксации какой-либо транзакции является предварительное получение ответа от другой системы, то качество обслуживания в случае отказа сервера или соединения может снизиться. Ясно, что синхронные
RPC и синхронная симметричная репликация, как и двухфазная фиксация предполагают получение ответа от сервера. Снимки и асинхронная симметричная репликация в этом отношении менее чувствительны, потому что обновления в этом случае всегда откладываются и при отказе могут быть отложены еще на некоторое время. Однако если используются обновляемые снимки и главный узел не работает, то наступает момент, когда снимки начинают отличаться и вероятность конфликта повышается.Один из авторов видел план аварийного сценария, по которому какой-либо из удаленных серверов принимает на себя ответственность за центральный узел (на котором находится большинство главных таблиц) в случае продолжительного отказа последнего. Взяв на себя роль центрального сервера, он продолжает обслуживать локальных пользователей. Это еще нужно попробовать на практике, и автор продолжает относиться к этому несколько скептически, поскольку эти серверы находятся друг от друга на расстоянии многих километров. Как всегда, мы искренне надеемся, что эта авария никогда не произойдет.
Другие факторы, влияющие на проектирование
В этом разделе описывается еще несколько факторов, влияющих на проектирование распределенных баз данных
.Столбцы типа
LONGСтолбцы, определенные как
LONG, вызывают при проектировании распределенных баз данных ряд проблем. Таблицы, которые содержат длинные столбцы, не могут реплицироваться и участвовать в двухфазной фиксации. Снимки также не могут включать столбцы типа LONG. Если разобраться, то это имеет большой смысл: разве мы хотим, чтобы сеть была забита огромными растровыми изображениями или графическими объектами, которые реплицируются по узлам? Однако следует иметь в виду, что это ограничение может повлиять на структуру таблиц. Например, вы можете хранить BLOB-данные на внешнем сервере и разработать свою программу для "вытягивания" этих данных по требованию.Пакетные обновления
Если ожидается, что в системе будут иметь место периоды интенсивного обновления (например, к концу финансового года или квартала), то нужно учесть дополнительные затраты, связанные с распределенной архитектурой, и разработать план сведения их к минимуму. Например, если используются снимки и на главном узле каждый вечер запускается мощная пакетная программа, то разумно перед запуском этой программы отключить механизм снимков, а после прогона — выполнить полную их регенерацию. Это не так просто, как кажется, поскольку регенерация должна инициироваться с узлов-снимков. Как бы там
ни было, мы считаем, что периодически проводить согласование данных вручную полезно для их здоровья!Распределение данных: резюме
Как и в случае со многими другими технологиями, описанными в этой книге, главное при проектировании распределенных баз данных — хорошо знать, что нужно конкретному предприятию, а также иметь представление о том, что данная технология делает хорошо, а что хуже. Поэтому давайте подытожим наши рекомендации, данные в этой главе.
Программная поддержка распределенной работы в
Oracle впечатляет. Снимки обладают способностью поддерживать почти абсолютную актуальность копий справочных данных во всей сети, что должно уменьшить и трафик сообщений, и нагрузку на сервер (серверы). Синхронная репликация позволяет обеспечить актуальность нескольких копий одной таблицы в разных точках, причем без конфликтов, хотя и за счет производительности и с ухудшением готовности, потому что потеря любого компонента не дает выполнить обновления, как планировалось.Мы считаем, что использовать асинхронные RPC и асинхронную симметричную репликацию можно только в том случае, если структура способна избежать конфликта путем посредничества в правах обновления или справиться с последствиями того, что очевидно успешная операция позже классифицируется как неудачная
. Большинство проектировщиков и бизнес-аналитиков сталкиваются со значительными трудностями при применении этой концепции и поэтому не могут предложить эффективные решения.Там, где есть глобальная сеть, необходимо знать ее производительность (время отклика) и оценить число передаваемых сообщений. Тестирование приложения в локальной сети просто даст неправильный результат.
Самое главное, чтобы группа проектировщиков знала, какие уровни сервиса она должна обеспечить — это те шесть "-остей", о которых мы так много говорили в этой главе. Не имея этой информации, создать эффективно работающую распределенную базу данных трудно, если вообще возможно. Если вы видите, что можно удовлетворить эти требования, не прибегая к распределенному решению, так и поступайте. Помните, что причиной распределения данных является либо необходимость решить проблемы производительности, либо желание добиться требуемой готовности. Другими словами, покуда что-то не сломано, не пытайтесь его чинить!
Архитектура сетевых вычислений (NCA) корпорации Oracle
Пока
Oracle7 развивается, а мы ждем появления Oracle8, корпорация Oracle анонсировала новую архитектуру — Network Computing Architecture (NCA). В самом простом варианте архитектура сетевых вычислений включает компоненты трех типов:• средства управления клиентами и представлением данных;
• средства управления приложениями;
• средства управления данными.
Эти три компонента общаются друг с другом по "программной шине", которая представляет собой модернизированную версию сетевых транспортных сервисов
Oracle. Пользовательское содержимое каждого из этих компонентов поставляется в картриджах, которые можно программировать на самых разных языках — от традиционных С и C++ до новейших языков Java и JavaScript. Поддерживаются также Visual Basic и ActiveX от Microsoft.Основываясь на результатах своего первоначального знакомства с NCA, мы можем сказать, что эта новая архитектура не изменила ни одного из тех выводов, которые мы сделали относительно проектирования для
Oracle. Хотя уровни прозрачности, предлагаемые картриджами, и могут несколько упростить процесс исправления многих ошибок, допущенных при проектировании. Наиболее ясно новая архитектура демонстрирует только то, что Oracle готова явно поддерживать n-уровневые среды. Как только задача координации данных переносится с сервера данных на сервер приложений, мы, вероятно (может быть, даже обязательно), обнаружим, что с ней переходит и ответственность за координацию двухфазной фиксации, даже если все задействованные базы данных — БД Oracle. Однако картину несколько путает то, что уже появляются картриджи, которые можно вызывать из PL/SQL на сервере данных Oracle и которые могут общаться с внешними хранилищами данных, потенциально оставляя координацию на сервере данных.В NCA нет ничего, что сделает традиционные средства разработки на базе
SQL устаревшими, но намерение понятно — со временем новые средства разработки должны двигаться в направлении использования картриджей.* Действительно, средства УРП не поддерживают множественные соединения, однако отметим, что команда COPY в SQL*Plus реализуется именно с помощью множественных соединений.