Федеральное агентство по образованию
Томский государственный университет систем управления
и радиоэлектроники (ТУСУР)
УТВЕРЖДАЮ
Проректор по УР _____________М.Т.Решетников
_____________________2007 г.
Учебное пособие
по дисциплине «Проектирование программного обеспечения» магистерской программы
230109 «Технология разработки программных систем»
направления 230100 «Информатика и вычислительная техника».
Набор 2007 г. и последующих лет.
Институт инноватики
Профилирующая кафедра: Экономической математики информатики и статистики
Разработчик
Начальник отдела проектирования программных систем ООО «ЭлеТим»
А.А.Мирютов ___________________
1 Объектно-ориентированный подход к разработке ПО
1.1.2 Отношения между объектами
1.1.4 Отношения между классами
1.2.8 Преимущества объектной модели
1.3.1 Классическая категоризация
1.3.2 Концептуальная кластеризация
2 Паттерны проектирования классов и объектов
2.1 Механизмы повторного использования
2.3.6 Паттерн Information Expert
2.4.7 Паттерн Chain Of Responsibility
2.4.10 Паттерн Don’t Talk To Strangers
2.4.12 Паттерн Pure Fabrication
Обращение к базе данных, обмен сообщениями, управление транзакциями и т.д.
3.2.2 Паттерн Separated Interface
3.3 Паттерны организация бизнес-логики
3.3.1 Паттерн Transaction Script
3.4 Паттерны организации источников данных
3.4.1 Объектные модели и реляционные базы данных
3.4.3 Паттерн Table Data Gateway
3.4.4 Паттерн Row Data Gateway
3.4.9 Взаимное отображение объектов и реляционных структур
3.4.10 Соединение с базой данных
3.5 Паттерны представления данных в WEB
3.5.1 Паттерн Model-View-Controller
3.5.3 Паттерн Front Controller
3.5.5 Паттерн Transform View..
Список используемой (рекомендуемой) литературы
Процесс разработки больших программных систем чрезвычайно сложен и непредсказуем. Программные проекты часто прерываются, выходят за рамки сроков и бюджета или приводят к некачественным результатам, отделяя технологию программирования от установившихся инженерных дисциплин. Озадачивающие на первый взгляд недостатки программной "инженерии" легко объясняются тем фактом, что разработка программного обеспечения является ремеслом, а не инженерной дисциплиной. Чтобы стать наукой, разработка ПО должна подвергнуться сдвигу парадигмы от метода проб и ошибок к системе основных принципов. Хотя, естественно, некоторые принципы существуют благодаря таким выдающимся личностям как Кнут, Дейкстра, Вирт.… Но эти люди сформулировали лишь некоторые локальные правила. Они сформулировали алгоритмы решения тех или иных математических задач. К сожалению, в реальном мире разработчику очень часто приходится иметь дело далеко не с математикой, физикой, химией и другими точными науками. Разработчику приходится иметь дело с процессами, которые сформированы не законами физики, а человеческими отношениями. И если физик, с чем бы он не работал, имеет твердое убеждение, что можно найти общие принципы, будь то кварки или теория поля, у разработчика ПО нет такой утешительной веры.
Кони Бюрер, один из ведущих специалистов компании IBM, сравнивает сегодняшнее положение разработчика ПО с положением архитектора средневекового европейского готического собора. Эти люди, ничего не знали о законах физики, но тем не менее возводили величайшие сооружения. Они были классными мастерами. Но они не были не инженерами, не учеными. Возможно, через много лет разработчики будут создавать свои программы, имея строгую систему определений и теорем. Сегодня же приходится довольствоваться только некоторыми оптимальными методиками, полученными на основании опыта всего лишь одного поколения классных программистов. Причем эти методики отнюдь не гарантируют 100% правильности создаваемых программ. Часто приходится действовать методом проб и ошибок.
Это объясняет, почему двумя наиболее явными проблемами неудачных программных проектов являются переделка программ и обнаружение негодности проекта на его поздних стадиях. Программист проектирует архитектуру на ранних стадиях разработки ПО, но не имеет возможности сразу же оценить ее качество. У программиста отсутствуют основные принципы для доказательства адекватности проекта. Тестирование программного обеспечения постепенно выявляет все дефекты архитектуры, но только на поздних стадиях разработки, когда исправление ошибок становится дорогим и разрушительным для проекта.
Тем не менее, применение оптимальных методик и четко выстроенный процесс управления разработкой резко понижает вероятность провала проекта. Некоторые из таких методик и будут предметом рассмотрения на наших лекциях.
1 Объектно-ориентированный подход к разработке ПО
Под объектно-ориентированным программированием (object-oriented programming, OOP) следует понимать методологию реализации, при которой программа организуется, как совокупность сотрудничающих объектов, каждый из которых является экземпляром какого-либо класса, а классы образуют иерархию наследования. При этом классы обычно статичны, а объекты очень динамичны, что поощряется динамическим связыванием и полиморфизмом (пока не обращайте внимания на то, что большая часть слов этого определения Вам не понятна). Несмотря на то, под OOP следует понимать только то, что было написано выше, под ним часто понимают объектно-ориентированный подход к созданию ПО. Последний наравне с OOP включает в себя объектно-ориентированный анализ (object-oriented analisys, OOA) н объектно-ориентированное проектирование (object-oriented design). Все это понятия тесно связанны с понятиями объекта, класса и объектной модели.
1.1 Понятия объекта и класса
1.1.1 Природа объектов
Объект - нечто, чем можно оперировать. Объект имеет состояние, поведение и идентичность. Структура и поведение сходных объектов определены в общем для них классе. Термины "экземпляр" и "объект" взаимозаменяемы.
Класс - множество объектов с общей структурой и поведением.
Всем вам известны такие понятия как тип и переменная. Исходя из этого, можно сказать, что класс это то же самое, что и тип, а объект – то же самое что и переменная. Вы привыкли, что тип int означает целое число, float – число с плавающей запятой и т.д. Теперь попытаемся несколько расширить этот набор. Представим, что существует такой тип как человек. Переменной в этом случае будет конкретный человек, например я, или любой из Вас. Точно так же мы можем ввести класс стол, объектами которого будут, этот стол и тот стол.
Теперь более подробно разберемся с определением объекта. А именно с понятиями состояния, поведения и идентичности.
Состояние
Состояние объекта характеризуется перечнем (обычно статическим) всех свойств данного объекта и текущими (обычно динамическими) значениями каждого из этих свойств. В качестве примера можно рассмотреть автомат, торгующий кофе. Одно из свойств – количество монет, хранящихся в нем. Тот факт, что это свойство всегда есть, определяет статику. Значение этого свойства определяет динамику.
Поведение
Поведение - это то, как объект действует и реагирует; поведение выражается в терминах состояния объекта и передачи сообщений. Иными словами, поведение объекта - это его наблюдаемая и проверяемая извне деятельность.
Операцией называется определенное воздействие одного объекта на другой с целью вызвать соответствующую реакцию.
C одной стороны, поведение объекта изменяет его состояние. С другой – поведение зависит от состояния. Действительно, рассмотрим поведение автомата. С одной стороны, одна из частей его поведения – принять монету. Эта часть поведения влияет на часть состояния–количество монет. С другой – именно часть состояния - количество монет определяет в некоторой степени поведение автомата. А именно, наливать ли кофе в стакан или нет. Таким образом можно прийти к выводу, что состояние объекта представляет суммарный результат его поведения.
Поведение объекта строится из его операций. Существует три вида операций
· Модификатор - операция, которая изменяет состояние объекта
· Селектор - операция, считывающая состояние объекта, но не меняющая состояния
· Итератор - операция, позволяющая организовать доступ ко всем частям объекта в строго определенной последовательности
Идентичность
Идентичность - это такое свойство объекта или такой набор свойств, который отличает его от всех других объектов.Например, когда мы программируем, мы можем однозначно определять объект по его имени. Объект, хранящийся в базе данных, мы можем определять по набору свойств, определяющих первичный ключ.
1.1.2 Отношения между объектами
Сами по себе объекты не представляют никакого интереса: только в процессе взаимодействия объектов реализуется система. По выражению Ингалса: "Вместо процессора, беззастенчиво перемалывающего структуры данных, мы получаем сообщество хорошо воспитанных объектов, которые вежливо просят друг друга об услугах". Самолет, по определению, "совокупность элементов, каждый из которых по своей природе стремится упасть на землю, но за счет совместных непрерывных усилий преодолевающих эту тенденцию". Он летит только благодаря согласованным усилиям своих компонентов.
Отношения двух любых объектов основываются на предположениях, которыми один обладает относительно другого: об операциях, которые можно выполнять, и об ожидаемом поведении. Особый интерес для объектно-ориентированного анализа и проектирования представляют два типа иерархических соотношений объектов: связь и агрегация.
Отношение типа “связь”
Мы заимствуем понятие связи у Рамбо (Rumbaugh), который определяет его как "физическое или концептуальное соединение между объектами". Объект сотрудничает с другими объектами через связи, соединяющие его с ними. Другими словами, связь - это специфическое сопоставление, через которое клиент запрашивает услугу у объекта-сервера или через которое один объект находит путь к другому.
Участвуя в связи, объект может выполнять одну из следующих трех ролей:
- Актер. Actor - это деятель, исполнитель. Объект может воздействовать на другие объекты, но сам никогда не подвергается воздействию других объектов; в определенном смысле это соответствует понятию активный объект.
- Сервер. Объект может только подвергаться воздействию со стороны других объектов, но он никогда не выступает в роли воздействующего объекта.
- Агент. Такой объект может выступать как в активной, так и в пассивной роли; как правило, объект-агент создается для выполнения операций в интересах какого-либо объекта-актера или агента.
Пример отношения типа “связь” – отношения между объектами “пилот” и “диспетчер”. Пилот может запрашивать у диспетчера разные данные о курсе, высоте, эшелоне, угле глиссады и т.д.
В заключении можно сказать, что если между двумя объектами существуют клиент серверные отношения, то они, чаще всего, находятся в отношении типа связь.
Отношение типа “агрегация”
В то время, как связи обозначают равноправные или "клиент серверные" отношения между объектами, агрегация описывает отношения целого и части, приводящие к соответствующей иерархии объектов, причем, идя от целого (агрегата), мы можем придти к его частям (атрибутам). В этом смысле агрегация - специализированный частный случай ассоциации.
Агрегация может означать физическое вхождение одного объекта в другой, но не обязательно. Самолет состоит из крыльев, двигателей, шасси и прочих частей. С другой стороны, отношения акционера с его акциями - это агрегация, которая не предусматривает физического включения. Акционер монопольно владеет своими акциями, но они в него не входят физически. Это, несомненно, отношение агрегации, но скорее концептуальное, чем физическое по своей природе.
Выбирая одно из двух - связь или агрегацию - надо иметь в виду следующее. Агрегация иногда предпочтительнее, поскольку позволяет скрыть части в целом. Иногда наоборот предпочтительнее связи, поскольку они слабее и менее ограничительны. Принимая решение, надо взвесить все.
Объект, являющийся атрибутом другого объекта (агрегата), имеет связь со своим агрегатом. Через эту связь агрегат может посылать ему сообщения.
Большинство объектных нотаций вводит понятие диаграммы объектов. Диаграмма объектов - часть системы обозначений объектно-ориентированного проектирования; используется, чтобы наглядно показать объекты и отношения между ними в логическом проекте системы. Может отражать всю объектную структуру или часть ее; обычно иллюстрирует смысл механизмов в логическом проекте. Отдельная диаграмма объектов - моментальный снимок из жизни системы. Часто диаграмму объектов называют диаграммой сотрудничества (collaboration diagram). Основные обозначения на этой диаграмме следующие:

Рисунок 1.1 Обозначение объекта
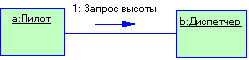
Рисунок 1.2 Отношение типа "связь"
Помимо диаграмм сотрудничества, существует еще один вид диаграмм объектов – диаграммы последовательностей (sequence diagram). Диаграммы последовательностей служат тем же целям, что и диаграммы сотрудничества.
Отношение типа “агрегация” между объектами не имеет специального обозначение. Дело в том, что отношению «агрегация» между объектами, соответствует отношение «агрегация» между их классами. Для агрегации между классами существует специальное обозначение, но о нем поговорим чуть позже.
1.1.3 Природа классов
Понятия класса и объекта настолько тесно связаны, что невозможно говорить об объекте безотносительно к его классу. Однако существует важное различие этих двух понятий. В то время как объект обозначает конкретную сущность, определенную во времени и в пространстве, класс определяет лишь абстракцию существенного в объекте. Таким образом, можно говорить о классе "Млекопитающие", который включает характеристики, общие для всех млекопитающих. Для указания на конкретного представителя млекопитающих необходимо сказать "это - млекопитающее" или "то - млекопитающее".
Напомню, что класс представляет набор объектов, которые обладают общей структурой и одинаковым поведением.
Любой конкретный объект является просто экземпляром класса. Что же не является классом? Объект не является классом, хотя в дальнейшем мы увидим, что класс может быть объектом. Объекты, не связанные общностью структуры и поведения, нельзя объединить в класс, так как по определению они не связаны между собой ничем, кроме того, что все они объекты.
Важно отметить, что классы, как их понимают в большинстве существующих языков программирования, необходимы, но не достаточны для декомпозиции сложных систем. Некоторые абстракции так сложны, что не могут быть выражены в терминах простого описания класса. Например, на достаточно высоком уровне абстракции графический интерфейс пользователя, база данных или система учета как целое, это явные объекты, но не экземпляры классы Лучше считать их некими совокупностями сотрудничающих классов. Страуструп называет такие кластеры компонентами. Мы будем использовать либо это понятие, либо равносильное ему понятие категории классов.
1.1.4 Отношения между классами
Всего между классами существует 6 видов отношений: ассоциация, наследование, агрегация, использование, инстанцирование и метакласс.
Прежде чем мы рассмотрим перечисленные отношения подробно, введем несколько определений и обозначений. И так, классы и их отношения чаще всего представляются на диаграмме классов. Диаграмма классов - часть системы обозначений объектно-ориентированного проектирования; используется, чтобы наглядно показать классы и их взаимоотношения в логическом проекте системы. Может представлять всю структуру классов или ее часть. На диаграммах классов класс изображается следующим образом:
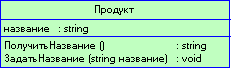
Рисунок 1.3 Обозначение класса
Теперь рассмотрим каждое отношение более подробно.
Ассоциация
Начнем с примера. Желая автоматизировать розничную торговую точку, мы обнаруживаем две абстракции - товары и продажи. На рис. 1.4 показана ассоциация, которую мы при этом усматриваем. Класс Продукт - это то, что мы продали в некоторой сделке, а класс Продажа - сама сделка, в которой продано несколько товаров. Надо полагать, ассоциация работает в обе стороны: задавшись товаром, можно выйти на сделку, в которой он был продан, а пойдя от сделки, найти, что было продано.

Рисунок 1.4 Обозначение ассоциации
Как показывает этот пример, ассоциация - смысловая связь. По умолчанию, она не имеет направления (если не оговорено противное, ассоциация, как в данном примере, подразумевает двухстороннюю связь) и не объясняет, как классы общаются друг с другом (мы можем только отметить семантическую зависимость, указав, какие роли классы играют друг для друга). Однако именно это нам требуется на ранней стадии анализа. Если же возникает необходимость явно указать направление ассоциации, это можно сделать, нарисовав стрелку.
Итак, мы фиксируем участников, их роли и (как будет сказано далее) мощность отношения.
Мощность. В предыдущем примере мы имели ассоциацию "один ко многим". Тем самым мы обозначили ее мощность (то есть, грубо говоря, количество участников). На практике важно различать три случая мощности ассоциации: "один-к-одному", "один-ко-многим" и "многие-ко-многим".
Наследование
Наследование это отношение между классами, при котором класс использует структуру или поведение другого (одиночное наследование) или других (множественное наследование) классов. Наследование вводит иерархию "общее/частное" в которой подкласс наследует от одного или нескольких более общих суперклассов. Подклассы обычно дополняют или переопределяют унаследованную структуру и поведение.
На диаграммах классов наследование обозначается следующим образом:
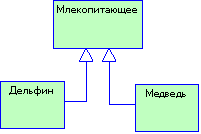
Рисунок 1.5 Обозначение наследования
Дочерние классы обычно расширяют структуру и/или поведение родительского класса. Дочерний класс часто называют подклассом, родительский – суперклассом. Естественно, иерархия наследования может быть выстроена и более чем из двух уровней, хотя, больше семи уровней используется очень редко. Это связано с тем, что человеку сложно воспринять иерархию, состоящую более чем из семи уровней. Самый верхний в иерархии наследования класс называют базовым.
Чаще всего, в реальных системах мы создаем объекты только тех классов, которые находятся на самых низких уровнях иерархии наследования. Это связано с тем, что классы на более высоких уровнях чаще всего содержат только лишь интерфейс некоторой абстракции, но не его реализация. Классы, содержащие только интерфейс, называются абстрактными. Класс является абстрактным даже в том случае, если у него не реализована хотя бы одна из объявленных операций. Классы, в которых реализованы все объявленные операции, называются конкретными. Мы можем создавать объекты только конкретных классов.
У класса обычно бывает два вида клиентов:
- экземпляры;
- подклассы.
Часто полезно иметь для них разные интерфейсы. В частности, мы хотим показать только внешне видимое поведение для клиентов-экземпляров, но нам нужно открыть служебные функции и представления клиентам-подклассам. Этим объясняется наличие открытой, защищенной и закрытой частей описания класса в языке C++: разработчик может четко разделить, какие элементы класса доступны.
Есть серьезные противоречия между потребностями наследования и инкапсуляции. В значительной мере наследование открывает наследующему классу некоторые секреты. На практике, чтобы понять, как работает какой-то класс, часто надо изучить все его суперклассы в их внутренних деталях.
Множественное наследование
Мы рассмотрели вопросы, связанные с одиночным наследованием, то есть, когда подкласс имеет ровно один суперкласс. Однако одиночное наследование при всей своей полезности часто заставляет программиста выбирать между двумя равно привлекательными классами. Это ограничивает возможность повторного использования определенных классов и заставляет дублировать уже имеющиеся коды. Например, нельзя унаследовать графический элемент, который был бы одновременно окружностью и картинкой; приходится наследовать что-то одно и добавлять необходимое от второго.
Множественное наследование прямо поддерживается в языках C++ и CLOS, а также, до некоторой степени, в Smalltalk. Необходимость множественного наследования в OOP остается предметом горячих споров. По нашему опыту, множественное наследование - как парашют: как правило, он не нужен, но, когда вдруг он понадобится, будет жаль, если его не окажется под рукой.
Представьте себе, что нам надо организовать учет различных видов материального и нематериального имущества - банковских счетов, недвижимости, акций и облигаций. Банковские счета бывают текущие и сберегательные. Акции и облигации можно отнести к ценным бумагам, управление ими совершенно отлично от банковских счетов, но и счета и ценные бумаги - это разновидности имущества.
Однако есть много других полезных классификаций тех же видов имущества. В каком-то контексте может потребоваться отличать то, что можно застраховать (недвижимость и, до некоторой степени, сберегательные вклады). Другой аспект - способность имущества приносить дивиденды; это общее свойство банковских счетов и ценных бумаг.
Очевидно, одиночное наследование в данном случае не отражает реальности, так что придется прибегнуть к множественному. В действительности, это - "лакмусовая бумажка" для множественного наследования. Если мы составим структуру классов, в которой конечные классы (листья) могут быть сгруппированы в множества по разным ортогональным признакам (как в нашем примере, где такими признаками были способность приносить дивиденды и возможность страховки) и эти множества перекрываются, то это служит признаком невозможности обойтись одной структурой наследования, в которой бы существовали какие-то промежуточные классы с нужным поведением. Мы можем исправить ситуацию, используя множественное наследование, чтобы соединить два нужных поведения там, где это необходимо. В этом случае класс “Ценные бумаги” будет наследовать от классов “Источник дивидендов” и “Имущество”
Агрегация
Агрегация между классами имеет схожую семантику с агрегацией между объектами. Агрегация между классами означает, что экземпляры одного класса включают экземпляры другого класса. Так же как и у объектов, агрегация между класса может быть логической или физической (композиция). Рассмотрим примеры.

Рисунок 1.6 Логическая агрегация

Рисунок 1.7. Физическая агрегация (композиция)
Инстанцирование
Введем определение обобщенного класса. Под обобщенным классом будем понимать класс, служащий шаблоном для создания других классов: шаблон параметризуется другими классами, объектами и/или операциями. Обобщенный класс до создания объектов должен быть инстанцирован. Обобщенные классы используются как контейнерные классы. Термины "обобщенный класс" и "параметризованный класс" взаимозаменяемы.
Инстанцирование - подстановка параметров шаблона обобщенного или параметризованного класса; в результате создается конкретный класс, который может иметь экземпляры.
Метакласс
Как было сказано, любой объект является экземпляром какого-либо класса. Что будет, если мы попробуем и с самими классами обращаться как с объектами? Для этого нам надо ответить на вопрос, что же такое класс класса? Ответ - это метакласс. Иными словами, метакласс - это класс, экземпляры которого суть классы. Метаклассы венчают объектную модель в чисто объектно-ориентированных языках. Соответственно, они есть в Smalltalk и CLOS, но не в C++.
1.2 Объектная модель
Объектно-ориентированный подход принципиально отличаются от традиционных подходов структурного проектирования: здесь нужно по-другому представлять себе процесс декомпозиции, а архитектура получающегося программного продукта в значительной степени выходит за рамки представлений, традиционных для структурного программирования. Это связанно с тем, что программы, созданные, при помощи традиционных подходов оперируют в основном глаголами (функциями). Мы пытаемся запрограммировать задачу как последовательность функций и алгоритмов, проведя, для этого, так называемую алгоритмическую декомпозирую. При объектном подходе проводится объектная декомпозиция, и программа представляется уже как набор взаимодействующих друг с другом объектов.
Объектно-ориентированная технология основывается на так называемой объектной модели. Основными ее принципами являются: абстрагирование, инкапсуляция, модульность, иерархичность, типизация, параллелизм и сохраняемость. Каждый из этих принципов сам по себе не нов, но в объектной модели они впервые применены в совокупности. Первые четыре принципа являются обязательными в том смысле, что без них модель не будет считаться объектной. Последние три дополнительными. Рассмотрим подробно все принципы.
1.2.1 Абстрагирование
Абстрагирование выделяет существенные характеристики некоторого объекта, отличающие его от всех других видов объектов и, таким образом, четко определяет его концептуальные границы с точки зрения наблюдателя. Фраза “с точки зрения наблюдателя” важна, так как разные люди могут иметь совершенно разные взгляды на вещь или проблему.
Абстрагирование концентрирует внимание на внешних особенностях объекта и позволяет отделить самые существенные особенности поведения от несущественных. Абельсон и Суссман назвали такое разделение смысла и реализации барьером абстракции, который основывается на принципе минимизации связей, когда интерфейс объекта содержит только существенные аспекты поведения и ничего больше. Существует еще один дополнительный принцип, называемый принципом наименьшего удивления, согласно которому абстракция должна охватывать все поведение объекта, но не больше и не меньше, и не привносить сюрпризов или побочных эффектов, лежащих вне ее сферы применимости.
Выбор правильного набора абстракций для заданной предметной области представляет собой главную задачу объектно-ориентированного проектирования. Существует 4 вида абстракций (перечислены по мере уменьшения полезности).
- Абстракция сущности. Объект представляет собой полезную модель некой сущности в предметной области.
- Абстракция поведения. Объект состоит из обобщенного множества операций.
- Абстракция виртуальной машины. Объект группирует операции, которые либо вместе используются более высоким уровнем управления, либо сами используют некоторый набор операций более низкого уровня.
- Произвольна абстракция. Объект включает в себя набор операций, не имеющих друг с другом ничего общего.
Контрактная модель программирования
Очень важным для абстрагирования понятием является понятие контрактной модели программирования. Введем несколько определений.
Клиентом называется любой объект, использующий ресурсы другого объекта (называемого сервером). Мы будем характеризовать поведение объекта услугами, которые он оказывает другим объектам, и операциями, которые он выполняет над другими объектами. Такой подход концентрирует внимание на внешних проявлениях объекта и приводит к идее, которую Мейер назвал контрактной моделью программирования: внешнее проявление объекта рассматривается с точки зрения его контракта с другими объектами, в соответствии с этим должно быть выполнено и его внутреннее устройство (часто во взаимодействии с другими объектами). Контракт фиксирует все обязательства, которые объект-сервер имеет перед объектом-клиентом. Другими словами, этот контракт определяет ответственность объекта - то поведение, за которое он отвечает.
Каждая операция, предусмотренная этим контрактом, однозначно определяется ее формальными параметрами и типом возвращаемого значения. Полный набор операций, которые клиент может осуществлять над другим объектом, вместе с правильным порядком, в котором эти операции вызываются, называется протоколом. Протокол отражает все возможные способы, которыми объект может действовать или подвергаться воздействию, полностью определяя тем самым внешнее.
Центральной идеей в контрактной модели программирования является понятие инварианта. Инвариант - это некоторое логическое условие, значение которого (истина или ложь) должно сохраняться. Для каждой операции объекта можно задать предусловия (инварианты предполагаемые операцией) и постусловия (инварианты, которым удовлетворяет операция). Изменение инварианта нарушает контракт, связанный с абстракцией. В частности, если нарушено предусловие, то клиент не соблюдает свои обязательства и сервер не может выполнить свою задачу правильно. Если же нарушено постусловие, то свои обязательства нарушил сервер, и клиент не может более ему доверять. В случае нарушения какого-либо условия возбуждается исключительная ситуация. Многие языки программирования имеют средства для работы с исключительными ситуациями: объекты могут возбуждать исключения, чтобы запретить дальнейшую обработку и предупредить о проблеме другие объекты, которые в свою очередь могут принять на себя перехват исключения и справиться с проблемой.
1.2.2 Инкапсуляция
Инкапсуляция - это процесс отделения друг от друга элементов абстракции, определяющих ее устройство и поведение; инкапсуляция служит для того, чтобы изолировать контрактные обязательства абстракции от их реализации.
Абстракция и инкапсуляция дополняют друг друга: абстрагирование направлено на наблюдаемое поведение объекта, а инкапсуляция занимается внутренним устройством. Чаще всего инкапсуляция выполняется посредством скрытия информации, то есть маскировкой всех внутренних деталей, не влияющих на внешнее поведение объекта. Обычно скрываются и внутренняя структура объекта и реализация его методов. Необходима инкапсуляция для того, что бы та модель которую мы выражаем средствами языков моделирования и программирования была адекватной.
Рассмотрим пример растения. У растения существует такой атрибут как размер. Что может повлиять на размер? На размер могут повлиять количество солнечного света, количество воды, количество навоза наконец. Вы воздействуете на размер меняя количество того или другого из перечисленных параметров. Если Вы будете поливать цветок он будет расти. При этом, Вы не можете в реальном мире одним усилием мысли заставить цветок вырасти на два метра. Это нереально, так как только сам цветок представляет себе механизмы по которым меняется его размер. И было бы естественно, что бы и в программной модели цветка не было возможности менять размер цветка явно. Поэтому, мы спрячем атрибут – размер цветка в реализации, а в интерфейсе модели выставим в метод «ВоздействоватьНаРост» с такими параметрами как количество света, воды и навоза.
Скрытие информации - понятие относительное: то, что спрятано на одном уровне абстракции, обнаруживается на другом уровне. Забраться внутрь объектов можно; правда, обычно требуется, чтобы разработчик класса-сервера об этом специально позаботился, а разработчики классов-клиентов не поленились в этом разобраться. Инкапсуляция не спасает от глупости; она, как отметил Страуструп, "защищает от ошибок, но не от жульничества" Разумеется, язык программирования тут вообще ни при чем; разве что операционная система может ограничить доступ к файлам, в которых описаны реализации классов. На практике же иногда просто необходимо ознакомиться с реализацией класса, чтобы понять его назначение, особенно, если нет внешней документации.
1.2.3 Модульность
Модульность - это свойство системы, которая была разложена на внутренне связные, но слабо связанные между собой модули.
По мнению Майерса "Разделение программы на модули до некоторой степени позволяет уменьшить ее сложность... Однако гораздо важнее тот факт, что внутри модульной программы создаются множества хорошо определенных и документированных интерфейсов. Эти интерфейсы неоценимы для исчерпывающего понимания программы в целом". В некоторых языках программирования, например в Smalltalk, модулей нет, и классы составляют единственную физическую основу декомпозиции. В других языках, включая Object Pascal, C++, Java модуль - это самостоятельная языковая конструкция. В этих языках классы и объекты составляют логическую структуру системы, они помещаются в модули, образующие физическую структуру системы. Это свойство становится особенно полезным, когда система состоит из многих сотен классов.
В большинстве языков, поддерживающих принцип модульности как самостоятельную концепцию, интерфейс модуля отделен от его реализации. Таким образом, модульность и инкапсуляция ходят рука об руку. В разных языках программирования модульность поддерживается по-разному. Например, в C++ модулями являются раздельно компилируемые файлы. Для C/C++ традиционным является помещение интерфейсной части модулей в отдельные файлы с расширением .h (так называемые файлы-заголовки). Реализация, то есть текст модуля, хранится в файлах с расширением .с (в программах на C++ часто используются расширения ср и .срр). Связь между файлами объявляется директивой макропроцессора #include. Такой подход строится исключительно на соглашении и не является строгим требованием самого языка. В языке Object Pascal принцип модульности формализован несколько строже. В этом языке определен особый синтаксис для интерфейсной части и реализации модуля (unit). В Java существуют так называемые package. Каждый package содержит себе несколько классов сгруппированных по некоторому логическому признаку.
Модульность, кроме облегчения поиска нужного описания, позволяет значительно ускорить процесс сборки проекта (естественно, для компиляторов поддерживающих раздельную компиляцию). Рассмотрим пример.
Естественно, все это накладывает очень жесткие ограничение на устойчивость интерфейсов, но задача формирования устойчивых интерфейсов задача проектирования вообще.
1.2.4 Иерархия
Абстракция - вещь полезная, но всегда, кроме самых простых ситуаций, число абстракций в системе намного превышает наши умственные возможности. Инкапсуляция позволяет в какой-то степени устранить это препятствие, убрав из поля зрения внутреннее содержание абстракций. Модульность также упрощает задачу, объединяя логически связанные абстракции в группы. Но этого оказывается недостаточно.
Значительное упрощение в понимании сложных задач достигается за счет образования из абстракций иерархической структуры. Определим иерархию следующим образом:
Иерархия - это упорядочение абстракций, расположение их по уровням.
Основными видами иерархических структур применительно к сложным системам являются структура классов (иерархия "is-a") и структура объектов (иерархия "part of").
1.2.4.1 Иерархия "is-a"
Важным элементом объектно-ориентированных систем и основным видом иерархии "is-a" является упоминавшаяся выше концепция наследования. Наследование означает такое отношение между классами (отношение родитель/потомок), когда один класс заимствует структурную или функциональную часть одного или нескольких других классов (соответственно, одиночное и множественное наследование). Иными словами, наследование создает такую иерархию абстракций, в которой подклассы наследуют строение от одного или нескольких суперклассов. Часто подкласс достраивает или переписывает компоненты вышестоящего класса.
Семантически, наследование описывает отношение типа "is-a". Например, медведь есть млекопитающее, дом есть недвижимость и "быстрая сортировка" есть сортирующий алгоритм. Таким образом, наследование порождает иерархию "обобщение-специализация", в которой подкласс представляет собой специализированный частный случай своего суперкласса. "Лакмусовая бумажка" наследования - обратная проверка; так, если B не есть A, то B не стоит производить от A. Помимо одиночного наследования, примеры которого мы только что привели, существует еще один вариант наследования – множественное. В этом случае, некоторый класс допускает одновременно два обощения, например, яблоко можно рассматривать как фрукт и как цветок. То же самое можно сказать и о вишне. Еще один пример: рация является одновременно и приемником, и передатчиком.
Множественное наследование - вещь нехитрая, но оно осложняет реализацию языков программирования. Есть две проблемы - конфликты имен между различными суперклассами и повторное наследование. Первая проблема возникает тогда, когда в двух или большем числе суперклассов определено поле или операция с одинаковым именем. В C++ этот вид конфликта должен быть явно разрешен вручную, а в Smalltalk берется то, которое встречается первым. Вторая проблемы это повторное наследование. Повторное наследование, это когда класс наследует двум классам, а они порознь наследуют одному и тому же четвертому. Получается ромбическая структура наследования и надо решить, должен ли самый нижний класс получить одну или две отдельные копии самого верхнего класса? В некоторых языках повторное наследование запрещено, в других конфликт решается "волевым порядком", а в C++ это оставляется на усмотрение программиста.
Множественным наследованием часто злоупотребляют. Например, сладкая вата - это частный случай сладости, но никак не ваты. Применяйте ту же "лакмусовую бумажку": если B не есть A, то ему не стоит наследовать от A. Часто плохо сформированные структуры множественного наследования могут быть сведены к единственному суперклассу плюс агрегация других классов подклассом.
1.2.4.2 Иерархия "part of"
Если иерархия "is а" определяет отношение "обобщение/специализация", то отношение "part of" (часть-целое) вводит иерархию агрегации. Например человек-рука, огород-ростения.
Агрегация есть во всех языках, использующих структуры или записи, состоящие из разнотипных данных. Но в объектно-ориентированном программировании она обретает новую мощь: агрегация позволяет физически сгруппировать логически связанные структуры, а наследование с легкостью копирует эти общие группы в различные абстракции.
1.2.5 Типизация
Понятие типа взято из теории абстрактных типов данных. Дойч определяет тип, как "точную характеристику свойств, включая структуру и поведение, относящуюся к некоторой совокупности объектов". Для наших целей достаточно считать, что термины тип и класс взаимозаменяемы. (На самом деле тип и класс не вполне одно и то же; в некоторых языках их различают. Например, ранние версии языка Trellis/Owl разрешали объекту иметь и класс, и тип. Даже в Smalltalk объекты классов SmallInteger, LargeNegativeInteger, LargePositiveInteger относятся к одному типу Integer, хотя и к разным классам . Большинству смертных различать типы и классы просто противно и бесполезно. Достаточно сказать, что класс реализует понятие типа).
Типизация - это способ защититься от использования объектов одного класса вместо другого (сильная типизация), или по крайней мере управлять таким использованием (слабая типизация).
Типизация заставляет нас выражать наши абстракции так, чтобы язык программирования, используемый в реализации, поддерживал соблюдение принятых проектных решений. Идея согласования типов занимает в понятии типизации центральное место. Например, возьмем физические единицы измерения. Деля расстояние на время, мы ожидаем получить скорость, а не вес. В умножении температуры на силу смысла нет, а в умножении расстояния на силу - есть. Наконец всех Вас еще в первом классе учили тому, что нельзя складывать яблоки и белок. Все это примеры сильной типизации, когда прикладная область накладывает правила и ограничения на использование и сочетание абстракций. Со слабой типизацией все несколько сложнее.
Слабая типизация очень тесно связана с понятием полиморфизма.
Полиморфизм - положение теории типов, согласно которому имена (например, переменных) могут обозначать объекты разных (но имеющих общего родителя) классов. Любой объект, обозначаемый полиморфным именем, может по-своему реагировать на некий общий набор операций.
Рассмотрим пример. Пускай у нас есть графический редактор. Окно редактора представляет собой некий контейнер, в котором находятся графические объекты. Все графические объекты (треугольник, прямоугольник, круг…) являются подклассами класса GraphicObject. Все это можно представить диаграммой классов (рис. 1.8)
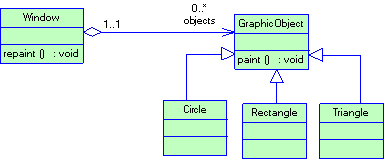
Рисунок 1.8 Иерархия классов графического редактора
Как видно из диаграммы, окно графического редактора (класс Window) содержит (агрегирует) в себе графические объекты. Все, что класс Window знает о классах GraphicObject, так это только то, что графический объект умеет себя перерисовывать (для этого необходимо вызвать метод paint()). Класс Window не знает о существовании классов Circle, Rectangle и Triangle. (Такой подход позволяет добавлять в редактор новые виды графических объектов не изменяя реализацию класса Window. Далее, при рассмотрении паттернов проектирования, мы рассмотрим подобные приемы более подробно). Так вот, когда вам необходимо перерисовать окно редактора, Вы вызываете метод Window::repaint(). Его реализация может выглядить примерно, так:
Window::repaint()
{
clearWindow();
for (int i=0; i<count; i++)
objects[i]->paint();
}
}
Таким образом, объект класса Window, просто вызывает метод paint() для каждого агрегируемого объекта не заботять о том, как именно этот метод будет работать. Этот пример полиморфизма демонстрирует так же суть слабой типизации. Действительно, реальные объекты, находящиеся в векторе objects – это указатели на объекты классов Circle, Rectangle и Triangle. Описаны же они как указатели на объекты класса GraphicObjects (см. первую часть определения полиморфизма). Кроме того, объекты из objects по разному реагируют на одноименную операцию repaint() (круг, квадрат и треугольник для своего отображения действительно выполняют разные действия) (см. вторую часть определения полиморфизма и определения слабой типизации (об управлении использования объектов одного типа, вместо объектов другого типа)).
1.2.6 Параллелизм
Есть задачи, в которых автоматические системы должны обрабатывать много событий одновременно. В других случаях потребность в вычислительной мощности превышает ресурсы одного процессора. В каждой из таких ситуаций естественно использовать несколько компьютеров для решения задачи или задействовать многозадачность на многопроцессорном компьютере. Процесс (поток управления) - это фундаментальная единица действия в системе. Каждая программа имеет по крайней мере один поток управления, параллельная система имеет много таких потоков: век одних недолог, а другие живут в течении всего сеанса работы системы. Реальная параллельность достигается только на многопроцессорных системах, а системы с одним процессором имитируют параллельность за счет алгоритмов разделения времени.
Кроме этого "аппаратного" различия, мы будем различать "тяжелую" и "легкую" параллельность по потребности в ресурсах. "Тяжелые" процессы управляются операционной системой независимо от других, и под них выделяется отдельное защищенное адресное пространство. "Легкие" сосуществуют в одном адресном пространстве. "Тяжелые" процессы общаются друг с другом через операционную систему, что обычно медленно и накладно. Связь "легких" процессов осуществляется гораздо проще, часто они используют одни и те же данные.
Многие современные операционные системы предусматривают прямую поддержку параллелизма, и это обстоятельство очень благоприятно сказывается на возможности обеспечения параллелизма в объектно-ориентированных системах. Например, системы UNIX предусматривают системный вызов fork, который порождает новый процесс. Системы Windows 32 (NT,2000,XP) - многопоточные; кроме того они обеспечивают программные интерфейсы для создания процессов и манипулирования с ними (см. CreateProcess).
Вообще говоря, возможности проектирования параллельности в объектно-ориентированных языках не сильно отличаются от любых других, - на нижних уровнях абстракции параллелизм и OOP развиваются совершенно независимо. С OOP или без, все традиционные проблемы параллельного программирования сохраняются. Действительно, создавать большие программы и так непросто, а если они еще и параллельные, то надо думать о возможном простое одного из потоков, неполучении данных, взаимной блокировке и т.д.
К счастью, на верхних уровнях OOP упрощает параллельное программирование для так как объектная модель неявно разбивает программу на (1) распределенные единицы и (2) сообщающиеся субъекты.
В то время, как объектно-ориентированное программирование основано на абстракции, инкапсуляции и наследовании, параллелизм главное внимание уделяет абстрагированию и синхронизации процессов. Объект есть понятие, на котором эти две точки зрения сходятся: каждый объект (полученный из абстракции реального мира) может представлять собой отдельный поток управления (абстракцию процесса). Такой объект называется активным. Для систем, построенных на основе OOD, мир может быть представлен, как совокупность взаимодействующих объектов, часть из которых является активной и выступает в роли независимых вычислительных центров. На этой основе дадим следующее определение параллелизма: Параллелизм - это свойство, отличающее активные объекты от пассивных.
Хотелось бы отметить, что большинство современных языков программирования в той или иной степени поддерживают параллелизм. Из распространенных языков, наиболее полная поддержка параллелизма присутствует в Java и C#. В С++ параллелизма как такового нет, но он достигается путем использования соответствующих библиотек.
1.2.7 Сохраняемость
Любой программный объект существует в памяти и живет во времени. Можно. предположить, что есть непрерывное множество продолжительности существования объектов: существуют объекты, которые присутствуют лишь во время вычисления выражения, но есть и такие, как базы данных, которые существуют независимо от программы. Этот спектр сохраняемости объектов охватывает:
- Промежуточные результаты вычисления выражений.
- Локальные переменные в вызове процедур.
- Собственные переменные (как в ALGOL-60), глобальные переменные и динамически создаваемые данные.
- Данные, сохраняющиеся между сеансами выполнения программы.
- Данные, сохраняемые при переходе на новую версию программы.
- Данные, которые вообще переживают программу.
Традиционно, первыми тремя уровнями занимаются языки программирования, а последними - базы данных. Этот конфликт культур приводит к неожиданным решениям: программисты разрабатывают специальные схемы для сохранения объектов в период между запусками программы, а конструкторы баз данных переиначивают свою технологию под короткоживущие объекты.
Унификация принципов параллелизма для объектов позволила создать параллельные языки программирования. Аналогичным образом, введение сохраняемости, как нормальной составной части объектного подхода приводит нас к объектно-ориентированным базам данных (OODB, object-oriented databases). На практике подобные базы данных строятся на основе проверенных временем моделей - последовательных, индексированных, иерархических, сетевых или реляционных, но программист может ввести абстракцию объектно-ориентированного интерфейса, через который запросы к базе данных и другие операции выполняются в терминах объектов, время жизни которых превосходит время жизни отдельной программы.
Языки программирования, как правило, не поддерживают понятия сохраняемости; примечательным исключением является Smalltalk, в котором есть протоколы для сохранения объектов на диске и загрузки с диска. Однако, записывать объекты в неструктурированные файлы - это все-таки наивный подход, пригодный только для небольших систем. Как правило, сохраняемость достигается применением (немногочисленных) коммерческих OODB. Другой вариант - создать объектно-ориентированную оболочку для реляционных СУБД; это лучше, в частности, для тех, кто уже вложил средства в реляционную систему.
Сохраняемость - это не только проблема сохранения данных. В OODB имеет смысл сохранять и классы, так, чтобы программы могли правильно интерпретировать данные. Это создает большие трудности по мере увеличения объема данных, особенно, если класс объекта вдруг потребовалось изменить.
В заключение определим сохраняемость следующим образом:
Сохраняемость - способность объекта существовать во времени, переживая породивший его процесс, и (или) в пространстве, перемещаясь из своего первоначального адресного пространства.
1.2.8 Преимущества объектной модели
Как уже говорилось выше, объектная модель принципиально отличается от моделей, которые связаны с более традиционными методами структурного анализа, проектирования и программирования. Это не означает, что объектная модель требует отказа от всех ранее найденных и испытанных временем методов и приемов. Скорее, она вносит некоторые новые элементы, которые добавляются к предшествующему опыту.
Объектный подход обеспечивает ряд существенных удобств, которые другими моделями не предусматривались. Наиболее важно, что объектный подход позволяет создавать системы, которые удовлетворяют пяти признакам хорошо структурированных сложных систем. Согласно нашему опыту, есть еще пять преимуществ, которые дает объектная модель.
- Объектная модель позволяет в полной мере использовать выразительные возможности объектных и объектно-ориентированных языков программирования. Страуструп отмечает: "Не всегда очевидно, как в полной мере использовать преимущества такого языка, как C++. Существенно повысить эффективность и качество кода можно просто за счет использования C++ в качестве "улучшенного C" с элементами абстракции данных. Однако гораздо более значительным достижением является введение иерархии классов в процессе проектирования. Именно это называется OOD и именно здесь преимущества C++ демонстрируются наилучшим образом". Опыт показал, что при использовании таких языков, как Java, Object Pascal, C++ вне объектной модели, их наиболее сильные стороны либо игнорируются, либо применяются неправильно.
- Использование объектного подхода существенно повышает уровень унификации разработки и пригодность для повторного использования не только программ, но и проектов, что в конце концов ведет к созданию среды разработки. Объектно-ориентированные системы часто получаются более компактными, чем их не объектно-ориентированные эквиваленты. А это означает не только уменьшение объема кода программ, но и удешевление проекта за счет использования предыдущих разработок, что дает выигрыш в стоимости и времени.
- Использование объектной модели приводит к построению систем на основе стабильных промежуточных описаний, что упрощает процесс внесения изменений. Это дает системе возможность развиваться постепенно и не приводит к полной ее переработке даже в случае существенных изменений исходных требований.
- Объектная модель уменьшает риск разработки сложных систем, прежде всего потому, что процесс интеграции растягивается на все время разработки, а не превращается в единовременное событие. Объектный подход состоит из ряда хорошо продуманных этапов проектирования, что также уменьшает степень риска и повышает уверенность в правильности принимаемых решений.
- Объектная модель ориентирована на человеческое восприятие мира, или, по словам Робсона, "многие люди, не имеющие понятия о том, как работает компьютер, находят вполне естественным объектно-ориентированный подход к системам".
1.3 Теории классификации
Классификация - средство упорядочения знаний. В объектно-ориентированном анализе определение общих свойств объектов помогает найти общие ключевые абстракции и механизмы, что в свою очередь приводит нас к более простой архитектуре системы. К сожалению, пока не разработаны строгие методы классификации и нет правила, позволяющего выделять классы и объекты. Нет таких понятий, как "совершенная структура классов", "правильный выбор объектов". Как и во многих технических дисциплинах, выбор классов является компромиссным решением.
К счастью, имеется богатый опыт классификации в других науках, на основе которого разработаны методики объектно-ориентированного анализа. Каждая такая методика предлагает свои правила (эвристики) идентификации классов и объектов. Они и будут предметом этого занятия.
Определение классов и объектов - одна из самых сложных задач объектно-ориентированного проектирования. Опыт показывает, что эта работа обычно содержит в себе элементы открытия и изобретения. С помощью открытий мы распознаем ключевые понятия и механизмы, которые образуют словарь предметной области. С помощью изобретения мы конструируем обобщенные понятия, а также новые механизмы, которые определяют правила взаимодействия объектов. Поэтому открытие и изобретение - неотъемлемые части успешной классификации. Целью классификации является нахождение общих свойств объектов. Классифицируя, мы объединяем в одну группу объекты, имеющие одинаковое строение или одинаковое поведение.
Разумная классификация, несомненно, - часть любой науки. Неудивительно, что классификация затрагивает и многие аспекты объектно-ориентированного проектирования. Она помогает определить иерархии наследования, и агрегации. Найдя общие формы взаимодействия объектов, мы вводим механизмы, которые станут фундаментом реализации нашего проекта.
То, что разумная классификация - трудная проблема, новостью не назовешь. И поскольку есть параллели с аналогичными трудностями в объектно-ориентированном проектировании, рассмотрим примеры классификации в биологии.
Вплоть до XVIII века идея о возможности классификации живых организмов по степени сложности была господствующей. Мера сложности была субъективной, поэтому неудивительно, что человек оказался в списке на первом месте. В середине XVIII века шведский ботаник Карл Линней предложил более подробную таксономию для классификации организмов: он ввел понятия рода и вида. Век спустя Дарвин выдвинул теорию, по которой механизмом эволюции является естественный отбор и ныне существующие виды животных - продукт эволюции древних организмов. Теория Дарвина основывалась на разумной классификации видов.
В современной классификации живых существ выделяются группы организмов, имеющих общую генетическую историю, то есть организмы, имеющие сходные ДНК, включаются в одну группу. Классификация по ДНК полезна, чтобы различить организмы, которые похожи внешне, но генетически сильно отличаются. По современным воззрениям дельфины ближе к коровам, чем к форели.
Возможно, для Вас биология представляется зрелой, вполне сформировавшейся наукой с определенными критериями классификации организмов. Но это не так. Биолог Мэй сказал: "На сегодняшний день мы даже не знаем порядок числа видов растений и животных, населяющих нашу планету: классифицировано менее, чем 2 млн. видов, в то время как возможное число видов оценивается от 5 до 50 млн.". Более того, различные критерии классификации одних и тех же животных приводят к разным результатам. Мартин утверждает, что "все зависит от того, что вы хотите получить. Если вы хотите, чтобы классификация говорила о кровном родстве видов, вы получите один ответ, если вы желаете отразить уровень приспособления, ответ будет другой". Можно заключить, что даже в строгих научных дисциплинах методы и критерии классификации сильно зависят от цели классификации.
Вывод прост. Как утверждал Декарт: "Открытие порядка - нелегкая задача, но если он найден, понять его совсем не трудно". Лучшие программистские решения выглядят просто, но, как показывает опыт, добиться простой архитектуры очень трудно.
Все эти сведения приведены здесь не для того, чтобы оправдать "долгострой" в программном обеспечении, хотя на самом деле многим менеджерам и пользователям кажется, что необходимы века, чтобы закончить начатую работу. Я просто хотел подчеркнуть, что разумная классификация - работа интеллектуальная и лучший способ ее ведения - последовательный, итеративный процесс. В начале проблема решается как-нибудь, для каждого частного случая. По мере накопления опыта некоторые решения оказываются более удачными, чем другие, и возникает род фольклора, переходящего от человека к человеку. Удачные решения изучаются более систематически, они программируются и анализируются. Это позволяет развить модели, осуществить их реализацию, и разработать теорию, обобщающую найденное решение. Это в свою очередь поднимает практику на более высокий уровень и позволяет взяться за еще более сложную задачу.
Итеративный подход к классификации накладывает соответствующий отпечаток и на процедуру конструирования иерархии классов и объектов при разработке сложного программного обеспечения. На практике обычно за основу берется какая-то определенная структура классов, которую постепенно совершенствуют. И только на поздней стадии разработки, когда уже получен некоторый опыт использования такой структуры, мы можем критически оценить качество получившейся классификации. Основываясь на полученном опыте, мы можем создать новый подкласс из уже существующих (вывод), или разделить большой класс на много маленьких (факторизация), или, наконец, слить несколько существующих в один (композиция). Возможно, в процессе разработки будут найдены новые общие свойства, ранее не замеченные, и мы сможем определить новые классы (абстракция).
Почему же классификация так сложна? Это объясняется двумя причинами. Во-первых, отсутствием "совершенной" классификации, хотя, естественно, одни классификации лучше других. Во-вторых, разумная классификация требует изрядной доли творческого озарения. Все это напоминает загадку: "Почему лазерный луч похож на золотую рыбку?.. Потому, что ни тот, ни другой не умеют свистеть". Надо быть очень творческим мыслителем, чтобы найти общее в настолько несвязанных предметах.
Со времен Платона проблема классификации занимала умы бесчисленных философов, лингвистов и математиков. Поэтому было бы разумно изучить накопленный опыт и применить его в объектно-ориентированном проектировании. Исторически известны только три подхода:
- классическая категоризация
- концептуальная кластеризация
- теория прототипов
1.3.1 Классическая категоризация
В классическом подходе "все вещи, обладающие данным свойством или совокупностью свойств, формируют некоторую категорию. Причем наличие этих свойств является необходимым и достаточным условием, определяющим категорию". Например, холостые люди - это категория: каждый человек или холост, или женат, и этот признак достаточен для решения вопроса, к какой категории принадлежит тот или иной индивидуум. С другой стороны, высокие люди не определяют категории, если, конечно, мы специально не уточним критерий, позволяющий четко отличать высоких людей от невысоких.
Таким образом, классический подход в качестве критерия похожести объектов использует родственность их свойств. В частности, объекты можно разбивать на непересекающиеся множества в зависимости от наличия или отсутствия некоторого признака. Мински предположил, что "лучшими являются такие наборы свойств, элементы которых мало взаимодействуют между собой. Этим объясняется всеобщая любовь к таким критериям как размер, цвет, форма и материал. Так как эти критерии не пересекаются, про какой-нибудь предмет можно утверждать, что он большой, серый, круглый и деревянный". Вообще говоря, свойства не обязательно должны быть измеряемыми, в качестве их можно использовать наблюдаемое поведение. То обстоятельство, что птицы летают, а рыбы нет, позволяет отличить орла от форели.
Какие конкретно свойства надо принимать во внимание? Это зависит от обстановки. Например, цвет автомобиля надо зафиксировать в задаче учета продукции автомобилестроительного завода, но он не интересен программе, управляющей уличным светофором. Вот почему мы говорим, что нет абсолютного критерия классификации, одна и та же структура классов может подходить для одной задачи и не годиться для другой. Нельзя утверждать, что некоторая схема классификации лучше других отражает структуру и порядок вещей в природе. Природе безразличны наши попытки в ней разобраться. Некоторые классификации действительно важнее других, но только в связи с нашими интересами, а не потому, что они вернее или полнее отражают реальность.
Современное западное мышление по большей части насквозь пропитано классической категоризацией, однако, как показывает пример с высокими и низкими людьми, этот подход не всегда работает. Косок отмечает, что "естественные категории не четко отграничены друг от друга. Большинство птиц летает, но не все. Стул может быть деревянным, металлическим или пластмассовым, а количество ног у него целиком зависит от прихоти конструктора. Практически невозможно перечислить определяющие свойства естественной категории, так, чтобы не было исключений". Это, действительно, коренные пороки классической категоризации, которые и попытались исправить в современных подходах. Ими мы сейчас займемся.
1.3.2 Концептуальная кластеризация
Это более современный вариант классического подхода. Он возник из попыток формального представления знаний. При таком подходе сначала формируются концептуальные описания классов (кластеров объектов), а затем мы классифицируем сущности в соответствии с этими описаниями. Например, возьмем понятие "любовная песня". Это именно понятие, а не признак или свойство, поскольку степень любовности песни едва ли можно измерить. Но если можно утверждать, что песня скорее про любовь, чем про что-то другое, то мы помещаем ее в эту категорию.
Концептуальную кластеризацию можно связать с теорией нечетких (многозначных) множеств, в которой объект может принадлежать к нескольким категориям одновременно с разной степенью точности. Концептуальная кластеризация делает в классификации абсолютные суждения, основываясь на наилучшем согласии
1.3.3 Теория прототипов
Классическая категоризация и концептуальная кластеризация - достаточно выразительные методы, вполне пригодные для проектирования сложных программных систем. Но все же есть ситуации, в которых эти методы не работают. Рассмотрим более современный метод классификации, теорию прототипов, предпосылки которой можно найти в книге по психологии восприятия Рош и ее коллег.
Существуют некоторые абстракции, которые не имеют ни четких свойств, ни четкого определения. Можно объяснить эту проблему так: существуют категории (например, игры), которые не соответствуют классически образцам, так как нет признаков, свойственных всем играм... По этой причине их можно объединить так называемой семейной схожестью... У категории игр нет четкой границы. Категорию можно расширить и включить новые виды игр при условии, что они напоминают уже известные игры. Вот почему этот подход называется теорией прототипов: класс определяется одним объектом-прототипом, и новый объект можно отнести к классу при условии, что он наделен существенным сходством с прототипом.
Еще один пример: мы считаем мягкий пуф, парикмахерское кресло и складной стул стульями не потому, что они удовлетворяют некоторому фиксированному набору признаков прототипа, но потому, что они имеют достаточное фамильное сходство с прототипом... Не требуется никакого общего набора свойств прототипа, которое годилось бы и для пуфика и для парикмахерского кресла, но они оба - стулья, так как каждый из них в отдельности похож на прототипный стул, пусть даже каждый по-своему. Свойства, определяемые при взаимодействии с объектом (свойства взаимодействия), являются главными при определении семейного сходства.
Понятие свойств взаимодействия - центральное для теории прототипов. В концептуальной кластеризации мы группируем в соответствии с различными концепциями. В теории прототипов классификация объектов производится по степени их сходства с конкретным прототипом.
Еще один пример: мы считаем мягкий пуф, парикмахерское кресло и складной стул стульями не потому, что они удовлетворяют некоторому фиксированному набору признаков прототипа, но потому, что они имеют достаточное фамильное сходство с прототипом... Не требуется никакого общего набора свойств прототипа, которое годилось бы и для пуфика и для парикмахерского кресла, но они оба - стулья, так как каждый из них в отдельности похож на прототипный стул, пусть даже каждый по-своему. Свойства, определяемые при взаимодействии с объектом (свойства взаимодействия), являются главными при определении семейного сходства.
Понятие свойств взаимодействия - центральное для теории прототипов. В концептуальной кластеризации мы группируем в соответствии с различными концепциями. В теории прототипов классификация объектов производится по степени их сходства с конкретным прототипом.
2 zПаттерны проектирования классов и объектов
2.1 Механизмы повторного использования
Два наиболее распространенных способа повторного использования функциональности в ОО системах – это наследование класса и композиция объектов. Как уже говорилось, наследование класса позволяет определить реализацию одного класса в терминах другого. Повторное использование за счет порождения подкласса часто называют “прозрачным ящиком” (white-box reuse). Такой термин подчеркивает, что внутреннее устройство родительских классов видимо подклассам.
Второй способ повторного использования некоторой функциональности – композиция объектов. В этом случае новую, более сложную функциональность мы получаем путем установки между объектами отношений связи или агрегации. Для композиции требуется, что бы объекты имели четко определенные интерфейсы. Такой способ повторного использования называют “черным ящиком” (black-box reuse).
И у наследования, и у композиции есть достоинства и недостатки. Наследование определяется статически, на этапе компиляции, его проще использовать, поскольку оно напрямую поддержано языками программирования. Из-за этого наследование быстро работает и быстро пишется. С другой стороны, при наследовании нельзя заменить унаследованную от родителя реализацию во время исполнения программы. Кроме того, родительский класс нередко хотя бы частично определяет физическое представление своих подклассов и часто бывает, что изменение в родителе приводит к каскадному изменению всех, или большинства, подклассов. Наконец при наследовании подклассы имеют доступ к полям родителя, что нарушает принцип инкапсуляции. Перечисленные недостатки наследования, в особенности главное из них – зависимость подклассов от реализации суперкласса, могут повлечь за собой проблемы при попытке повторного использования классов. Если хотя бы один аспект класса оказался непригоден для новой деловой среды, приходится переписывать родительский класс, или вообще программировать новую иерархию наследования. С проблемой можно справиться, если наследовать только абстрактным классам, поскольку в них обычно нет реализации или она минимальна.
Композиция объектов определяется динамически во время выполнения за счет того, что объекты пользуют ссылки на другие объекты. Композицию можно применить, если объекты соблюдают интерфейсы друг друга. Для этого, в свою очередь, требуется тщательно проектировать интерфейсы, так что бы один объект можно было использовать с широким спектром других. Но и выигрыш велик. Поскольку доступ к объектам осуществляется через их интерфейсы, мы не нарушаем инкапсуляцию. Во время выполнения программы любой объект можно заменить другим, лишь бы он имел тот же интерфейс.
Проектирование ОО программ – дело само по себе трудной, а если их нужно использовать повторно, то все становится еще сложнее. Необходимо подобрать подходящие объекты, отнести их к различным классам, соблюдая разумную степень детализации, определить интерфейсы классов и иерархию наследования, и установить существенные отношения между классами. Дизайн должен, с одной стороны, соответствовать решаемой задаче, с другой – быть общим, чтобы удалось учесть все требования, которые могут возникнуть в будущем. Хотелось бы избежать вовсе или, по крайней мере, свести к минимуму, необходимость перепроектирования. Поднаторевшие в ОО проектировании разработчики скажут Вам, что обеспечить “правильный”, то есть в остаточной мере гибкий и пригодный для повторного использования дизайн, с первого раза очень трудно, если вообще возможно. Прежде чем считать цель достигнутой, они обычно пытаются опробовать найденное решение на нескольких задачах, каждый раз модифицируют его. Создать лучший дизайн “на коленках”, то есть сразу и без особых усилий, удается лишь гениальным людям или настоящим профи. С другой стороны, новички, пытающиеся применять приемы ОО проектирования, часто испытывают шок от количества возможных вариантов и возвращаются к привычным не ОО методикам. Проходит немало времени, прежде чем приходит понимание того, что же такое удачный ОО дизайн. Опытные проектировщики, очевидно, знают какие то тонкости, ускользающие от новичков. Попытаемся ответить на вопрос: “А что же это за тонкости?”.
Прежде всего, опытному разработчику понятно, что не нужно решать каждую задачу с нуля. Вместо этого он пытается повторно воспользоваться решениями, которые оказались удачными в прошлом. Отыскав хорошее решение один раз, он будет прибегать к нему снова и снова. Часто, именно благодаря накопленному опыту, проектировщик становится экспертом. Естественно, бесценный опыт получается не только своими шишками. Благо многие гуру OOD делятся своими секретами. Их решения накапливаются, систематизируются и используются проектировщиками во всем мире для того, что бы дизайны получались гибкими, модифицируемыми и расширяемыми. Такие решения и называются паттернами проектирования.
По словам Кристофера Александра, “любой паттерн описывает задачу, которая снова и снова возникает в нашей работе, а так же принцип ее решения, причем таким образом, что это решение можно потом использовать миллион раз, ничего не изобретая заново”. И хотя Александр имел в виду возникающие при проектировании зданий и городов, его слова верны и в отношении паттернов OOD. Наши решения выражаются в терминах объектов и интерфейсов, а не стен, дверей и оконных рам, но в обоих случаях смысл паттерна- предложить решение определенной задачи в конкретном контексте.
В общем случае паттерн состоит из четырех основных элементов:
- Имя. Сославшись на него, мы можем сразу описать проблему проектирования, ее решения и их последствия. Присваивание паттернам имен позволяет проектировать на более высоком уровне абстракции. С помощью имен паттернов можно вести общение с коллегами, например, я могу сказать: “Для создания объектов в данном случае предлагаю использовать фабричный метод”. Или, если позволить себе некоторую стилевую вольность, ”Здесь используем принцип Голливуда”. Короче говоря, назначение паттернов имен упрощает общение в профессиональной среде.
- Задача. Задача это описание того, когда следует применять паттерн. Необходимо сформулировать задачу и ее контекст. Может описываться конкретная проблема проектирования, например способ представления алгоритмов в виде объектов. Так же задача может включать перечень условий, при выполнении которых имеет смысл применять данный паттерн.
- Решение. Решение представляет собой описание элементов дизайна, отношений между ними, функций каждого элемента. Конкретный дизайн или реализация не имеются ввиду, поскольку паттерн – это шаблон, применимый в самых разных ситуациях. Просто дается абстрактное описание задачи проектирования и того, как она может быть решена с помощью некоего весьма обобщенного сочетания элементов (в нашем случае под элементами понимаются классы и объекты).
- Результаты. Результаты это следствия применения паттерна и разного рода компромиссы. Хотя при описании проектных решений о последствиях часто не упоминают, знать о них необходимо, чтобы можно было выбрать между различными вариантами и оценить преимущества и недостатки данного паттерна.
В ряде случаев при описании паттернов задаются дополнительные элементы. О них поговорим при рассмотрении конкретных паттернов. Сейчас же мне хотелось бы немного поговорить о том, как решаются задачи проектирования с помощью паттернов.
2.2 Порождающие паттерны
Порождающие паттерны – паттерны предназначенные для создания объектов. Эти паттерны оказываются важны, когда система больше зависит от композиции объектов, чем от наследования классов. Получается так, что основной упор делается не на жестком кодировании фиксированного набора поведений, а на определении небольшого набора фундаментальных поведений, с помощью композиции которых можно получать любое число более сложных.
Для порождающих паттернов актуальны две темы. Во-первых, эти паттерны инкапсулируют знания о конкретных классах, которые применяются в системе. Во-вторых, скрывают детали того, как эти классы создаются и стыкуются. Единственная информация об объектах, известная системе, - это их интерфейсы, определенные с помощью абстрактных классов. Следовательно, порождающие паттерны обеспечивают большую гибкость при решении вопроса о том, что создается, то это создает, как и когда. Можно собрать систему из «готовых» объектов с самой различной структурой и функциональностью статически (на этапе компиляции) или динамически (во время выполнения). Иногда допустимо выбирать между тем или иным порождающим паттерном. Например, есть случаи, когда с пользой для дела можно использовать как прототип, так и абстрактную фабрику. В других ситуациях порождающие паттерны дополняют друг друга.
2.2.1 Паттерн Singleton
Название
Singleton (одиночка).
Задача
Для некоторых классов важно, чтобы существовал только один экземпляр. Хотя в системе может быть много принтеров, но возможен лишь один спулер. Должна быть только одна файловая система и единственная оконный менеджер. В ряде случае бухгалтерская система должна обслуживать только одну компания.
Как гарантировать, что у класса есть единственный экземпляр и что этот экземпляр легко доступен? Глобальная переменная дает доступ к объекту, но нее запрещает создания нескольких объектов класса. Более удачное решение – сам класс контролирует то, что у него есть только один экземпляр, может запретить создание дополнительных экземпляров, перехватывая запросы на создание новых объектов, и он же способен предоставить доступ к своему экземпляру. Это и есть назначение паттерна одиночка.
Из всего вышесказанного можно сформулировать задачу паттерна Singleton. Singleton гарантирует, что у класса есть только один экземпляр, и предоставляет к нему глобальную точку доступа.
Структура

Рисунок 2.1 Структура паттерна Singleton
Отношения
Клиенты получают доступ к экземпляру Singleton только через Singelton::getInstance()
Результаты
- Гарантирует наличие в системе только одного экземпляра для некоторого класса.
- Из-за того, что в языках программирования подобное поведение реализуется через static методы, нельзя использовать полиморфизм.
2.2.2 Паттерн Prototype
Название
Prototype (прототип).
Назначение
Задает виды создаваемых объектов с помощью экземпляра-прототипа и создает новые объекты путем копирования этого прототипа.
Задача
Паттерн Prototype обеспечивает создание копии объекта без задания конкретного класса со стороны клиента. Используйте паттерн Прототип, когда существует необходимость создавать копии объектов не зная их конкретных типов, а зная только лишь базовый абстрактный тип.
Структура
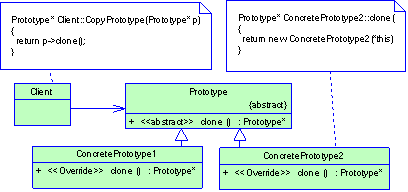
Рисунок 2.2 Структура паттерна Prototype
- Prototype-Прототип: - объявляет интерфейс для клонирования самого себя;
- СonсretePrototype – конкретный прототип: - реализует операцию клонирования себя;
- Client - клиент: - создает новый объект, обращаясь к прототипу с запросом клонировать себя.
Результаты
Преимущества применения прототипа таковы: во-первых, прототип позволяет получить новые объекты не задавая их конкретные классы; во-вторых, мы можем добавлять в систему новые классы за частую не изменяя клиента; в-третьих, мы скрываем от клиента названия конкретных классов (клиент знает только о классе Prototype) уменьшая тем самым степень связности клиента (то есть уменьшаем количество известных ему элементолв)
Среди недостатков можно отметить необходимость добавления в каждый конкретный класс реализации метода clone(), что может быть не всегда удобно.
2.2.3 Паттерн Factory method
Название
Factory method (фабричный метод), Virtual constructor (виртуальный конструктор).
Назначение
Определяет интерфейс для создания объекта, но оставляет подклассам решение о том, какой класс необходимо создать.
Мотивация
Каркасы пользуются абстрактными классами для определения и поддержания отношений между объектами. Кроме того, каркас часто отвечает за создание самих объектов.
Рассмотрим каркас для приложений, способных представлять пользователю сразу несколько документов. Две основных абстракции в таком каркасе - это классы Application и Document. Оба класса абстрактные, поэтому клиенты должны порождать от них подклассы для создания специфичных для приложения реализаций. Например, чтобы создать приложение для рисования, мы определим классы DrawingApplication и DrawingDocument. Класс Application отвечает за управление документами и создает их по мере необходимости, допустим, когда пользователь выбирает из меню пункт Open (открыть) или New (создать).
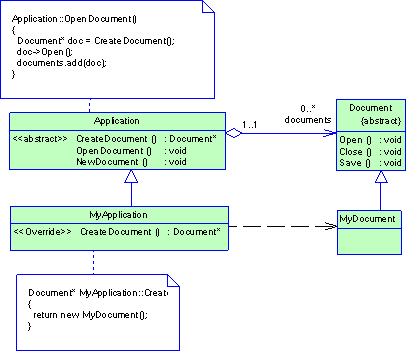
Рисунок 2.3 Структура паттерна Factory Method (пример)
Поскольку решение о том, какой подкласс класса Document необходимо создать зависит от приложения, то Application не может «предсказать», что именно понадобится. Этому классу известно лишь, когда нужно создавать новый документ, а не какой документ создать. Возникает дилемма: каркас должен создавать экземпляры классов, но знает он лишь об абстрактных классах, экземпляры которых создавать нельзя.
Решение предлагает паттерн фабричный метод. В нем инкапсулируется информация о том, какой подкласс класса Document создать, и это знание выводится за пределы каркаса.
Подклассы класса Application переопределяют абстрактную операцию CreateDocument таким образом, чтобы она возвращала подходящий подкласс класса Document. Как только подкласс Application создан, он может создавать специфические для приложения документы, ничего не зная об их классах. Операцию CreateDocument мы называем фабричным методом, поскольку она отвечает за «изготовление» объекта.
Применимость
Классу заранее неизвестно, объекты каких классов ему нужно создавать; класс спроектирован так, чтобы объекты, которые он создает, специфицировались подклассами; класс делегирует свои обязанности одному из нескольких вспомогательных подклассов, и вы планируете локализовать знание о том, какой класс принимает эти обязанности на себя.
Структура и участники
Структура паттерна представлена на рис. 2.4
- Product (Document) - Продукт - определяет интерфейс объектов, создаваемых фабричным методом;
- ConcreteProduct (MyDocument) - конкретный продукт:- реализует интерфейс Product;
- Creator (Application) – создатель - объявляет фабричный метод, возвращающий объект типа Product. Creator может также определять реализацию по умолчанию фабричного метода.
- ConcreteCreator (MyApplication) - конкретный создатель - замещает фабричный метод, возвращающий объект Concrete Product.
Отношения
Создатель "полагается" на свои подклассы в определении фабричного метода, который будет возвращать экземпляр подходящего конкретного продукта.
Результаты
Фабричные методы избавляют проектировщика от необходимости встраивать в код зависящие от приложения классы. Код имеет дело только с интерфейсом класса Product, поэтому он может работать с любыми определенными пользователями классами конкретных продуктов. Потенциальный недостаток фабричного метода состоит в том, что клиентам, возможно, придется создавать подкласс класса Creator для создания лишь одного объекта ConcreteProduct. Порождение подклассов оправдано, если клиенту так или иначе приходится создавать подклассы Creator, в противном случае клиенту придется иметь дело с дополнительным уровнем подклассов.
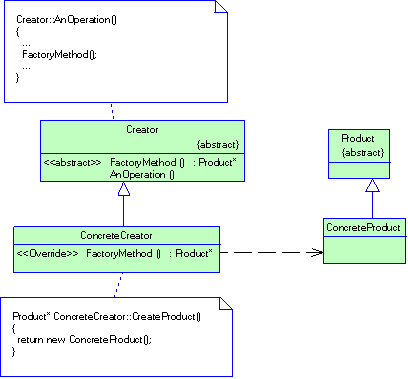
Рисунок 2.4 Структура паттерна Factory Method
2.2.4 Паттерн Reflection
Название
Reflection
Назначение
Обеспечить возможность создание объектов по имени класса для языков программирования, не поддерживающих рефлексию явно.
Структура и участники
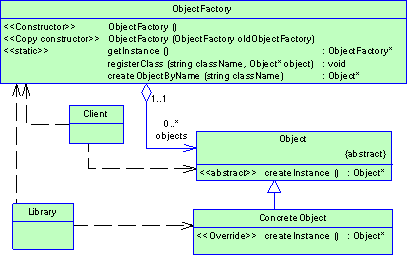
Рисунок 2.5 Структура паттерна Рефлексия
- Object. Базовый класс для всех классов системы, для которых необходимо создание объектов по имени. В простейшем случае объявляет интерфейс с одним абстрактным методом createInstance().
- ConcreteClass1. Конкретный подкласс Object. Реализует метод createInstance(). Наиболее очевидной реализацией этого метода в конкретных подклассах Object является создание самого себя .
- ObjectFactory. Фабрика объектов. Реализуется в соответствии с шаблоном Singleton. Данный класс предоставляет интерфейс для регистрации классов (registerClass()) и для создания объектов (createObjectByName())
- Library. Предоставляет абстрактный интерфейс для модулей системы. Конкретными подклассами Library могут являться классы, инкапсулирующие загрузку динамических библиотек, таких как Dynamic Load Library (DLL) в Win32-системах или Shared Library в Unix-системах. В задачу данного класса входит регистрация содержащихся в них классов у ObjectFactory (рис. 2.6)
- Client. Описывает классы, объекты которых являются клиентами относительно ObjectFactory. Клиенты используют ObjectFactory для создания объектов вызывая у последней createObjectByName() (рис. 2.7)
Взаимодействие
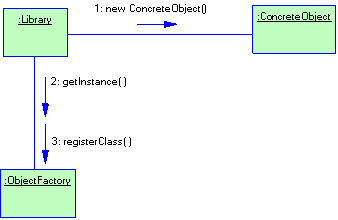
Рисунок 2.6 Регистрация класса
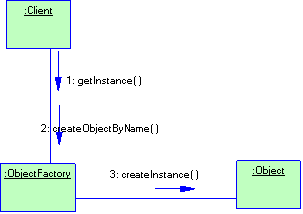
Рисунок 2.7 Создание объекта
Результаты
Основным результатом применения данного паттерна являются возможность создавать объекты классов по имени что, в свою, очередь, повышает гибкость программного решения. С другой стороны, паттерн подразумевает организацию программы как набора динамически подгружаемых библиотек, что может оказаться в некоторых случаях неприемлемым.
2.2.5 Паттерн Creator
Название
Creator (Создатель)
Назначение
Определяет, кто должен отвечать за создание объектов.
Решение
Назначить классу В обязанность создавать экземпляры класса А если выполняется одно из следующих условий.
- Класс В агрегирует (aggregate) объекты А.
- Класс В активно использует (closely uses) объекты А.
- Класс В обладает данными инициализаци, которые будут передаваться объектам А при их создании.
Результаты
Поддерживается шаблон Low Coupling, способствующий снижению затрат на сопровождение и обеспечивающий возможность повторного использования созданных компонентов в дальнейшем.
2.3 Структурные паттерны
В структурных паттернах рассматривается вопрос о том, как из классов и объектов образуются более крупные структуры. Структурные паттерны уровня класса используют наследование для составления композиций из интерфейсов и реализаций.
2.3.1 Паттерн Adapter
Название
Adapter (адаптер), Wrapper (обертка)
Задача
Иногда класс из инструментальной библиотеки не удается использовать только потому, что его интерфейс не соответствует создаваемому приложению. В некоторых случаях мы можем поменять интерфейс на нужный, но если у нас нет исходного кода библиотеки такое решение не подходит. Еще один вариант - определить другой класс таким образом, что от будет адаптировать интерфейс одного класса к другому интерфейсу.
Паттерн Adapter преобразует интерфейс одного класса в интерфейс другого, который ожидают клиенты. Адаптер обеспечивает совместную работу классов с несовместимыми интерфейсами, которая без него была бы невозможна.
Результаты
Первый вариант паттерна называется адаптером объектов, второй адаптером классов. Результаты применения адаптеров объектов и классов немного различаются.
Адаптер классов
- Адаптирует Adaptee к Target, перепоручая действия конкретному классу Adaptee. Так как при наследовании структура программы остается жесткой, данный паттерн не будет работать, если мы захотим одновременно адаптировать класс и его подклассы.
- Так как Adapter является подклассом Adaptee, мы можем легко заменить некоторые операции Adaptee.
- Вводится только один новый объект. Что бы добраться до адаптируемого класса не нужно никаких дополнительных обращений по указателю.
Адаптер объектов
- Позволяет одному адаптеру работать со многими адаптируемыми объектами (а самим Adaptee и со всеми его подклассами).
- Затрудняет замещение операций Adaptee (так как Adapter не является подклассом Adaptee, мы можем использовать полиморфизм, только породив от Adaptee подкласс, заменив в нем операции Adaptee и заставив Adapter ссылаться на этот класс)
Структура
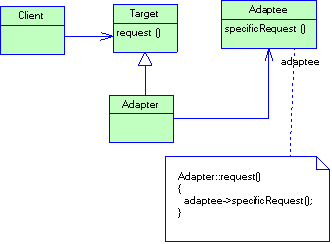
Рисунок 2.8 Структура паттерна Adapter (адаптер объектов)
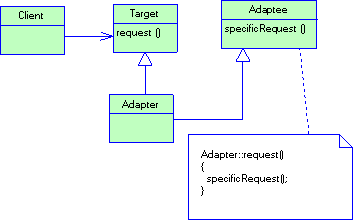
Рисунок 2.9 Структура паттерна Adapter (адаптер классов)
2.3.2 Паттерн Composite
Название
Composite (компоновщик)
Мотивация
Такие приложения, как графические редакторы и редакторы электрических (схем, позволяют пользователям строить сложные диаграммы из более простых компонентов.
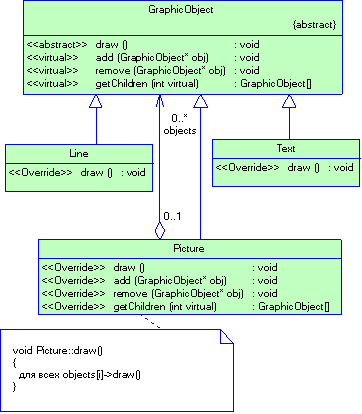
Рисунок 2.10 Структура паттерна Composite (пример)
Проектировщик может сгруппировать мелкие компоненты для формирования более крупных, которые, в свою очередь, могут стать основой для создания еще более крупных. В простой реализации допустимо было бы определить классы графических примитивов, например текста и линий, а также классы, выступающие в роли контейнеров для этих примитивов. Но у такого решения есть существенный недостаток. Программа, в которой эти классы используются, должна по-разному обращаться с примитивами и контейнерами, хотя пользователь чаще всего работает с ними единообразно. Необходимость различать эти объекты усложняет приложение. Паттерн компоновщик описывает, как можно применить рекурсивную композицию таким образом, что клиенту не придется проводить различие между простыми и составными объектами. Пример применения шаблона можно увидеть на на рис. 2.10.
Ключом к паттерну компоновщик является абстрактный класс, который представляет одновременно и примитивы, и контейнеры. В графической системе этот класс может называться Graphic. В нем объявлены операции, специфичные. Для каждого вида графического объекта (такие как Draw) и общие для всех составных объектов, например операции для доступа и управления потомками. Подклассы Line, Rectangle и Text (см. диаграмму выше) определяют примитивные графические объекты. В них операция Draw реализована соответственно для рисования прямых, прямоугольников и текста. Поскольку у примитивных объектов нет потомков, то ни один из этих подклассов не реализует операции, относящиеся к управлению потомками. Класс Picture определяет агрегат, состоящий из объектов Graphic. Реализованная в нем операция Draw вызывает одноименную функцию для каждого Потомка, а операции для работы с потомками уже не пусты. Поскольку интерфейс Класса Picture соответствует интерфейсу Graphic, то в состав объекта Picture Могут входить и другие такие же объекты. Ниже на диаграмме «оказана типичная структура составного объекта, рекурсивно скомпонованного из объектов класса Graphic.
Таким образом можно сформулировать задачу, для которой предназначен паттерн. Компоновщик компонует объекты в древовидные структуры для представления иерархии часть-целое. Позволяет клиентам единообразно трактовать индивидуальные и составные объекты.
Структура
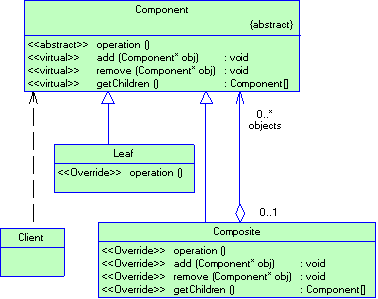
Рисунок 2.11 Структура паттерна Composite
Результаты
- определяет иерархии классов, состоящие из примитивных и составных объектов. Из примитивных объектов можно составлять более сложные, которые, в свою очередь, участвуют в более сложных композициях и так далее. Любой клиент, ожидающий примитивного объекта, может работать и с составным;
- упрощает архитектуру клиента. Клиенты могут единообразно работать с индивидуальными и объектами и с составными структурами. Обычно клиенту неизвестно, взаимодействует ли он с листовым или составным объектом. Это упрощает код клиента, поскольку нет необходимости писать функции, ветвящиеся в зависимости от того, с объектом какого класса они работают;
- облегчает добавление новых видов компонентов. Новые подклассы классов Composite или Leaf будут автоматически работать с уже существующими структурами и клиентским кодом. Изменять клиента при добавлении новых компонентов не нужно;
- способствует созданию общего дизайна. Однако такая простота добавления новых компонентов имеет и свои отрицательные стороны; становится трудно наложить ограничения на то, какие объекты могут входить в состав композиции. Иногда желательно, чтобы составной объект мог включать только определенные виды компонентов. Паттерн компоновщик не позволяет воспользоваться для реализации таких ограничений статической системой типов. Вместо этого следует проводить проверки во время выполнения.
2.3.3 Паттерн Decorator
Название
Decorator (декоратор)
Задачи
Иногда бывает нужно возложить дополнительные обязанности на отдельный объект, а не на класс в целом. Так, библиотека для построения графических интерфейсов пользователя должна «уметь» добавлять новое свойство, скажем, рамку или новое поведение (например, возможность прокрутки к любому элемент у интерфейса). Добавить новые обязанности допустимо с помощью наследования. При наследовании классу с рамкой вокруг каждого экземпляра подкласса будет рисоваться рамка. Однако это решение статическое, а значит, недостаточно гибкое. Клиент не может управлять оформлением компонента рамкой. Более гибким является другой подход: поместить компонент в другой объект, называемый декоратором, который как раз и добавляет рамку. Декоратор следует интерфейсу декорируемого объекта, поэтому его присутствие прозрачно для клиентов компонента. Декоратор переадресует запросы внутреннему компоненту, но может выполнять и дополнительные действия (например, рисовать рамку) до или после переадресации. Поскольку декораторы прозрачны, они могут вкладываться друг в друга, добавляя тем самым любое число новых обязанностей.
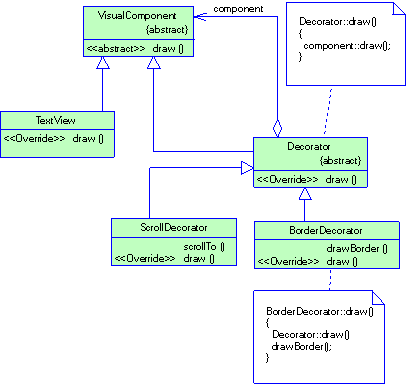
Рисунок 2.12 Структура паттерна Decorator (пример)
Предположим, что имеется объект класса TextView, который отображает текст в окне. По умолчанию TextView не имеет полос прокрутки, поскольку они не всегда нужны. Но при необходимости их удастся добавить с помощью декоратора ScrollDecorator. Допустим, что еще мы хотим добавить жирную сплошную рамку вокруг объекта TextView. Здесь может помочь декоратор BorderDecorator. Ниже на диаграмме показано, как композиция объекта TextView с объектами BorderDecorator и ScrollDecorator порождает элемент для ввода текста, окруженный рамкой и снабженный полосой прокрутки.
Классы ScrollDecorator и BorderDecorator являются подклассами Decorator - абстрактного класса, который представляет визуальные компоненты, применяемые для оформления других визуальных компонентов. VisualComponent - это абстрактный класс для представления визуальных объектов. В нем определен интерфейс для рисования и обработки событий. Отметим, что класс Decorator просто переадресует запросы на рисование своему компоненту, а его подклассы могут расширять эту операцию (см. рис. 2.13).
Структура
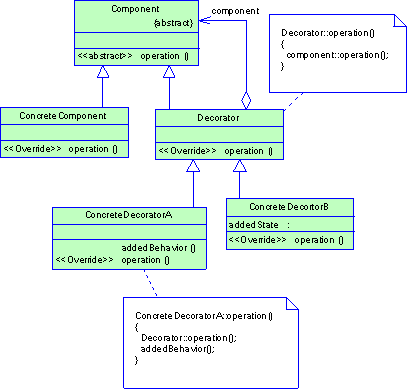
Рисунок 2.13 Структура паттерна Decorator
Результаты
У паттерна декоратор есть, по крайней мере, два плюса и два минуса:
- большая гибкость, нежели у статического наследования. Паттерн декоратор позволяет более гибко добавлять объекту новые обязанности, чем было бы возможно в случае статического (множественного) наследования. Декоратор может добавлять и удалять обязанности во время выполнения программы. При использовании же наследования требуется создавать новый класс для каждой дополнительной обязанности (например, BorderedScrollableTextView, BorderedTextView), что ведет к увеличению числа классов и, как следствие, к возрастанию сложности системы. Кроме того, применение нескольких декораторов к одному компоненту позволяет произвольным образом сочетать обязанности. Декораторы позволяют легко добавить одно и то же свойство дважды. Например, чтобы окружить объект Textview двойной рамкой, нужно просто добавить два декоратора BorderDecorators. Двойное наследование классу Border в лучшем случае чревато ошибками;
- позволяет избежать перегруженных функциями классов ни верхних уровнях иерархии. Декоратор разрешает добавлять новые обязанности по мере необходимости. Вместо того чтобы пытаться поддержать все мыслимые возможности в одном сложном, допускающем разностороннюю настройку классе, вы можете определить простой класс и постепенно наращивать его функциональность с помощью декораторов. В результате приложение уже не платит за неиспользуемые функции. Нетрудно также определять новые виды декораторов независимо от классов, которые они расширяют, даже если первоначально такие расширения не планировались. При расширении же сложного класса обычно приходится вникать в детали, не имеющие отношения к добавляемой функции;
- декоратор и его компонент не идентичны. Декоратор действует как прозрачное обрамление. Но декорированный компонент все же не идентичен исходному. При использовании декораторов это следует иметь в виду;
- множество мелких объектов. При использовании в проекте паттерна декоратор нередко получается система, составленная из большого числа мелких объектов, которые похожи друг на друга и различаются только способом взаимосвязи, а не классом и не значениями своих внутренних переменных. Хотя проектировщик, разбирающийся в устройстве такой системы, может легко настроить ее, но изучать и отлаживать ее очень тяжело.
2.3.4 Паттерн Facade
Название
Facade (фасад)
Назначение
Предоставляет унифицированный интерфейс вместо набора интерфейсов некоторой подсистемы. Фасад определяет интерфейс более высокого уровня, который упрощает использование подсистемы.
Разбиение на подсистемы облегчает проектирование сложной системы в целом. Общая цель всякого проектирования - свести к минимуму зависимость подсистем друг от друга и обмен информацией между ними. Один из способов решения этой задачи - введение объекта фасад, предоставляющий единый упрощенный интерфейс к более сложным системным средствам.
Структура
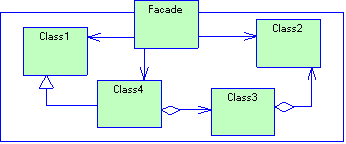
Рисунок 2.14 Структура паттерна Facade
Участники
Facade – фасад. Знает, каким классам подсистемы адресовать запрос; делегирует запросы клиентов подходящим объектам внутри подсистемы;
Классы подсистемы. Реализуют функциональность подсистемы; выполняют работу, порученную объектом Facade; ничего не "знают" о существовании фасада, то есть не хранят ссылок на него.
Отношения
Клиенты общаются с подсистемой, посылая запросы фасаду. Он переадресует их подходящим объектам внутри подсистемы. Хотя основную работу выполняют именно объекты подсистемы, фасаду, возможно, придется преобразовать свой Интерфейс в интерфейсы подсистемы. Клиенты, пользующиеся фасадом, не имеют прямого доступа к объектам подсистемы.
Результаты
У паттерна фасад есть следующие преимущества:
- изолирует клиентов от компонентов подсистемы, уменьшая тем самым число объектов, с которыми клиентам приходится иметь дело, и упрощая работу с подсистемой;
- позволяет ослабить связанность между подсистемой и ее клиентами. Зачастую компоненты подсистемы сильно связаны. Слабая связанность позволяет видоизменять компоненты, не затрагивая при этом клиентов. Фасады помогают разложить систему на слои и структурировать зависимости между объектами, а также избежать сложных и циклических зависимостей. Это может оказаться важным, если клиент и подсистема реализуются независимо Уменьшение числа зависимостей на стадии компиляции чрезвычайно важно в больших системах. Хочется, конечно, чтобы время, уходящее на перекомпиляцию после изменения классов подсистемы, было минимальным. Сокращение числа зависимостей за счет фасадов может уменьшить количество нуждающихся в повторной компиляции файлов после небольшой модификации какой-нибудь важной подсистемы. Фасад может также упростить процесс переноса системы на другие платформы, поскольку уменьшается вероятность того, что в результате изменения одной подсистемы понадобится изменять и все остальные;
- фасад не препятствует приложениям напрямую обращаться к классам подсистемы, если это необходимо. Таким образом, у вас есть выбор между простотой и общностью.
2.3.5 Паттерн Low Coupling
Название
Low Coupling (Низкая связность)
Проблема
Степень связанности (coupling) — это мера, определяющая насколько жестко один элемент связан с другими элементами, либо каким количеством данных о других элементах он обладает. Элемент с низкой степенью связанности (или слабым связыванием) зависит от не очень большого числа других элементов. Выражение "очень много" зависит от контекста, однако необходимо провести его оценку.
Класс с высокой степенью связанности (или жестко связанный) зависит от множества других классов. Однако наличие таких классов нежелательно, поскольку оно приводит к возникновению следующих проблем.
- Изменения в связанных классах приводят к локальным изменениям в данном классе.
- Затрудняется понимание каждого класса в отдельности.
- Усложняется повторное использование, поскольку для этого требуется дополнительный анализ классов, с которыми связан данный класс.
Решение
Распределить обязанности таким образом, чтобы степень связанности оставалась низкой.
Результаты
- Изменения компонентов мало сказываются на других объектах.
- Принципы работы и функции компонентов можно понять, не изучая другие объекты.
- Удобство повторного использования.
Пример
Пусть в системе имеются классы Payment, Sale и Register. Предположим, что необходимо создать экземпляр класса Payment и связать его с объектом Sale. Какой класс должен отвечать за выполнение этой операции? Поскольку в реальной предметной области регистрация объекта Payment выполняется объектом Register, в соответствии с шаблоном Creator, объект Register является хорошим кандидатом для создания объекта Payment. Затем экземпляр объекта Register должен передать сообщение addPayment объекту Sale, указав в качестве параметра новый объект Payment. Приведенные рассуждения отражены на фрагменте диаграммы взаимодействий, представленной на рис. 2.15.Такое распределение обязанностей предполагает, ЧТО класс Register обладает знаниями о данных класса Payment (т.е. связывается с ним).
Обратите внимание на обозначения, принятые в языке UML. Экземпляру объекта Payment присвоено явное имя р, чтобы его можно было использовать в качестве параметра сообщения 2.
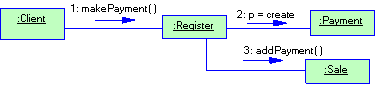
Рисунок 2.15 Диаграмма взаимодействия. Сильная связность
Альтернативный способ создания объекта Payment и его связывания с объектом Sale состоит в том, что бы возложит обязанность за создание объекта Payment на Sale (рис. 2.16)
Рисунок 2.16 Диаграмма взаимодействия. Слабая связность
Когда не следует применять шаблон
Высокая степень связывания с устойчивыми элементами не представляет проблемы. Например, приложение J2EE можно жестко связать с библиотеками Java (java.util и т.п.), поскольку эти библиотеки широко распространены и стабильны.
Выбери свою игру
Высокая степень связывания сама по себе не является проблемой. Проблемой является жесткое связывание с неустойчивыми в некотором отношении элементами.
Важно понимать следующее. Разработчик может обеспечивать гибкость программы, реализовывать принцип инкапсуляции и придерживаться принципа слабого связывания во многих аспектах системы. Однако без убедительной мотивации не следует во что бы то ни стало бороться за уменьшение степени связывания объектов. Разработчики должны выбрать "свою игру", чтобы снизить степень связывания и обеспечить инкапсуляцию. При этом особое внимание нужно уделить неустойчивым или быстро изменяющимся элементам.
2.3.6 Паттерн Information Expert
Название
Information Expert (информационный эксперт)
Проблема
Каков наиболее общий принцип распределения обязанностей между объектами при объектно-ориентированном проектировании?
В модели системы могут быть определены десятки или сотни программных классов, а в приложении может потребоваться выполнение сотен или тысяч обязанностей. Во время объектно-ориентированного проектирования при формулировке принципов взаимодействия объектов необходимо распределить обязанности между классами.
При правильном выполнении этой задачи система становится гораздо проще для понимания, поддержки и расширения. Кроме того, появляется возможность повторного использования уже разработанных компонентов в последующих приложениях.
Решение
Назначить обязанность информационному эксперту — классу, у которого имеется информация, требуемая для выполнения обязанности.
Результаты
Соответствующее поведение системы обеспечивается несколькими классами содержащими требуемую информацию. Это приводит к определениям классов, которые гораздо проще понимать и поддерживать. Кроме того, поддерживается шаблон High Cohesion
Пример
В приложении некоторому классу необходимо знать общую сумму продажи. Начинайте распределение обязанностей с их четкой формулировки. С этой точки зрения можно сформулировать следующее утверждение.
Какой класс должен отвечать за знание общей суммы продажи?
Согласно шаблону Information Expert, нужно определить, объекты каких классов содержат информацию, необходимую для вычисления общей суммы.
Теперь возникает ключевой вопрос: на основе какой модели нужно анализировать информацию - модели предметной области или проектирования? Модель предметной области иллюстрирует концептуальные классы из предметной области системы, а в модели проектирования показаны программные классы.
Ответ на этот вопрос сводится к следующему:
Если в модели проектирования имеются соответствующие классы, в первую очередь, следует использовать ее.
В противном случае нужно обратиться к модели предметной области и постараться уточнить ее для облегчения создания соответствующих программных классов.
Например, предположим, мы находимся в самом начале этапа проектирования, когда модель проектирования представлена в минимальном объеме. Следовательно, кандидатуру на роль информационного эксперта следует искать в модели предметной области. Вероятно, на эту роль подойдет концептуальный класс Sale. Тогда в модель проектирования нужно добавить соответствующий программный класс под именем Sale и присвоить ему обязанность вычисления общей стоимости, реализуемую с помощью вызова метода getTotal. При таком подходе сокращается разрыв между организацией программных объектов и соответствующих им понятий из предметной области.
Чтобы рассмотреть этот пример подробнее, обратимся к фрагменту модели предметной области, представленному на рис. 2.17.
Рисунок 2.17 Фрагмент модели предметной области
Какая информация требуется для вычисления общей суммы? Необходимо узнать стоимость всех проданных товаров SalesLineltem и просуммировать эти промежуточные суммы. Такой информацией обладает лишь экземпляр объекта Sale. Следовательно, с точки зрения шаблона Information Expert объект Sale v подходит для выполнения этой обязанности, т.е. является информационным экспертом (information expert).
Как уже упоминалось, подобные вопросы распределения обязанностей зачастую возникают при создании диаграмм взаимодействий. Представьте, что вы приступили к работе, начав создание диаграмм для распределения обязанностей между объектами. Принятые решения иллюстрируются на фрагменте диаграммы Взаимодействий, представленном на рис. 2.18.
Однако на данном этапе выполнена не вся работа. Какая информация требуется для вычисления промежуточной суммы элементов продажи? Необходимы значения атрибутов SalesLineltem.quantity и SalesLineltem.price. Объекту SalesLineltem известно количество товара и известен связанный с ним объект ProductSpecif ication. Следовательно, в соответствии с шаблоном Expert, промежуточную сумму должен вычислять объект SalesLineltem. Другими словами, этот объект является информационным экспертом.
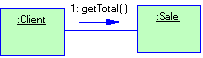
Рисунок 2.18 Распределение обязанностей в соответствии с паттерном Information Expert
В терминах диаграмм взаимодействий это означает, что объект Sale должен передать сообщения getSubtotal каждому объекту SalesLineltem, а затем просуммировать полученные результаты. Этот процесс проиллюстрирован на рис. 2.19

Рисунок 2.19 Распределение обязанностей в соответствии с паттерном Information Expert
Для выполнения обязанности, связанной со знанием и предоставлением промежуточной суммы, объекту SalesLineltem должна быть известна стоимость товара. В данном случае в качестве информационного эксперта будет выступать объект ProductSpecification (рис. 2.20).
В завершение можно сказать следующее. Для выполнения обязанности "знать и предоставлять общую сумму продажи трем объектам классов" были следующим образом присвоены три обязанности:
- Sale - знание общей суммы продажи
- SalesLineltem - знание промежуточной суммы для данного товара
- Product Specification - нание цены товара
Рассмотрение и распределение обязанностей выполнялись в процессе создания диаграммы взаимодействий. Затем полученные результаты могут быть реализованы в разделе методов диаграммы классов. При назначении обязанностей, согласно шаблону Expert, был применен следующий принцип: обязанности связываются с тем объектом, который имеет информацию, необходимую для их выполнения.
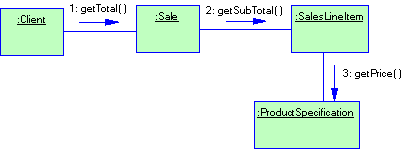
Рисунок 2.20 Распределение обязанностей в соответствии с паттерном Information Expert
2.4 Паттерны поведения
Паттерны поведения связаны с алгоритмами и распределением обязанностей между объектами. Речь в них идет не только о самих объектах и классах, но и о типичных способах взаимодействия. Паттерны поведения характеризуют сложный поток управления, который трудно проследить во время выполнения программы. Внимание акцентировано не на потоке управления как таковом, а на связях между объектами.
2.4.1 Паттерн Iterator
Название
Iterator (итератор). Cursor (курсор)
Задача
Предоставляет способ последовательного доступа ко всем элементам составного объекта, не раскрывая его внутреннего представления.
Мотивация
Составной объект, скажем список, должен предоставлять способ доступа к своим элементам, не раскрывая их внутреннюю структуру. Более того, иногда требуется обходить список по-разному, в зависимости от решаемой задачи. Но вряд ли вы захотите засорять интерфейс класса List операциями для различных вариантов обхода, даже если все их можно предвидеть заранее. Кроме того, иногда нужно, чтобы в один и тот же момент было определено несколько активных обходов списка. Все это позволяет сделать паттерн итератор. Основная его идея в том, чтобы за доступ к элементам и способ обхода отвечал не сам список, а отдельный объект - итератор. В классе Iterator определен интерфейс для доступа к элементам списка. Объект этого класса отслеживает текущий элемент, то есть он располагает информацией, какие элементы уже посещались. Например, класс List мог бы предусмотреть класс ListIterator.
Рисунок 2.21 Итератор
Прежде чем создавать экземпляр класса Listlterator, необходимо иметь список, подлежащий обходу. С объектом Listlterator вы можете последовательно посетить все элементы списка. Операция сurrentltem возвращает текущий элемент списка, операция first инициализирует текущий элемент первым элементом списка, Next делает текущим следующий элемент, a eof проверяет, не оказались ли мы за последним элементом, если да, то обход завершен.
Отделение механизма обхода от объекта List позволяет определять итераторы, реализующие различные стратегии обхода, не перечисляя их в интерфейсе класса List. Например, FilteringListIterator мог бы предоставлять доступ только к тем элементам, которые удовлетворяют условиям фильтрации. Заметим: между итератором и списком имеется тесная связь, клиент должен иметь информацию, что он обходит именно список, а не какую-то другую агрегированную структуру. Поэтому клиент привязан к конкретному способу агрегирования. Было бы лучше, если бы мы могли изменять класс агрегата, не трогая код клиента. Это можно сделать, обобщив концепцию итератора и рассмотрев полиморфную итерацию.Например, предположим, что у нас есть еще класс SkipList, реализующий список. Список с пропусками (skiplist) - это вероятностная структура данных, по характеристикам напоминающая сбалансированное дерево. Нам нужно научиться писать код, способный работать с обьектами как класса List, так и класса SkipList.
Рисунок 2.22 Структура паттерна Iterator (пример)
Отделение механизма обхода от объекта List позволяет определять итераторы, реализующие различные стратегии обхода, не перечисляя их в интерфейсе класса List. Например, FilteringListIterator мог бы предоставлять доступ только к тем элементам, которые удовлетворяют условиям фильтрации. Заметим: между итератором и списком имеется тесная связь, клиент должен иметь информацию, что он обходит именно список, а не какую-то другую агрегированную структуру. Поэтому клиент привязан к конкретному способу агрегирования. Было бы лучше, если бы мы могли изменять класс агрегата, не трогая код клиента. Это можно сделать, обобщив концепцию итератора и рассмотрев полиморфную итерацию.Например, предположим, что у нас есть еще класс SkipList, реализующий список. Список с пропусками (skiplist) - это вероятностная структура данных, по характеристикам напоминающая сбалансированное дерево. Нам нужно научиться писать код, способный работать с обьектами как класса List, так и класса SkipList.
Определим класс AbstractList, в котором объявлен общий интерфейс для манипулирования списками. Еще нам понадобится абстрактный класс Iterator, определяющий общий интерфейс итерации. Затем мы смогли бы определить конкретные подклассы класса Iterator для различных реализаций списка. В результате механизм итерации оказывается не зависящим от конкретных агрегированных классов.
Структура
Структура паттерна представлена на рис. 2.23.
- Iterator - итератор; определяет интерфейс для доступа и обхода элементов;
- Concretelterator - конкретный итератор; - реализует интерфейс класса Iterator; - следит за текущей позицией при обходе агрегата;
- Aggregate - агрегат:- определяет интерфейс для создания объекта-итератора;
- ConcreteAggregate - конкретный агрегат:- реализует интерфейс создания итератора и возвращает экземпляр подходящего класса Concretelterator.
Результаты
У паттерна итератор есть следующие важные особенности:
- поддерживает различные виды обхода агрегата. Сложные агрегаты можно обходить по-разному. Например, для генерации кода и семантических проверок нужно обходить деревья синтаксического разбора. Генератор кода может обходить дерево во внутреннем или прямом порядке. Итераторы упрощают изменение алгоритма обхода - достаточно просто заменить один экземпляр итератора другим. Для поддержки новых видов обхода можно определить и подклассы класса Iterator;
- итераторы упрощают интерфейс класса Aggregate. Наличие интерфейса для обхода в классе Iterator делает излишним дублирование этого интерфейса в классе Aggregate. Тем самым интерфейс агрегата упрощается;
- одновременно для данного агрегата может быть активно несколько обходов. Итератор следит за инкапсулированным в нем самом состоянием обхода. Поэтому одновременно разрешается осуществлять несколько обходов агрегата.
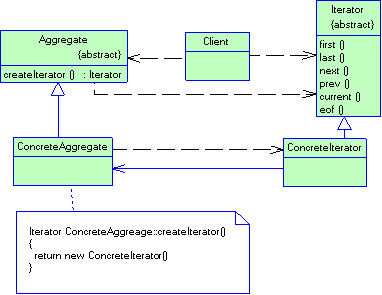
Рисунок 2.23 Структура паттерна Iterator
2.4.2 Паттерн Mediator
Название
Mediator (посредник)
Задача
Определяет объект, инкапсулирующий способ взаимодействия множества объектов. Посредник обеспечивает слабую связанность системы, избавляя объекты от необходимости явно ссылаться друг на друга и позволяя тем самым независимо изменять взаимодействия между ними.
Мотивация
Объектно-ориентированное проектирование способствует распределению некоторого поведения между объектами. Но при этом в получившейся структуре объектов может возникнуть много связей или (в худшем случае) каждому объекту придется иметь информацию обо всех остальных. Несмотря на то что разбиение системы на множество объектов в общем случае повышает степень повторного использования, однако изобилие взаимосвязей Приводит к обратному эффекту. Если взаимосвязей слишком много, тогда система подобна монолиту и маловероятно, что объект сможет работать без поддержки Других объектов. Более того, существенно изменить поведение системы практически невозможно, поскольку оно распределено между многими объектами. Если вы предпримете подобную попытку, то для настройки поведения системы вам придется определять множество подклассов.
Рассмотрим реализацию диалоговых окон в графическом интерфейсе пользователя. Здесь располагается ряд виджетов: кнопки, поля ввода и т.д., как Показано на рис. 2.24.
Рисунок 2.24. Форма для поиска
Часто между разными виджетами в диалоговом окне существуют зависимости. Например, если одно из полей ввода пустое, то определенная кнопка недоступна. При выборе из списка может измениться содержимое поля ввода. И наоборот, ввод текста в некоторое поле может автоматически привести к выбору одного или нескольких элементов списка. Если в поле ввода присутствует какой-то текст, то могут быть активизированы кнопки, позволяющие произвести определенное действие над этим текстом, например изменить либо удалить его.
Рисунок 2.25 Иерархия классов виджетов окна с использованием посредника
Рисунок 2.26 Типовая последовательность обработки события
В разных диалоговых окнах зависимости между виджетами могут быть различными. Поэтому, несмотря на то, что во всех окнах встречаются однотипные виджеты, просто взять и повторно использовать готовые классы виджетов не удастся, придется производить настройку с целью учета зависимостей. Индивидуальная настройка каждого виджета - утомительное занятие, ибо участвующих классов слитком много.
Всех этих проблем можно избежать, если инкапсулировать коллективное поведение в отдельном объекте посреднике. Посредник отвечает за координацию взаимодействий между группой объектов. Он избавляет входящие в группу объекты от необходимости явно ссылаться друг на друга. Все объекты располагают информацией только о посреднике, поэтому количество взаимосвязей сокращается. Так, класс UIFind может служить посредником между виджетами в диалоговом окне. Объект этого класса «знает» обо всех виджетах в окне.
Структуру классов, полученную в результате применения посредника для примера, представленного на рис. 2.24, можно увидеть на рис. 2.25, а диаграмму взаимодействия – на рис. 2.26.
Структура
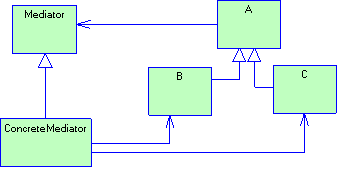
Рисунок 2.27 Структура паттерна Mediator
- Mediator посредник:- определяет интерфейс для обмена информацией с объектами С;
- ConcreteMediator конкретный посредник: - реализует кооперативное поведение, координируя действия объектов C;
- Классы C, A, B. Каждый из таких классов "знает" о своем объекте Mediator; - все объекты этих классов обмениваются информацией только с посредником, так как при его отсутствии им пришлось бы общаться между собой напрямую
Результаты
У паттерна посредник есть следующие достоинства и недостатки:
- устраняет связанность между подклассами С. Изменять классы C и Mediator можно независимо друг от друга;
- упрощает протоколы взаимодействия объектов. Посредник заменяет дисциплину взаимодействия «все со всеми» дисциплиной «один со всеми», то есть один посредник взаимодействует со всеми подклассами С. Отношения вида «один ко многим» проще для понимания, сопровождения и расширения;
- абстрагирует способ кооперирования объектов. Выделение механизма посредничества в отдельную концепцию и инкапсуляция ее в одном объекте позволяет сосредоточиться именно на взаимодействии объектов, а не на их индивидуальном поведении. Это дает возможность прояснить имеющиеся в системе взаимодействия;
- централизует управление. Паттерн посредник переносит сложность взаимодействия в класс-посредник. Поскольку посредник инкапсулирует протоколы, то он может быть сложнее отдельных С. В результате сам посредник становится монолитом, который трудно сопровождать.
2.4.3 Паттерн Observer
Название
Observer (наблюдатель). Dependents (подчиненные), Publish-Subscribe (издатель-подписчик).
Задача
Определяет зависимость типа один ко многим между объектами таким образом, что при изменении состояния одного объекта все зависящие от него оповещаются об этом и автоматически обновляются.
Мотивация
В результате разбиения системы на множество совместно работающих классов появляется необходимость поддерживать согласованное состояние взаимосвязанных объектов. Но не хотелось бы, чтобы за согласованность надо было платить жесткой связанностью классов, так как это в некоторой степени уменьшает возможности повторного использования. Например, во многих библиотеках для построения графических интерфейсов пользователя презентационные аспекты интерфейса отделены от данных приложения. С классами, описывающими данные и их представление, можно работать автономно. Электронная таблица и диаграмма не имеют информации друг о друге, поэтому вы вправе использовать их по отдельности. Но ведут они себя так, как будто «знают» друг о друге. Когда пользователь работает с таблицей, все изменения немедленно отражаются на диаграмме, и наоборот.
При таком поведении подразумевается, что и электронная таблица, и диаграмма зависят от данных объекта и поэтому должны уведомляться о любых изменениях в его состоянии. И нет никаких причин, ограничивающих количество зависимых объектов; для работы с одними и теми же данными может существовать любое число пользовательских интерфейсов.
Паттерн наблюдатель описывает, как устанавливать такие отношения. Ключевыми объектами в нем являются субьект и наблюдатель. У субъекта может быть сколько угодно зависимых от него наблюдателей. Все наблюдатели уведомляются об изменениях в состоянии субъекта. Получив уведомление, наблюдатель опрашивает субъекта, чтобы синхронизировать с ним свое состояние. Такого рода взаимодействие часто называется отношением издатель-подписчик. Субъект издает или публикует уведомления и рассылает их, даже не имея информации о том, какие объекты являются подписчиками. На получение уведомлений может подписаться неограниченное количество наблюдателей.
Структура и участники
- Subject - субъект: располагает информацией о своих наблюдателях. За субъектом может «следить» любое число наблюдателей; так же субъект предоставляет интерфейс для присоединения и отделения наблюдателей;
- Observer- наблюдатель: определяет интерфейс обновления для объектов, которые должны быть уведомлены об изменении субъекта;
- ConcreteSubject - конкретный субъект: сохраняет состояние, представляющее интерес для конкретного наблюдателя ConcreteObserver; посылает информацию своим наблюдателям, когда происходит изменение;
- ConcreteObserver - конкретный наблюдатель; Хранит ссылку на конкретного субъекта для получения доступа к состоянию последнего.
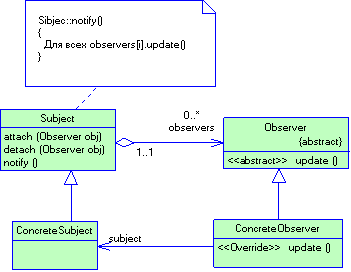
Рисунок 2.28 Структура паттерна Observer
Результаты
Паттерн наблюдатель позволяет изменять субъекты и наблюдатели независимо друг от друга. Субъекты разрешается повторно использовать без участия наблюдателей, и наоборот. Это дает возможность добавлять новых наблюдателей без модификации субъекта или других наблюдателей.
Рассмотрим некоторые достоинства и недостатки паттерна наблюдатель:
- Абстрактная связанность субъекта и наблюдателя. Субъект имеет информацию лишь о том, что у него есть ряд наблюдателей, каждый из которых подчиняется простому интерфейсу абстрактного класса Observer. Субъекту неизвестны конкретные классы наблюдателей. Таким образом, связи между субъектами и наблюдателями носят абстрактный характер и сведены к минимуму. Поскольку субъект и наблюдатель не являются тесно связанными, то они могут находиться на разных уровнях абстракции системы. Субъект более низкого уровня может уведомлять наблюдателей, находящихся на верхних уровнях, не нарушая иерархии системы. Если бы субъект и наблюдатель представляли собой единое целое, то получающийся объект либо пересекал бы границы уровней (нарушая принцип их формирования), либо должен был находиться на каком-то одном уровне (компрометируя абстракцию уровня);
- Поддержка широковещательных коммуникаций. В отличие от обычного запроса для уведомления, посылаемого субъектом, не нужно задавать определенного получателя. Уведомление автоматически поступает всем подписавшимся на него объектам. Субъекту не нужна информация о количестве таких объектов, от него требуется всего лишь уведомить своих наблюдателей. Поэтому мы можем в любое время добавлять и удалять наблюдателей. Наблюдатель сам решает, обработать полученное уведомление или игнорировать его;
- Неожиданные обновления. Поскольку наблюдатели не располагают информацией друг о друге, им неизвестно и о том, во что обходится изменение субъекта. Безобидная, на первый взгляд, операция над субъектом может вызвать целый ряд обновлений наблюдателей и зависящих от них объектов. Более того, нечетко определенные или плохо поддерживаемые критерии зависимости могут стать причиной непредвиденных обновлений, отследить которые очень сложно. Эта проблема усугубляется еще и тем, что простой протокол обновления не содержит никаких сведений о том, что именно изменилось в субъекте. Без дополнительного протокола, помогающего выяснить характер изменений, наблюдатели будут вынуждены проделать сложную работу для косвенного получения такой информации.
2.4.4 Паттерн State
Название
State (состояние)
Задача
Позволяет объекту варьировать свое поведение в зависимости от внутреннего состояния. Извне создается впечатление, что изменился класс объекта.
Мотивация
Рассмотрим класс TCPConnection, с помощью которого представлено сетевое соединение. Объект этого класса может находиться в одном из нескольких состояний: Established (установлено), Listening (прослушивание), Closed (закрыто). Когда объект TCPConnection получает запросы от других объектов, То в зависимости от текущего состояния он отвечает по-разному. Например, ответ на запрос open (открыть) зависит от того, находится ли соединение в состоянии Closed или Established. Паттерн состояние описывает, каким образом объект TCPConnection может вести себя по-разному, находясь в различных состояниях.
Основная идея этого паттерна заключается в том, чтобы ввести абстрактный класс TCPState для представления различных состояний соединения. Этот класс объявляет интерфейс, общий для всех классов, описывающих различные рабочие состояния. В подклассах TCPState реализовано поведение, специфичное для конкретного состояния. Например, в классах TCPEstablished и TCPClosed реализовано поведение, характерное для состояний Established и Closed соответственно
Класс TCPConnection хранит у себя объект состояния (экземпляр некоторого подкласса TCPState), представляющий текущее состояние соединения, и делегирует все зависящие от состояния запросы этому объекту. TCPConnection использует свой экземпляр подкласса TCPState для выполнения операций, свойственных только данному состоянию соединения.
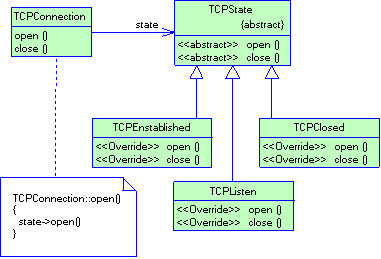
Рисунок 2.29 Структура паттерна State (пример)
При каждом изменении состояния соединения TCPConnection изменяет свой объект-состояние. Например, когда установленное соединение закрывается, TCPConnection заменяет экземпляр класса TCPEstablished экземпляром TCPClosed.
Паттерн State имеет смысл использовать в следующих ситуациях:
- когда поведение объекта зависит от его состояния и должно изменяться по время выполнения;
- когда в коде операций встречаются состоящие из многих ветвей условные операторы, в которых выбор ветви зависит от состояния. Обычно в таком случае состояние представлено перечисляемыми константами. Часто одна и та же структура условного оператора повторяется в нескольких операциях. Паттерн состояние предлагает поместить каждую ветвь в отдельный класс. Это позволяет трактовать состояние объекта как самостоятельный объект, который может изменяться независимо от других.
Структура
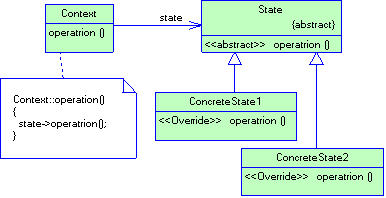
Рисунок 2.30 Структура паттерна State
Результаты
Локализует зависящее от состояния поведение и делит его на части, соответствующие состояниям. Паттерн состояние помещает все поведение, ассоциированное с конкретным состоянием, в отдельный объект. Поскольку зависящий от состояния код целиком находится в одном из подклассов класса State, то добавлять новые состояния и переходы можно просто путем порождения новых подклассов. Вместо этого можно было бы использовать данные-члены для определения внутренних состояний, тогда операции объекта Context проверяли бы эти данные. Но в таком случае похожие условные операторы или операторы ветвления были бы разбросаны по всему коду класса Context. При этом добавление нового состояния потребовало бы изменения нескольких операций, что затруднило бы сопровождение. Паттерн состояние позволяет решить эту проблему, но одновременно порождает другую, поскольку поведение для различных состояний оказывается распределенным между несколькими подклассами State. Это увеличивает число классов. Конечно, один класс компактнее, но если состояний много, то такое распределение эффективнее, так как в противном случае пришлось бы иметь дело с громоздкими условными операторами. Наличие громоздких условных операторе в нежелательно, равно как и наличие длинных процедур. Они слишком монолитны, вот почему модификация и расширение кода становится проблемой. Паттерн состояние предлагает более удачный способ структурирования зависящего от состояния кода. Логика, описывающая переходы между состояниями, больше не заключена в монолитные операторы if или switch, а распределена между подклассами state. При инкапсуляции каждого перехода и действия в класс состояние становится полноценным объектом. Это улучшает структуру кода и проясняет его назначение;
Делает явными переходы между состояниями. Если объект определяет свое текущее состояние исключительно в терминах внутренних данных, то переходы между состояниями не имеют явного представления; они проявляются лишь как присваивания некоторым переменным. Ввод отдельных объектов для различных состояний делает переходы более явными. Кроме того, объекты State могут защитить контекст Context от рассогласования внутренних переменных, поскольку переходы с точки зрения контекста - это атомарные действия. Для осуществления перехода надо изменить значение только одной переменной (объектной переменной State в классе Context), а не нескольких;
2.4.5 Паттерн Strategy
Название
Strategy (стратегия). Policy (политика) .
Задача
Определяет семейство алгоритмов, инкапсулирует каждый из них и делает их взаимозаменяемыми. Стратегия позволяет изменять алгоритмы независимо от клиентов, которые ими пользуются.
Мотивация
Существует много алгоритмов для разбиения текста на строки. Жестко "зашивать" вес подобные алгоритмы в классы, которые в них нуждаются, нежелательно по нескольким причинам:
- Клиент, которому требуется алгоритм разбиения на строки, усложняется при включении в него соответствующего кода. Таким образом, клиенты становятся более громоздкими, а сопровождать их труднее, особенно если нужно поддержать сразу несколько алгоритмов;
- В зависимости от обстоятельств стоит применять тот или иной алгоритм. Не хотелось бы поддерживать несколько алгоритмов разбиения на строки, если мы не будем ими пользоваться;
- Если разбиение на строки - неотъемлемая часть клиента, то задача добавления новых и модификации существующих алгоритмов усложняется.
Всех этих проблем можно избежать, если определить классы, инкапсулирующие различные алгоритмы разбиения на строки. Инкапсулированный таким образом алгоритм называется стратегией.
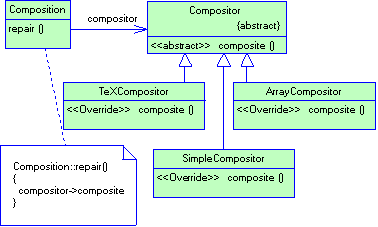
Рисунок 2.31 Структура паттерна Strategy (пример)
Предположим, что класс Composition отвечает за разбиение на строки текста, отображаемого в окне программы просмотра, и его своевременное обновление. Стратегии разбиения на строки определяются не в классе Composition, а в подклассах абстрактного класса Compositor. Это могут быть, например, такие стратегии:
- SimpleCompositor реализует простую стратегию, выделяющую по одной строке за раз;
- TeXCompositor реализует алгоритм поиска точек разбиения на строки, принятый в редакторе TeX. Эта стратегия пытается выполнить глобальную оптимизацию разбиения на строки, рассматривая сразу целый параграф;
- Array-Compositor реализует стратегию расстановки переходов на новую строку таким образом, что в каждой строке оказывается одно и то же число элементов. Это полезно, например, при построчном отображении набора пиктограмм.
Объект Composition хранит ссылку на объект Compositor. Всякий раз, когда объекту Composition требуется переформатировать текст, он делегирует данную обязанность своему объекту Compositor. Клиент указывает, какой объект Compositor следует использовать, параметризуя им объект Composition.
Используйте паттерн Стратегия, когда:
- Имеется много родственных классов, отличающихся только поведением. Стратегия позволяет сконфигурировать класс, задав одно из возможных поведений;
- Вам нужно иметь несколько разных вариантов алгоритма. Например, можно определить два варианта алгоритма, один из которых требует больше времени, а другой - больше памяти. Стратегии разрешается применять, когда варианты алгоритмов реализованы в виде иерархии классов;
- В алгоритме содержатся данные, о которых клиент не должен знать. Используйте паттерн стратегия, чтобы не раскрывать сложные, специфичные для алгоритма структуры данных;
- В классе определено много поведений, что представлено разветвленными условными операторами. В этом случае проще перенести код из ветвей в отдельные классы стратегий.
Структура и участники
- Strategy (Compositor) - стратегия: объявляет общий для всех поддерживаемых алгоритмов интерфейс. Класс Context пользуется этим интерфейсом для вызова конкретного алгоритма, определенного в классе ConcreteStratecjy;
- ConcreteStrategy (SirnpleCompositor, TeXCompositor, ArrayCompositor) - конкретная стратегия: - реализует алгоритм, использующий интерфейс, объявленный в классе Strategy;
- Context (Composition) - контекст: - конфигурируется объектом класса ConcreteStrategy; хранит ссылку на объект класса Strategy; может определять интерфейс, который позволяет объекту strategy получить доступ к данным контекста.
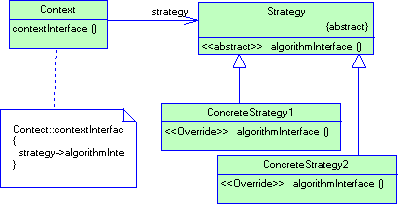
Рисунок 2.32 Структура паттерна Strategy
Результаты
У паттерна стратегия есть следующие достоинства и недостатки:
- С помощью стратегий можно избавиться от условных операторов. Благодаря паттерну стратегия удается отказаться от условных операторов при выборе нужного поведения. Когда различные поведения помещаются в один класс, трудно выбрать нужное без применения условных операторов. Инкапсуляция же каждого поведения в отдельный класс Strategy решает эту проблему. Так, без использования стратегий код для разбиения текста на строки мог бы выглядеть следующим образом:
void Composition::Repair ()
{
switch (_breakingStrategy) {
case SimpleStrategy:
ComposeWithSimpleCompositor();
break;
case TeXStrategy:
ComposeWithTeXCorapositor();
break;
// ...
}
// если необходимо, объединить результаты
// с имеющейся композицией
}
Паттерн стратегия позволяет обойтись без оператора переключения за счет делегирования задачи разбиения на строки объекту Strategy:
void Composition::Repair ()
{
_compositor->Compose();
// если необходимо, объединить результаты
// с имеющейся композицией
}
Если код содержит много условных операторов, то часто это признак того, что нужно применить паттерн стратегия;
- Выбор реализации. Стратегии могут предлагать различные реализации одного и того ж- поведения. Клиент вправе выбирать подходящую стратегию в зависимости от своих требований к быстродействию и памяти;
- Клиенты должны «знать» о различных стратегиях. Потенциальный недостаток этого паттерна в том, что для выбора подходящей стратегии клиент должен понимать, чем отличаются разные стратегии. Поэтому наверняка придется раскрыть клиенту некоторые особенности реализации. Отсюда следует, что паттерн стратегия стоит применять лишь тогда, когда различия в поведении имеют значение для клиента;
- Обмен информацией между стратегией и контекстом. Интерфейс класса Strategy разделяется всеми подклассами ConcreteStrategy - неважно, сложна или тривиальна их реализация. Поэтому вполне вероятно, что некоторые стратегии не будут пользоваться всей передаваемой им информацией, особенно простые. Это означает, что в отдельных случаях контекст создаст и проинициализирует параметры, которые никому не нужны. Если возникнет проблема, то между классами Strategy и Context придется установить более тесную связь;
2.4.6 Паттерн Template Method
Название
Template Method (шаблонный метод).
Задача
Шаблонный метод определяет основу алгоритма и позволяет подклассам переопределить некоторые шага алгоритма, не изменяя его структуру в целом.
Мотивация
Рассмотрим каркас приложения, в котором имеются классы Application Document. Класс Application отвечает за открытие существующих документов, хранящихся во внешнем формате, например в виде файла. Объект класса Document представляет информацию документа после его прочтения из файла.
Приложения, построенные на базе этого каркаса, могут порождать подклассы от классов Application и Document, отвечающие конкретным потребностям. Например, графический редактор определит подклассы DrawApplication и DrawDocument, а электронная таблица - подклассы SpreadsheetApplication и SpreadsheetDocument.
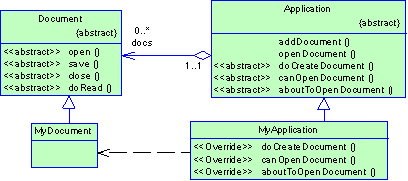
Рисунок 2.33 Структура паттерна Template Method (пример)
В абстрактном классе Application определен алгоритм открытия и считывания документа в операции OpenDocument;
void Application::openDocument (const char* name)
{
if (!CanOpenDocument(name)) {
// работа с этим документом
// невозможна return;
}
Document* doc = DoCreateDocument();
if (doc) {
_docs->AddDocument(doc);
AboutToOpen Document (doc);
doc->0pen();
doc->DoRead();
}
}
Операция openDocument определяет все шаги открытия документа. Она проверяет, можно ли открыть документ, создает объект класса Document, добавляет его к набору документов и считывает документ из файла.
Операцию вида openDocument мы будем называть шаблонным методом, описывающим алгоритм в терминах абстрактных операций, которые замещены в подклассах для получения нужного поведения. Подклассы класса Application выполняют проверку возможности открытия (canOpenDocument) и создания документ (doCreateDocument). Подклассы класса Document считывают документ (doRead). Шаблонный метод определяет также операцию, которая позволяет подклассам Application получить информацию о том, что документ вот-вот будет открыт (aboutToOpenDocurnent). Определяя некоторые шаги алгоритма с помощью абстрактных операций, шаблонный метод фиксирует их последовательность, но и позволяет реализовать их в подклассах классов Application и Document.
Структура

Рисунок 2.34 Структура паттерна Template Method
- AbstractClass (Application) - абстрактный класс: - определяет абстрактные примитивные операции, замещаемые в конкретных подклассах для реализации шагов алгоритма; реализует шаблонный метод, определяющий скелет алгоритма. Шаблонный метод вызывает примитивные операции, а также операции, определенные в классе AbstractClass или в других объектах;
- ConcreteClass (MyApplication) - конкретный класс: реализует примитивные операции, выполняющие шаги алгоритма способом, который зависит от подкласса.
Результаты
Шаблонные методы - один из фундаментальных приемов повторного использования кода. Они особенно важны в библиотеках классов, поскольку предоставляют возможность вынести общее поведение в библиотечные классы.
Шаблонные методы приводят к инвертированной структуре кода, которую иногда называют принципом Голливуда, подразумевая часто употребляемую в этой кино-империи фразу «Не звоните нам, мы сами позвоним». В данном случае это означает, что родительский класс вызывает операции подкласса, а не наоборот.
Шаблонные методы вызывают операции следующих видов:
- конкретные операции (либо из класса ConcreteClass, либо из классов клиента);
- конкретные операции из класса AbstractClass (то есть операции, полезные всем подклассам);
- примитивные операции (то есть абстрактные операции);
- фабричные методы (см. паттерн фабричный метод);
- операции-зацепки (hook operations), реализующие поведение по умолчанию, которое может быть расширено в подклассах. Часто такая операция по умолчанию не делает ничего.
Важно, чтобы в шаблонном методе четко различались операции-зацепки (которые можно замещать) и абстрактные операции (которые нужно замещать). Чтобы повторно использовать абстрактный класс с максимальной эффективностью, авторы подклассов должны понимать, какие операции предназначены для замещения.
Подкласс может расширить поведение некоторой операции, заместив ее и явно вызвав эту операцию из родительского класса:
void DerivedClass::0peration ()
{
ParentClass::Operation));
// Расширенное поведение класса DerivedClass
}
К сожалению, очень легко забыть о необходимости вызывать унаследованную операцию. У нас есть возможность трансформировать такую операцию в шаблонный метод с целью предоставить родителю контроль над тем, как подклассы расширяют его. Идея в том, чтобы вызывать операцию-зацепку из шаблонного метода в родительском классе. Тогда подклассы смогут переопределить именно эту операцию:
void ParentClass::Operation ()
{
// Поведение родительского класса ParentClass
HookOperation();
}
В родительском классе ParentClass операция Hook0peration не делает ничего:
void ParentClass::HookOperation ()
{
}
Но она замещена в подклассах, которые расширяют поведение:
void DerivedClass::HookOperation ()
{
// расширение в производном классе
}
2.4.7 Паттерн Chain Of Responsibility
Название
Chain Of Responsibility (цепочка обязанностей)
Назначение
Позволяет избежать привязки отправителя запроса к его получателю, давая шанс обработать запрос нескольким объектам. Связывает объекты-получатели в цепочку и передает запрос вдоль этой цепочки, пока его не обработают.
Мотивация
Рассмотрим контекстно-зависимую оперативную справку в графическом интерфейсе пользователя, который может получить дополнительную информацию по любой части интерфейса, просто щелкнув на ней мышью. Содержание справки зависит от того, какая часть интерфейса и в каком контексте выбрана. Например, справка по кнопке в диалоговом окне может отличаться от справки по аналогичной кнопке в главном окне приложения. Если для некоторой части интерфейса справки нет, то система должна показать информацию о ближайшем контексте, в котором она находится, например, о диалоговом окне в целом.
Поэтому естественно было бы организовать справочную информацию от более конкретных разделов к более общим. Кроме того, ясно, что запрос на получение справки обрабатывается одним из нескольких объектов пользовательского интерфейса, каким именно - зависит от контекста и имеющейся в наличии информации. Проблема в том, что объект, инициирующий запрос (например, кнопка), не располагает информацией о том, какой объект в конечном итоге предоставит справку. Нам необходим какой-то способ отделить кнопку-инициатор запроса от объектов, владеющих справочной информацией. Как этого добиться, показывает паттерн Цепочка обязанностей. Идея заключается в том, чтобы разорвать связь между отправителями и получателями, дав возможность обработать запрос нескольким объектам. Запрос перемещается по цепочке объектов, пока один из них не обработает его. Первый объект в цепочке получает запрос и либо обрабатывает его сам, либо направляет следующему кандидату в цепочке, который ведет себя точно так же. у объекта, отправившего запрос, отсутствует информация об обработчике. Мы говорим, что у запроса есть анонимный получатель (implicit receiver).
Предположим, что пользователь запрашивает справку по кнопке Print (печать). Она находится в диалоговом окне PrintDialog, содержащем информацию об объекте приложения, которому принадлежит (см. предыдущую диаграмму объектов). На представленной на рис. 2.34 диаграмме взаимодействий показано, как запрос на получение справки перемещается по цепочке.
Рисунок 2.35 Паттерн Chain of Responsibility. Отношения между объектами
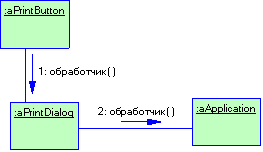
Рисунок 2.36 Паттерн Chain of Responsibility. Обработка сообщения
В данном случае ни кнопка aPrintButton, ни окно aPrintDialog не обрабатывают запрос, он достигает объекта anApplication, который может его обработать или игнорировать. У клиента, инициировавшего запрос, нет прямой ссылки на объект, который его в конце концов выполнит
Чтобы отравить запрос по цепочке и гарантировать анонимность получателя, все объекты в цепочке имеют единый интерфейс для обработки запросов и для доступа к своему преемнику (следующему объекту в цепочке). Например, в системе оперативной справки можно было бы определить класс HelpHandler (предок классов всех объектов-кандидатов или подмешиваемый класс (mixin class)) с операцией HandleHelp. Тогда классы, которые будут обрабатывать запрос, смогут его передать своему родителю.
Для обработки запросов на получение справки классы Button, PrintDialog и Application пользуются операциями HelpHandler. По умолчанию HandleHelp просто перенаправляет запрос своему преемнику. В подклассах эта операция замещается, так что при благоприятных обстоятельствах может выдаваться справочная информация. В противном случае запрос отправляется дальше посредством реализации по умолчанию.
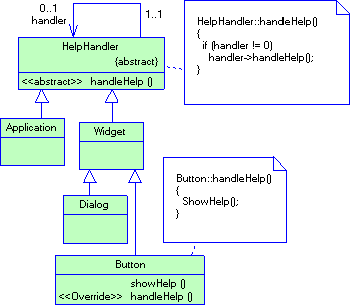
Рисунок 2.37 Структура паттерна Chain of Responsibility (пример)
Применимость
- Есть более одного объекта, способного обработать запрос, причем настоящий обработчик, заранее неизвестен и должен быть найден автоматически.
- Вы хотите отправить запрос
одному из нескольких объектов, не указывая явно, какому именно;
набор объектов, способных обработать запрос, должен задаваться динамически.
Структура
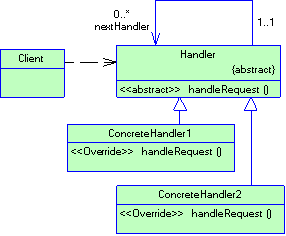
Рисунок 2.38 Структура паттерна Chain of Responsibility
Результаты
- Ослабление связанности. Этот паттерн освобождает объект от необходимости «знать», кто конкретно обработает его запрос. Отправителю и получателю ничего неизвестно друг о друге, а включенному в цепочку объекту о структуре цепочки. Таким образом, цепочка обязанностей помогает упростить взаимосвязи между объектами. Вместо того чтобы хранить ссылки на все объекты, которые могут стать получателями запроса, объект должен располагать информацией лишь о своем ближайшем преемнике;
- Дополнительная гибкость при распределении обязанностей между объектами. Цепочка обязанностей позволяет повысить гибкость распределения обязанностей между объектами. Добавить или изменить обязанности по обработке запроса можно, включив в цепочку новых участников или изменив ее каким-то другим образом. Этот подход можно сочетать со статическим порождением подклассов для создания специализированных обработчиков;
- Получение не гарантировано. Поскольку у запроса нет явного получателя, то нет и гарантий, что он вообще будет обработан: он может достичь конца цепочки и пропасть. Необработанным запрос может оказаться и в случае неправильной конфигурации цепочки.
2.4.8 Паттерн Command
Название
Command (команда), Action (действие), Transaction (транзакция)
Назначение
Инкапсулирует запрос как объект, позволяя тем самым задавать параметры Клиентов для обработки соответствующих запросов, ставить запросы в очередь или протоколировать их, а также поддерживать отмену операций.
Мотивация
Иногда необходимо посылать объектам запросы, ничего не зная о том, выполнение какой операции запрошено и кто является получателем. Например, в библиотеках для построения пользовательских интерфейсов встречаются такие объекты, как кнопки и меню, которые посылают запрос в ответ на действие пользователя. Но и саму библиотеку не заложена возможность обрабатывать этот запрос, так как только приложение, использующее ее, располагает информацией о том, что следует сделать. Проектировщик библиотеки не владеет никакой информацией о получателе запроса и о том, какие операции тот должен выполнить. Паттерн команда позволяет библиотечным объектам отправлять запросы неизвестным объектам приложения, преобразовав сам запрос в объект. Этот объект можно хранить и передавать, как и любой другой. В основе списываемого паттерна лежит абстрактный класс Command, в котором объявлен интерфейс для выполнения операций. В простейшей своей форме этот интерфейс состоит из одной абстрактной операции Execute. Конкретные подклассы Command определяют пару “получатель-действие”, сохраняя получателя в переменной экземпляра, и реализуют операцию Execute, так чтобы она посылала запрос. У получателя есть информация, необходимая для выполнения запроса.
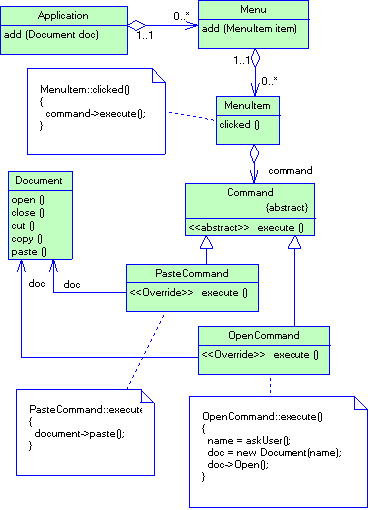
Рисунок 2.39 Структура паттерна Command (пример)
С помощью объектов Command легко реализуются меню. Каждый пункт меню -это экземпляр класса Menultem. Сами меню и все их пункты создает класс Application наряду со всеми остальными элементами пользовательского интерфейса. Класс Application отслеживает также открытые пользователем документы.
Приложение конфигурирует каждый объект Menultem экземпляром конкретного подкласса Command. Когда пользователь выбирает некоторый пункт меню, ассоциированный с ним объект Menultem вызывает Execute для своего объекта-команды, a Execute выполняет операцию. Объекты Menultem не имеют информации, какой подкласс класса Command они используют. Подклассы Command хранят информацию о получателе запроса и вызывают одну или несколько операций этого получателя.
Например, подкласс PasteCommand поддерживает вставку текста из буфера обмена в документ. Получателем для PasCeCommand является Document, который был передан при создании объекта. Операция Execute вызывает операцию Paste документа-получателя.
Для подкласса OpenCommand операция Execute ведет себя по-другому: она запрашивает у пользователя имя документа, создает соответствующий объект Document, извещает о новом документе приложение-получатель и открывает этот документ.
Иногда объект Menultem должен выполнить последовательность команд-Например, пункт меню для центрирования страницы стандартного размера можно было бы сконструировать сразу из двух объектов: CenterDocumentCommand и NormalsizeCommand. Поскольку такое комбинирование команд - явление обычное, то мы можем определить класс MacroCommand, позволяющий объекту Menultem выполнять произвольное число команд. MacroCommand - это конкретный подкласс класса Command, который просто выполняет последовательность команд. У него нет явного получателя, поскольку для каждой команды определен свой собственный.
Обратите внимание, что в каждом из приведенных примеров паттерн команда отделяет объект, инициирующий операцию, от объекта, который «знает», как ее выполнить. Это позволяет добиться высокой гибкости при проектировании пользовательского интерфейса. Пункт меню и кнопка одновременно могут быть ассоциированы в приложении с некоторой функцией, для этого достаточно приписать обоим элементам один и тот же экземпляр конкретного подкласса класса Command. Мы можем динамически подменять команды, что очень полезно для реализации контекстно-зависимых меню. Можно также поддержать сценарии, если компоновать простые команды в более сложные. Все это выполнимо потому, что объект, инициирующий запрос, должен располагать информацией лишь о том. как его отправить, а не о том, как его выполнить.
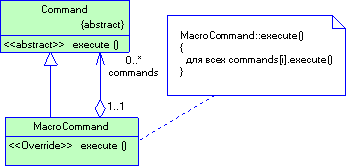
Рисунок 2.40. Паттерн Command. Макрокоманда.
Применимость
- хотите параметризовать объекты выполняемым действием, как в случае с пунктами меню Menultem. В процедурном языке такую параметризацию можно выразить с помощью функции обратного вызова, то есть такой функции, которая регистрируется, чтобы быть вызванной позднее. Команды представляют собой объектно-ориентированную альтернативу функциям обратного вызова;
- нужно определять, ставить в очередь и выполнять запросы в разное время. Время жизни объекта Command необязательно должно зависеть от времени жизни исходного запроса. Если получателя запроса удается реализовать так, чтобы он не зависел от адресного пространства, то объект-команду можно передать другому процессу, который займется его выполнением;
- хотите поддержать отмену операций. Операция Execute объекта Command может сохранить состояние, необходимое для отката действий, выполненных командой. В этом случае в интерфейсе класса Command должна быть дополнительная операция Unexecute, которая отменяет действия, выполненные предшествующим обращением к Execute. Выполненные команды хранятся в списке истории. Для реализации произвольного числа уровней отмены и повтора команд нужно обходить этот список соответственно в обратном и прямом направлениях, вызывая при посещении каждого элемента команду Unexecute или Execute;
- хотите поддержать протоколирование изменений, чтобы их можно было выполнить повторно после аварийной остановки системы. Дополнив интерфейс класса Command операциями сохранения и загрузки, вы сможете вести протокол изменений во внешней памяти. Для восстановления после сбоя нужно будет загрузить сохраненные команды с диска и повторно выполнить их с помощью операции Execute;
- необходимо структурировать систему на основе высокоуровневых операций, построенных из примитивных. Такая структура типична для информационных систем, поддерживающих транзакции. Транзакция инкапсулирует набор изменений данных. Паттерн команда позволяет моделировать транзакции. У всех команд есть общий интерфейс, что дает возможность работать одинаково с любыми транзакциями. С помощью этого паттерна можно легко добавлять в систему новые виды транзакций.
Результаты
- команда разрывает связь между объектом, инициирующим операцию, и объектом, имеющим информацию о том, как ее выполнить;
- команды - это самые настоящие объекты. Допускается манипулировать ими и расширять их точно так же, как в случае с любыми другими объектами;
- из простых команд можно собирать составные, например класс MacroCommand, рассмотренный выше. В общем случае составные команды описываются паттерном компоновщик;
- добавлять новые команды легко, поскольку никакие существующие классы изменять не нужно.
Структура
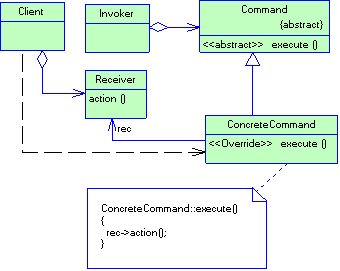
Рисунок 2.41 Структура паттерна Command
На следующей диаграмме (рис. 2.42) видно, как Command разрывает связь между инициатором и получателем (а также запросом, который должен выполнить последний).
2.4.9 Паттерн High Cohesion
Название
High Cohesion (слабое зацепление)
Проблема
В терминах объектно-ориентированного проектирования зацепление (cohesion) (или, более точно, функциональное зацепление) — это мера связанности и сфокусированности обязанностей класса. Считается, что элемент обладает высокой степенью зацепления, если его обязанности тесно связаны между собой и он не выполняет непомерных объемов работы.
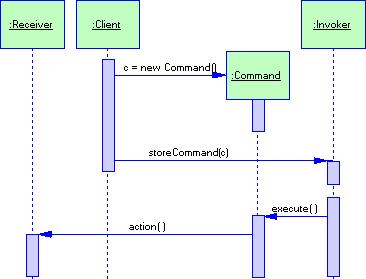
Рисунок 2.42 Паттерн Command. Взаимодействие объектов
В роли таких элементов могут выступать классы, подсистемы и т.д. Класс с низкой степенью зацепления выполняет много разнородных функций или несвязанных между собой обязанностей. Такие классы создавать нежелательно, поскольку они приводят к возникновению следующих проблем.
- Трудность понимания.
- Сложности при повторном использовании.
- Сложности поддержки.
- Ненадежность, постоянная подверженность изменениям.
Классы со слабым зацеплением, как правило, являются слишком "абстрактными" или выполняют обязанности, которые можно легко распределить между другими объектами.
Решение
Распределение обязанностей, поддерживающее высокую степень зацепления.
Результаты
- Повышаются ясность и простота проектных решений.
- Упрощаются поддержка и доработка.
- Зачастую обеспечивается слабое связывание.
- Улучшаются возможности повторного использования, поскольку класс с высокой степенью зацепления выполняет конкретную задачу.
Пример
Для анализа шаблона High Cohesion можно использовать тот же пример, что и для Low Coupling. Предположим, необходимо создать экземпляр объекта Payment и связать его с текущей продажей. Какой класс должен выполнять эту обязанность? Поскольку в реальной предметной области сведения о платежах записываются в реестре, согласно шаблону Creator, для создания экземпляра объекта Payment можно использовать объект Register. Тогда экземпляр объекта Register сможет отправить сообщение addPayment объекту Sale, передавая в качестве параметра новый экземпляр объекта Payment, как показано на рис. 2.43.
Рисунок 2.43 Пример диаграммы взаимодействия. Низкое зацепление
При таком распределении обязанностей платежи выполняет
объект Register, т.е. объект Register частично несет ответственность за
выполнение системной операции makePayment.
В данном обособленном примере это приемлемо. Однако если и далее возлагать на
класс Register обязанности по выполнению все новых и новых функций, связанных с
другими системными операциями, то этот класс будет слишком перегружен и будет обладать
низкой степенью зацепления. Предположим, приложение должно выполнять пятьдесят
системных операций и все они возложены на класс Register. Если этот объект
будет выполнять все операции, то он станет чрезмерно "раздутым" и не
будет обладать свойством: зацепления. И дело не в том, что одна задача создания
экземпляра объекта Payment сама по себе снизила степень зацепления объекта
Register; она является частью общей картины распределения обязанностей.
Рисунок 2.44 Пример диаграммы взаимодействия. Высокое зацепление
На рис 2.44 представлен другой вариант распределения обязанностей. Здесь функция создания экземпляра платежа делегирована объекту Sale. Благодаря этому поддерживается более высокая степень зацепления объекта Register. Поскольку такой вариант распределения обязанностей обеспечивает низкий уровень связывания и более высокую степень зацепления, он является более предпочтительным. На практике уровень зацепления не рассматривают изолированно от других обязанностей и принципов, обеспечиваемых шаблонами Expert и Low Coupling.
Когда не следует применять шаблон
Существует несколько случаев, когда низкое зацепление оказывается оправданным. Одна из таких ситуаций возникает в том случае, когда обязанности или код группируются в одном классе или компоненте для упрощения его поддержки одним человеком. Однако в данном случае необходимо помнить о том, что такая группировка может привести и к усложнению поддержки. Например, предположим, что в приложении содержатся внедренные операторы SQL, которые в соответствии с другими шаблонами проектирования нужно распределить по десяти классам работы с базой данных. В этом случае лишь один или два эксперта в области SQL знают, как лучше всего определять и поддерживать эти операторы SQL, даже несмотря на то, что в проекте участвуют десятки программистов с опытом работы в области объектно-ориентированного программирования. Некоторые из них могут иметь достаточно высокий уровень знания объектно-ориентированных технологий. Предположим также, что эксперт в области SQL не обладает навыками программиста по созданию объектно-ориентированных программ. Архитектор программной системы может решить сгруппировать операторы SQL в одном классе RDBOperations, чтобы эксперту было легче работать с этими операторами в одном месте.
Другой пример слабого зацепления имеет отношение к распределенным серверным объектам. Поскольку быстродействие системы определяется производительностью удаленных объектов и их взаимодействием, иногда желательно создать несколько более крупных серверных объектов со слабым зацеплением, предоставляющих интерфейс многим операциям. Эта ситуация связана также с шаблоном Coarse-Grained Remote Interface (Укрупненный удаленный интерфейс), в рамках которого создаются укрупненные удаленные операции, выполняющие больше функций. Такое проектное решение объясняется повышенным влиянием удаленных вызовов на производительность сети. В качестве альтернативы вместо удаленного объекта с тремя операциями setName, setSalary и setHireDate лучше реализовать одну укрупненную удаленную операцию setDate, работающую с целым множеством данных. Это приведет к уменьшению числа удаленных вызовов и, как следствие, к повышению производительности.
2.4.10 Паттерн Don’t Talk To Strangers
Название
Don’t Talk to Strangers (не разговаривай с незнакомцами). Известен, так же, под именем Law of Demeter (Закон Деметры)
Описание
Паттерн этот один из самых простых, так как формализован до уровня “Делай то, не делай это”. Предназначен паттерн, как и предыдущий, для обеспечения высокого зацепления и низкой связности. Паттерн регламентирует, каким объектам, метод нашего объекта может посылать сообщения. Таковыми являются:
- Объекту this (self).
- Параметрам метода.
- Атрибуту объекта this (self).
- Элементу контейнера, являющемуся атрибутом this (self).
- Объекту, созданному внутри метода.
Все перечисленные объекты называются прямыми объектами. Все остальные – непрямые. Отсюда можно сказать, что в соответствии с паттерном Don’t Talk to Strangers, метод объекта может посылать сообщения только прямым объектам и некому более. Для выполнения этого требования прямым объектам могут понадобиться новые операции, которые выступают в роли дополнительных операций, позволяющих избежать разговора с незнакомцами.
Рассмотрим пример. Предположим, что в приложении розничной торговли экземпляр класса POST, имеет атрибут, ссылающийся на объект Sale, атрибут которого, в свою очередь, ссылается на объект Payment (см. рис. 2.45).
При способе взаимодействия объектов, представленном на рис. 2.47, мы имен нарушение условий паттерна Don’t Talk to Strangers. Объект POST посылает сообщение объекту Payment, хотя по условиям паттерна он не должен этого делать.
Во втором случае, условия паттерна выполняются. Но, для этого нам пришлось добавить в интерфейс объекта Sale еще один метод (paymentAmount). Такой ход называется обеспечением интерфейса (promoting the interface) и является общим решением данной проблемы.
Результаты
Благодаря паттерну Don’t Talk to Strangers нет необходимости обеспечивать видимость непрямых объектов, что в свою очередь повышает зацепление и понижает степень связности объектов.
Нарушение закона
Естественно, бывают случаи, когда условия паттерна можно (и нужно) проигнорировать. Например, при обращении объекта к объекту, организованному в соответствии с паттерном Singleton. В любом случае – Ваша задача добиться максимальной гибкости решение, а не тупо следовать рекомендациям
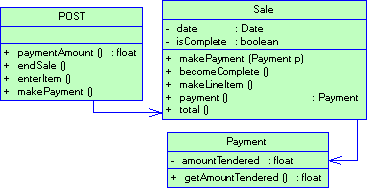
Рисунок 2.45. Система POST. Фрагмент диаграммы классов
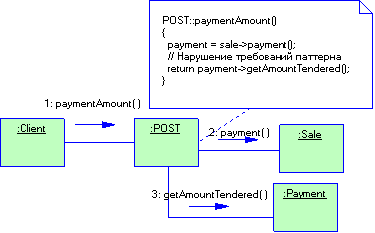
Рисунок 2.46 Способов взаимодействия объектов, нарушающий закон Деметры.
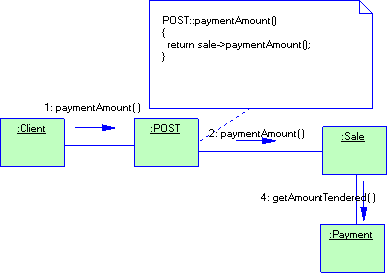
Рисунок 2.47 Способов взаимодействия объектов, не нарушающий закон Деметры.
2.4.11 Паттерн Polymorphism
Название
Polymorphism (полиморфизм).
Задача
С помощью полиморфных операций позволяет обеспечить изменяемое поведение без проверки типа. Данный паттерн является обобщением нескольких GoF-паттернов.
Решение
Условная передача управления – основной элемент любой программы. Если программа разработана с использованием условных операторов типа if-then-else, или switch-case, то при добавлении новых вариантов поведения приходится модифицировать логику условных операторов. Такой подход усложняет процесс модификации программы в соответствии с новыми вариантами поведения, поскольку изменения приходится вносить сразу в нескольких местах программного кода – там, где используются условные операторы.
Паттерн Polymorphism описывает такой способ построения системы, при котором зависящие от типа варианты поведения реализуются посредством виртуальных операций.
Пример
Рассмотрим все ту же систему розничной торговли. Предположим, что оплата в этой системе может проводиться несколькими способами: наличными (CashPayment), чеком (CheckPayment) или по кредитной карте (CreditPayment). Согласно шаблону Polymorphism необходимо распределить обязанности по авторизации каждого из типа платежей. Для этого можно использовать полиморфную операцию authorize (см. рис. 2.48). Реализации каждой такой операции будут различны. Например, объект CreditPayment должен взаимодействовать со службой авторизации кредитных платежей и т.д.
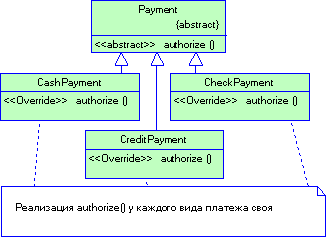
Рисунок 2.48 Структура паттерна Polymorphism (пример)
Результаты
- Паттерн позволяет легко расширять систему, добавляя в нее новое поведение и не изменяя при этом клиентов, относительно этого поведения.
2.4.12 Паттерн Pure Fabrication
Название
Pure Fabrication (чистая синтетика)
Задача
Начну из далека. Объектно-ориентированные системы характерны тем, что программные классы часто реализуют понятия деловой среды, как например, Sale (продажа) и Employee (сотрудник). Однако, существует множество ситуаций, когда распределение обязанностей только между такими классами приводит к сильным связыванием и слабым зацеплением. Именно в таких ситуациях решением проблемы может явиться паттерн Pure Fabrication.
Решение
Присвоить группу обязанностей с высокой степенью зацепления искусственному классу, не представляющему конкретного понятия их деловой среды, т.е. синтезировать искусственную сущность для поддержки высокого зацепления, низкой связности и, как результат этого, повторного использования.
Пример
Предположим, необходимо сохранять экземпляры класса Sale в базе данных. Согласно шаблону Expert эту обязанность можно присвоить самому классу Sale. Однако следует принимать во внимание следующие моменты.
- Данная задача требует выполнения достаточно большого количества специализированных операций, связанных со взаимодействием с базой данных и не как не связанных с понятием самой продажи. Поэтому класс Sale получает низкую степень зацепления.
- Класс Sale, при условии, что он сам сохраняет себя в БД, должен быть связан с интерфейсом БД. Поэтому возрастает степень связности, причем даже не с другим объектом деловой среды, а с интерфейсом БД.
- Хранение объектов в БД – это достаточно общая задача, решение которой необходимо для многих классов. Возлагая эту обязанность на класс Sale, разработчик не обеспечивает возможности повторного использования данный операций и вынужден дублировать их во многих классах.
Поэтому, несмотря на то, что по логике вещей класс Sale является хорошим кандидатом для выполнения обязанностей сохранения самого себя в БД, такое распределение обязанностей приводит низкой степени зацепления, высокой связности и невозможности повторного использования кода.
Естественным решением данной проблемы является создание нового класса, ответственного за сохранение объектов некоторого вида на постоянном носителе. Этот класс не выявляется из деловой среды, его там нет, он является продуктом нашего воображения и не более.
Естественно, организация хранения состояния объектов в БД – далеко не единственная задача, для решения которой может пригодиться паттерн Pure Fabrication. Многие GRASP паттерны построены на этой идее – Adapter, Visitor, Observer. Подводя итог применимости Pure Fabrication можно сказать, что с помощью этого паттерна обеспечиваются решения задач, не имеющих аналогий в деловой среде, но возникающих при программировании.
Pure Fabrication относится к абстракциям поведения (напоминаю, это вторые по полезности абстракции после абстракций сущностей).
Результаты
Обеспечиваются паттерны Low Coupling и High Cohesion.
2.4.13 Паттерн Controller
Проблема
Кто должен отвечать за обработку входных системных событий?
Системное событие (system event) — это событие высокого уровня, генерируемое внешним исполнителем (событие с внешним входом). Системные события связаны с системными операциями (system operation), т.е. операциями, выполняемыми системой в ответ на события.
Например, когда кассир в POS-системе щелкните на кнопке Оплатить, он генерирует системное событие, свидетельствующее о завершении торговой операции. Аналогично, когда пользователь текстового процессора выбирает команду Орфография, он генерирует системное событие "выполнить проверку орфографии".
Контроллер (controller) — это объект, не относящийся к интерфейсу пользователя и отвечающий за обработку системных событий. Контроллер определяет методы для выполнения системных операций.
Решение
Делегирование обязанностей по обработке системных сообщений классу, удовлетворяющему одному из следующих условий.
- Класс представляет всю систему в целом, устройство или подсистему (внешний контроллер).
- Класс представляет сценарий некоторого прецедента, в рамках которого выполняется обработка всех системных событий, и обычно называется <Прецедент>Наndlег,<Прецедент>Coordinator или <Прецедент> Session (контроллер прецедента или контроллер сеанса).
- Для всех системных событий в рамках одного сценария прецедента используется один и тот же класс-контроллер.
- Неформально, сеанс — это экземпляр взаимодействия с исполнителем. Сеансы могут иметь произвольную длину, но зачастую организованы в рамках прецедента (сеансы прецедента).
Следствие. Заметим, что в этот перечень не включаются классы, реализующие окно, аплет, приложение, вид и документ. Такие классы не выполняют задачи, связанные с системными событиями. Они обычно получают сообщения и делегируют их контроллерам.
Преимущества
Улучшение условий для повторного использования компонентов. Применение этого шаблона обеспечивает обработку процессов предметной области на уровне реализации объектов, а не на уровне интерфейса. Обязанности контроллера могут быть технически реализованы в объектах интерфейса, однако в этом случае программный код и логические решения, относящиеся к процессам предметной области, будут жестко связаны с элементами интерфейса, например с окнами. При этом снижается эффективность повторного использования компонентов в других приложениях, поскольку процессы предметной области ограничены рамками интерфейса (например, связаны с оконным объектом), что может оказаться неприемлемым в других прило жениях. Делегирование выполнения системных операций специальному контроллеру облегчает повторное использование логики обработки подобных процессов в последующих приложениях.
Контроль состояния прецедента. Иногда необходимо удостовериться, что системные операции выполняются в некоторой определенной последовательности. Например, необходимо гарантировать, чтобы операция makePayment выполнялась только после операции EndSale, для чего необходимо накапливать информацию о последовательности событий. Для этой цели удобно использовать контроллер, особенно контроллер прецедента.
Раздутый контроллер
Плохо спроектированный класс контроллера имеет низкую степень зацепления: он выполняет слишком много обязанностей и является несфокусированным. Такой контроллер называется раздутым (bloated controller). Признаки раздутого контроллера таковы.
В системе имеется единственный класс контроллера, получающий все системные сообщения, которых поступает слишком много. Такая ситуация зачастую возникает при использовании внешнего контроллера.
Контроллер сам выполняет все задачи, не делегируя обязанности другим классам. Обычно это приводит к нарушению основных принципов шаблонов Information Expert и High Cohesion.
Контроллер имеет много атрибутов и содержит значительный объем информации о системе или предметной области, которую необходимо распределить между другими объектами, либо дублирует информацию, хранящуюся в других объектах.
3 Архитектурные паттерны
Одно из странных свойств, присущих индустрии программного обеспечения, связано с тем, что какой-либо термин может иметь множество противоречивых толкований. Так, термин "архитектура" пытаются трактовать все, кому не лень, и всяк на свой лад. Впрочем, можно назвать два общих варианта. Первый связан с разделением системы на наиболее крупные составные части; во втором случае имеются в виду некие конструктивные решения, которые после их принятия с трудом поддаются изменению. Также растет понимание того, что существует более одного способа описания архитектуры и степень важности каждого из них меняется в продолжение жизненного цикла системы. Архитектура - весьма субъективное понятие. В лучшем случае оно отображает общую точку зрения команды разработчиков на результаты проектирования системы. Обычно это согласие в вопросе идентификации главных компонентов системы и способов их взаимодействия, а также выбор таких решений, которые интерпретируются как основополагающие и не подлежащие изменению в будущем. Если позже оказывается, что нечто изменить легче, чем казалось вначале, это "нечто" легко исключается из "архитектурной" категории.
Архитектурные паттерны рассматривают вопросы посвященные тому, как осуществить декомпозицию системы по слоям (layers) и как обеспечить надлежащее взаимодействие слоев между собой. Многие паттерны, рассмотренные ниже, можно определенно считать "архитектурными" в том смысле, что они представляют "значимые" составные части приложения и/или "основополагающие" аспекты функционирования этих частей. Другие относятся к вопросам реализации.
3.1 Расслоение системы
Концепция слоев (layers) — одна из общеупотребительных моделей, используемых разработчиками программного обеспечения для разделения сложных систем на более простые части. В архитектурах компьютерных систем, например, различают слои кода на языке программирования, функций операционной системы, драйверов устройств, наборов инструкций центрального процессора и внутренней логики чипов. В среде сетевого взаимодействия протокол FTP работает на основе протокола TCP, который, в свою очередь, функционирует "поверх" протокола IP, расположенного "над" протоколом Ethernet. Описывая систему в терминах архитектурных слоев, удобно воспринимать составляющие ее подсистемы в виде "слоеного пирога". Слой более высокого уровня пользуется службами, предоставляемыми нижележащим слоем, но тот не "осведомлен" о наличии соседнего верхнего слоя. Более того, обычно каждый промежуточный слой "скрывает" нижний слой от верхнего: например, слой 4 пользуется услугами слоя 3, который обращается к слою 2, но слой 4 не знает о существовании слоя 2. (Не в каждой архитектуре слои настолько "непроницаемы", но в большинстве случаев дело обстоит именно так). Расчленение системы на слои предоставляет целый ряд преимуществ.
- Отдельный слой можно воспринимать как единое самодостаточное целое, не особенно заботясь о наличии других слоев (скажем, для создание службы FTP необходимо знать протокол TCP, но не тонкости Ethernet).
- Можно выбирать альтернативную реализацию базовых слоев (приложения FTP способны работать без каких либо изменений в среде Ethernet, по соединению РРР или в любой другой среде передачи информации).
- Зависимость между слоями можно свести к минимуму. Так, при смене среды пере дачи информации (при условии сохранения функциональности слоя IP) служба FTP будет продолжать работать как ни в чем не бывало.
- Каждый слой является удачным кандидатом на стандартизацию (например, TCP и IP — стандарты, определяющие особенности функционирования соответствую щих слоев системы сетевых коммуникаций).
- Созданный слой может служить основой для нескольких различных слоев более высокого уровня (протоколы TCP/IP используются приложениями FTP, telnet, SSH и HTTP). В противном случае для каждого протокола высокого уровня пришлось бы изобретать собственный протокол низкого уровня.
Схема расслоения обладает и определенными недостатками.
- Слои способны удачно инкапсулировать многое, но не все: модификация одного слоя подчас связана с необходимостью внесения каскадных изменений в остальные слои. Классический пример из области корпоративных программных приложений: поле, добавленное в таблицу базы данных, подлежит воспроизведению в графическом интерфейсе и должно найти соответствующее отображение в каждом промежуточном слое.
- Наличие избыточных слоев нередко снижает производительность системы. При переходе от слоя к слою моделируемые сущности обычно подвергаются преобразованиям из одного представления в другое. Несмотря на это, инкапсуляция нижележащих функций зачастую позволяет достичь весьма существенного преимущества. Например, оптимизация слоя транзакций обычно приводит к повышению производительности всех вышележащих слоев. Однако самое трудное при использовании архитектурных слоев — это определение содержимого и границ ответственности каждого слоя.
3.1.1.1 Развитие модели слоев в корпоративных программных приложениях
Понятие слоя приобрело очевидную значимость в середине 1990-х годов с появлением систем клиент/сервер (client/server). Это были системы с двумя слоями: клиент нес ответственность за отображение пользовательского интерфейса и выполнение кода приложения, а роль сервера обычно поручалась СУБД. Клиентские приложения создавались с помощью таких инструментальных средств, как Visual Basic, PowerBuilder и Delphi, предоставлявших в распоряжение разработчика все необходимое, включая экранные компоненты, обслуживающие интерфейс SQL: для конструирования окна было достаточно перетащить на рабочую область необходимые управляющие элементы, настроить параметры доступа к базе данных и подключиться к ней, используя таблицы свойств.
Если задачи сводились к простым операциям по отображению информации из базы данных и ее незначительному обновлению, системы клиент/сервер действовали безотказно. Проблемы возникли с усложнением логики предметной области — бизнес-правил, алгоритмов вычислений, условий проверок и т.д. Прежде все эти обязанности возлагались на код клиента и находили отражение в содержимом интерфейсных экранов. Чем сложнее становилась логика, тем более неуклюжим и трудным для восприятия делался код. Воспроизведение элементов логики на экранах приводило к дублированию кода, и тогда при необходимости внести простейшее изменение приходилось "прочесывать" всю программу в поисках одинаковых фрагментов.
Одной из альтернатив было описание логики в тексте хранимых процедур, размещаемых в базе данных. Языки хранимых процедур, однако, отличались ограниченными возможностями структуризации, что вновь негативно сказывалось на качестве кода. Помимо того, многие отдали предпочтение реляционным системам баз данных, поскольку используемый в них стандартизованный язык SQL открывал возможности безболезненного перехода от одной СУБД к другой. Хотя воспользовались ими на практике только единицы, мысль о возможной смене поставщика СУБД, не связанной со сколько-нибудь ощутимыми затратами, согревала всех. А наличие жесткой зависимости языков хранимых процедур от конкретных версий систем фактически разрушало эти надежды.
По мере роста популярности систем клиент/сервер набирала силу и парадигма объектно-ориентированного программирования, давшая сообществу ответ на сакраментальный вопрос о том, куда "девать" бизнес-логику: перейти к системной архитектуре с тремя слоями, в которой слой представления отводится пользовательскому интерфейсу, слой предметной области предназначен для описания бизнес-логики, а третий слой представляет источник данных. В этом случае удалось бы разнести интерфейс и логику, поместив последнюю на отдельный уровень, где она может быть структурирована с помощью соответствующих объектов.
Несмотря на предпринятые усилия, движение под знаменем объектной ориентации в направлении трехуровневой архитектуры было еще слишком робким и неуверенным. Многие проекты оказывались чрезмерно простыми, что отнюдь не вызывало у программистов желания покинуть наезженную колею систем клиент/сервер и связать себя новыми обязательствами. Помимо того, средства разработки приложений клиент/сервер с трудом поддерживали трехуровневую модель вычислений либо не предоставляли подобных инструментов вовсе.
Радикальный сдвиг произошел с появлением Web. Всем внезапно захотелось иметь системы клиент/сервер, где в роли клиента выступал бы Web-обозреватель. Если, однако, вся бизнес-логика приложения сосредоточивалась в коде толстого клиента, при переходе к Web-интерфейсу приходилось пересматривать ее полностью. А в удачно спроектированной трехуровневой системе достаточно было просто заменить уровень представления, не затрагивая слой предметной области. Позже, с появлением Java, все увидели объектно-ориентированный язык, претендующий на всеобщее признание. Появившиеся инструментальные средства конструирования Web-страниц были в меньшей степени связаны с SQL и потому более подходили для реализации третьего уровня.
При обсуждении вопросов расслоения программных систем нередко путают понятия слоя (layer) и уровня, или яруса (tier). Часто их употребляют как синонимы, но в большин-стве случаев термин уровень трактуют, подразумевая физическое разделение. Поэтому системы клиент/сервер обычно описывают как двухуровневые (в общем случае "клиент" действительно отделен от сервера физически): клиент - это приложение для настольной машины, а сервер — процесс, выполняемый сетевым компьютером-сервером. Я применяю термин слой, чтобы подчеркнуть, что слои вовсе не обязательно должны располагаться на разных машинах. Отдельный слой бизнес-логики может функционировать как на персональном компьютере "рядом" с клиентским слоем интерфейса, так и на сервере базы данных. В подобных ситуациях речь идет о двух узлах сети, но о трех слоях или уровнях. Если база данных локальна, все три слоя могут соседствовать и на одном компьютере, но даже в этом случае они должны сохранять свой суверенитет.
3.1.1.2 Три основных слоя
Мы уже говорили с Вами о расслонеии системы на уровне (или слои, layers), когда обсуждали вопросы связанные с моделью проекта. Тогда мы ввели 4 слоя: представления, бизнес-объектов (или домен), промежуточного ПО (часто его называют источник данных) и системного ПО. Рассмотрим подробее верхние три уровня (уровень системного ПО, настолько сильно зависит от программной и аппаратной платформы, что его рассмотрение будет либо слишком узким (если говорить лишь об одной платформе) либо слишком объекным для этого курса (если попытаться рассмотреть хотя бы несколько вариантов) . И так, акцентируем наше внимание на архитектуре с тремя основными слоями: представление (presentation), домен (предметная область, бизнес-логика) (domain) и источник данных (data source). В таблице приведено их краткое описание
|
Слой |
Функции |
|
Представление |
Предоставление услуг, отображение данных, обработка событий пользовательского интерфейса (щелчков кнопками мыши и нажатий клавиш), обслуживание запросов HTTP, поддержка функций командной строки и API пакетного выполнения |
|
Домен |
Бизнес-логика приложения
|
|
Источник данных |
Обращение к базе данных, обмен сообщениями, управление транзакциями и т.д. |
Слой представления охватывает все, что имеет отношение к общению пользователя с системой. Он может быть настолько простым, как командная строка или текстовое меню, но сегодня пользователю, вероятнее всего, придется иметь дело с графическим интерфейсом, оформленным в стиле толстого клиента (Windows, Swing и т.п.) или основанным на HTML. К главным функциям слоя представления относятся отображение информации и интерпретация вводимых пользователем команд с преобразованием их в соответствующие операции в контексте домена (бизнес-логики) и источника данных.
Источник данных — это подмножество функций, обеспечивающих взаимодействие со сторонними системами, которые выполняют задания в интересах приложения. Код этой категории несет ответственность за мониторинг транзакций, управление другими приложениями, обмен сообщениями и т.д. Для большинства корпоративных приложений основная часть логики источника данных сосредоточена в коде СУБД.
Логика домена {бизнес-логика или логика предметной области) описывает основные функции приложения, предназначенные для достижения поставленной перед ним цели. К таким функциям относятся вычисления на основе вводимых и хранимых данных, проверка всех элементов данных и обработка команд, поступающих от слоя представления, а также передача информации слою источника данных.
Иногда слои организуют таким образом, чтобы бизнес-логика полностью скрывала источник данных от представления. Чаще, однако, код представления может обращаться к источнику данных непосредственно. Хотя такой вариант менее безупречен с теоретической точки зрения, в практическом отношении он нередко более удобен и целесообразен: код представления может интерпретировать команду пользователя, активизировать функции источника данных для извлечения подходящих порций информации из базы данных, обратиться к средствам бизнес-логики для анализа этой информации и осуществления необходимых расчетов и только затем отобразить соответствующую картинку на экране.
Часто в рамках приложения предусматривают несколько вариантов реализации каждой из трех категорий логики. Например, приложение, ориентированное на использование как интерфейсных средств толстого клиента, так и командной строки, может (и, вероятно, должно) быть оснащено двумя соответствующими версиями логики представления. С другой стороны, различным базам данных могут отвечать многочисленные слои источников данных. На отдельные "пакеты" может быть поделен даже слой бизнес-логики (скажем, в ситуации, когда алгоритмы расчетов зависят от типа источника данных).
Хотя три основных слоя - представление, бизнес-логика и источник данных - можно обнаружить в любом корпоративном приложении, способ их разделения зависит от степени сложности этого приложения. Простой сценарий извлечения порции информации из базы данных и отображения ее в контексте Web-страницы можно описать одной процедурой. Но я все равно попытался бы выделить в нем три слоя - пусть даже, как в этом случае, распределив функции каждого слоя по разным подпрограммам. При усложнении приложения это дало бы возможность разнести код слоев по отдельным классам, а позже разбить множество классов на пакеты. Форма расслоения может быть произвольной, но в любом корпоративном приложении слои должны быть идентифицированы.
Помимо необходимости разделения на слои, существует правило, касающееся взаимоотношения слоев: зависимость бизнес-логики и источника данных от уровня пред-ставления не допускается. Другими словами, в тексте приложения не должно быть вызовов функций представления из кода бизнес-логики или источника данных. Правило позволяет упростить возможность адаптации слоя представления или замены его альтернативным вариантом с сохранением основы приложения. Связь между бизнес-логикой и источником данных, однако, не столь однозначна и во многом определяется выбором типовых решений для архитектуры источника данных.
Самым сложным в работе над бизнес-логикой является, вероятно, выбор того, что именно и как следует относить к тому или иному слою. Мне нравится один неформальный тест. Вообразите, что в программу добавляется принципиально отличный слой, например интерфейс командной строки для Web-приложения. Если существует некий набор функций, которые придется продублировать для осуществления задуманного, значит, здесь логика домена "перетекает" в слой представления. Можно сформулировать тест иначе: нужно ли повторять логику при необходимости замены реляционной базы данных XML-файлом.
Хорошим примером ситуации является система, о которой мне когда-то рассказали. Представьте, что приложение отображает список выделенных красным цветом названий товаров, объемы продаж которых возросли более чем на 10% в сравнении с уровнем прошлого месяца. Допустим, программист разместил соответствующую логику непосредственно в слое представления, решив здесь же сопоставлять уровни продаж текущего и прошлого месяца и изменять цвет, если разность превышает заданный порог.
Проблема заключается в том, что в слой преставления вводится несвойственная ему логика предметной области. Чтобы надлежащим образом разделить слои, нужен метод бизнес-логики, отображающий факт превышения уровня продаж определенного продукта на заданную величину. Метод должен осуществить сравнение уровней продаж по двум месяцам и возвратить значение булева типа. В коде слоя представления достаточно вызвать этот метод и, руководствуясь полученным результатом, принять решение об изменении цвета отображения. В этом случае процесс разбивается на две части: выявление факта, который может служить основанием для изменения цвета, и собственно изменение.
А самое веселое состоит в том, что на самом деле верны оба вывода!
3.1.1.3 Где должны функционировать уровни
На протяжении этой, и последующих лекций речь идет о логических слоях, т.е. о расчленении системы на отдельные части. Подобное разделение полезно даже тогда, когда все слои функционируют на одной машине. Впрочем, существуют ситуации, где различия в поведении системы могут быть обусловлены принципами ее физической организации.
В большинстве случаев существует только два варианта размещения и выполнения компонентов корпоративных приложений - на персональном компьютере и на сервере.
Зачастую самым простым является функционирование кода всех слоев системы на сервере. Это становится возможным, например, при использовании HTML-интерфейса, воспроизводимого Web-обозревателем. Основным преимуществом сосредоточения всех частей приложения в одном месте является то, что при этом максимально упрощаются процедуры исправления ошибок и обновления версий. В этом случае не приходится беспокоиться о внесении соответствующих изменений на всех компьютерах, об их совместимости с другими приложениями и синхронизации с серверными компонентами.
Общие аргументы в пользу размещения каких-либо слоев на компьютере клиента состоят в повышении быстроты реагирования (responsiveness) приложения и в обеспечении возможности локальной работы. Чтобы код сервера смог отреагировать на действия, предпринимаемые пользователем на клиентской машине, требуется определенное время. А если пользователю необходимо быстро опробовать несколько вариантов и немедленно увидеть результат, продолжительность сетевого обмена становится серьезным препятствием. Помимо того, приложению требуется сетевое соединение как таковое. Может быть, в обозримом будущем так и случится, но что делать жителям какой-нибудь Тмутаракани, которые не желают ждать, пока кто-то из операторов беспроводной связи удосужится обеспечить "покрытие" их Богом забытого селения. А поддержка возможностей локального функционирования выдвигает особые требования, но боюсь, что они выбиваются из контекста этой книги.
Приняв к сведению все приведенные соображения, можно исследовать альтернативы, рассматривая слой за слоем. Слой источника данных лучше всегда располагать на сервере. Исключение составляет случай, когда функции сервера дублируются в коде "очень толстого" клиента для обеспечения средств локального функционирования системы. При этом предполагается, что изменения, вносимые в раздельные источники данных на клиентской машине и на сервере, подлежат синхронизации посредством механизма репликации. Однако, это уже тема для другого курса.
Решение о том, где должен функционировать слой представления, большей частью зависит от предпочтений в выборе типа пользовательского интерфейса. Применение интерфейса толстого клиента автоматически влечет за собой необходимость размещения слоя представления на клиентской машине. Использование Web-интерфейса означает, что логика представления сосредоточена на сервере. Существуют и исключения, например удаленное управление клиентским программным обеспечением (таким, как Х-сервер в UNIX) с запуском Web-сервера на настольном компьютере, но они редки.
Если речь идет о создании системы типа "поставщик-потребитель" ("business to customer" — В2С), у вас просто нет выбора. К серверу может подключиться любой, и вы вряд ли будете мириться с потерей посетителя только из-за того, что он использует какоето экзотическое программное или аппаратное обеспечение. Поэтому целесообразно все функции сконцентрировать на сервере, а клиенту передавать материал в формате HTML, полностью готовый для воспроизведения с помощью Web-обозревателя. Подобное архитектурное решение ограничено в том, что реализация самой незначительной логики пользовательского интерфейса требует обращения к серверу, а это не может не сказаться на быстроте реагирования приложения. Уменьшить зависимость от сервера можно за счет применения фрагментов кода на языках сценариев Web-обозревателя (подобных JavaScript) и загружаемых аплетов, но подобные меры снижают уровень совместимости обозревателей и вызывают другие проблемы. Чем более "чист" код HTML, тем проще жизнь.
Вряд ли ваша жизнь будет простой даже в том случае, если каждый из настольных компьютеров вашей компании настроен, как утверждает начальник отдела информационных технологий, "максимально тщательно". Необходимость поддержки клиентского программного обеспечения в актуальном состоянии и требование исключить даже малую вероятность его несовместимости с другими программами - это серьезные проблемы, которые проявляются и в тривиальных ситуациях.
Основной повод для применения интерфейсов толстого клиента - сложность задач и невозможность создания полноценных полезных приложений иной архитектуры. Однако популярность Web-интерфейсов неуклонно растет, а потребность в использовании толстых клиентов, напротив, снижается. Могу сказать одно: пользуйтесь Web-интерфейсами, если можете, и обращайтесь к средствам толстого клиента, если без них никак не обойтись.
А как быть с кодом бизнес-логики? Его можно активизировать или целиком на сервере, или полностью в контексте клиентской части, или используя смешанный стиль. И вновь вариант "все на сервере" наиболее привлекателен с точки зрения удобства сопровождения системы. Передача каких-либо бизнес-функций клиенту может быть обусловлена только, скажем, необходимостью повышения быстроты реагирования интерфейса системы или потребностью в средствах поддержки локального функционирования.
Если в рамках клиента необходимо выполнять какие-либо функции логики предметной области, прежде всего уместно рассмотреть возможность поручения клиенту всех таких функций. Подобный вариант очень похож на выбор интерфейса толстого клиента. Запуск Web-сервера на клиентской машине ненамного повысит быстроту реагирования приложения, хотя даст возможность использовать его в локальном режиме. Где бы ни находился код бизнес-логики, его следует сохранять в отдельных модулях, не связанных со слоем представления, используя одно из типовых решений - сценарий транзакции (Transaction Script) или модель предметной области (Domain Model). Передача клиенту всего кода бизнес-логики сопровождается - и это уже отмечалось - усложнением процедур обновления системы.
Расщепление множества бизнес-функций между сервером и клиентом выглядит как наихудшее решение, поскольку в общем случае затрудняет идентификацию того или иного фрагмента логики. Основная причина, побуждающая применять подобную архитектуру, может состоять в том, что клиенту необходимо владеть только какой-то частью бизнес-логики. Главное - изолировать эту порцию кода в отдельном модуле, не зависящем от других частей системы. Это даст возможность активизировать код и на компьютере клиента, и на сервере, если такая потребность возникнет позже. Такой подход, разумеется, требует дополнительных усилий, но они оправданны.
После выбора узлов обработки необходимо попытаться обеспечить выполнение всего кода, относящегося к каждому отдельному узлу, в рамках единого процесса, функционирующего либо на одном узле, либо в пределах кластера из нескольких узлов. Не стоит делить слои по разрозненным процессам, если в этом нет насущной необходимости. В противном случае вам придется иметь дело с решениями типа интерфейса удаленного доступа (Remote Facade) и объекта переноса данных (Data Transfer Object), а это чревато потерей производительности и повышением сложности.
Важно помнить, что подобные вещи относятся к числу тех, которые часто называют катализаторами сложности (complexity boosters): это распределенная обработка, многопоточные вычисления, сочетание радикально различных концепций (например, "объектной ориентации" и "реляционной модели"), межплатформенное взаимодействие и обеспечение предельно высокого уровня быстродействия. Решение любой из названных задач сопряжено с большими затратами. Конечно, иногда приходится их нести, но это должно рассматриваться как исключение, а не правило.
3.2 Базовые типовые решения
3.2.1 Паттерт Layer Supertype
Domain Model (супертип слоя). Тип, выполняющий роль суперкласса для всех классов своего слоя. Довольно часто одни и те же методы дублируются во всех объектах слоя. Чтобы избежать повторений, все общее поведение можно вынести в супертип слоя.
Принцип действия
Концепция супертипа слоя, а следовательно, и само типовое решение крайне просты. Все, что от вас требуется, — это создать суперкласс для всех объектов слоя (например, класс Domainobject, являющийся суперклассом для всех объектов домена в модели предметной области). После этого в созданный суперкласс может быть вынесено все общее поведение наподобие сохранения и обработки полей идентифи-кации.
Если в рассматриваемом слое приложения находятся объекты нескольких различных типов, может понадобиться создать несколько супертипов слоя.
Назначение
Супертип слоя используется тогда, когда все объекты соответствующего слоя имеют некоторые общие свойства или поведение. Поскольку в моих приложениях объекты слоевимеют множество общих черт, применение супертипа вполне может войти в привычку.
3.2.2 Паттерн Separated Interface
Отделенный интерфейс (Separated Interface). Предполагает размещение интерфейса и его реализации в разных пакетах.
По мере разработки системы может возникнуть желание улучшить структуру последней, уменьшая количество зависимостей между ее частями. Управлять зависимостями значительно удобнее, если классы будут сгруппированы в несколько пакетов. Выполнив группировку, вы сможете установить правила, определяющие, могут ли классы одного пакет обращаться к классам другого пакета, например правило, согласно которому классы слоя домена не должны вызывать методы классов слоя представления.
Несмотря на это, клиенту может понадобиться осуществить вызовы методов, противоречащие общей структуре зависимостей. В таком случае имеет смысл воспользоваться типовым решением отделенный интерфейс, определив интерфейс в одном пакете, а реализовав в другом. Таким образом, клиент, которому нужно установить связь с интерфейсом, будет оставаться полностью независимым от его реализации.
Принцип действия
Суть данного типового решения очень проста. Оно основано на том, что реализация зависит от своего интерфейса, но не наоборот. Это значит, что интерфейс и его реализацию можно разместить в разных пакетах, причем пакет, содержащий реализацию, будет зависеть от пакета, содержащего интерфейс. Все другие пакеты приложения могут зависеть от пакета, содержащего интерфейс, и при этом никак не зависеть от пакета, содержащего реализацию.
Разумеется, чтобы подобное приложение заработало во время выполнения, интерфейс должен иметь некоторую реализацию. Для этого можно воспользоваться отдельным пакетом, который будет связывать интерфейс и реализацию во время компиляции, или же связать их во время настройки приложения.
Интерфейс можно поместить в пакет клиента или же в отдельный пакет. Если реализация имеет только одного клиента или все клиенты реализации находятся в одном пакете, интерфейс может быть размещен прямо в пакете клиента. В связи с этим нелишне задуматься о том, отвечают ли разработчики клиентского пакета за определение интерфейса? Размещение интерфейса в пакете клиента указывает на то, что данный пакет будет принимать обращения от всех пакетов, содержащих реализацию этого интерфейса. Таким образом, если у вас есть несколько клиентских пакетов, интерфейс лучше поместить в отдельный пакет (см. рис. 3.1). Это рекомендуется делать и тогда, когда определение интерфейса не входит в обязанности разработчиков клиентского пакета (например, когда определением интерфейса занимаются разработчики его реализации).
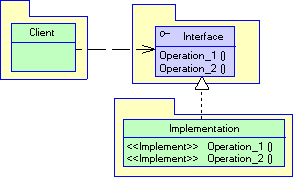
Рисунок 3.1 Размещение интерфейса в отдельном пакете
Помимо всего прочего, разработчику отделенного интерфейса необходимо выбрать, какими средствами языка программирования следует воспользоваться для описания интерфейса Складывается впечатление, что при использовании языков наподобие Java и С#, содержащих специальные интерфейсные конструкции, проще всего применить ключевое слово interface. Как ни странно, это далеко не всегда удачный выбор. Часто в качестве интерфейса лучше использовать абстрактный класс, чтобы допустить наличие общего, но необязательного поведения.
Наиболее неприятным моментом в использовании отделенного интерфейса является создание экземпляра реализации. Как правило, чтобы создать экземпляр реализации, объект должен "знать" о классе последней. Зачастую в качестве такого объекта применяют отдельный объект-фабрику (factory object), интерфейс которого также реализован в виде отделенного интерфейса. Разумеется, объект-фабрика должен зависеть от реализации интерфейса, поэтому для обеспечения наиболее "безболезненной" связи применяют дополнительный модуль. Последний не только обеспечивает отсутствие зависимостей, но
и позволяет отложить принятие решения о выборе класса реализации до момента настройки системы.
В качестве более простой альтернативы дополнительному модулю можно предложить использование еще одного пакета, знающего и об интерфейсе и о реализации, который будет создавать экземпляры нужных объектов во время запуска системы. В этом случае экземпляры всех объектов, использующих отделенный интерфейс, или же соответствующих объектов-фабрик могут быть созданы в момент запуска приложения.
Назначение
Отделенный интерфейс применяется для того, чтобы избежать возникновения зависимостей между двумя частями системы. Наиболее часто подобная необходимость возникает в описанных ниже ситуациях.
- Если вы разместили в пакете инфраструктуры абстрактный код для обработки стандартных случаев, который должен вызывать конкретный код приложения.
- Если код одного слоя приложения должен обратиться к коду другого слоя, о суще ствовании которого он не знает (например, когда код домена обращается к преоб разователю данных.
- Если нужно вызвать методы, разработанные кем-то другим, но вы не хотите, что бы ваш код зависел от интерфейсов API этих разработчиков.
3.2.3 Паттерн Lazy Load
Загрузка по требованию (Lazy Load) Объект, который не содержит все требующиеся данные, однако может загрузить их в случае необходимости.
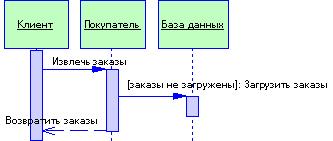
Рисунок 3.2. Загрузка данных по требованию (пример)
Загрузку данных в оперативную память следует организовать таким образом, чтобы при загрузке интересующего вас объекта из базы данных автоматически извлекались и другие связанные с ним объекты. Это значительно облегчает жизнь разработчика, которому в противном случае пришлось бы прописывать загрузку всех связанных объектов вручную.
К сожалению, подобный процесс может принять устрашающие формы, если загрузка одного объекта повлечет за собой загрузку огромного количества связанных с ним объектов - крайне нежелательная ситуация, особенно когда вам были нужны только несколько конкретных записей.
Типовое решение загрузка по требованию прерывает процесс загрузки, оставляя соответствующую метку в структуре объектов. Это позволяет загрузить необходимые данные только тогда, когда они действительно понадобятся.
Принцип действия
Существует несколько способов реализации загрузки по Самый простой из них - инициализация по требованию. Основная идея данного подхода заключается в том, что при каждой попытке доступа к полювыполняется проверка, не содержит ли оно значение NULL. ЕСЛИ поле содержит NULL, метод доступа загружает значение поля и лишь затем его возвращает. Это может быть реализовано только в том случае, если поле является самоинкапсулированным, т.е. если доступ к такому полю осуществляется только п средством get-метода (даже в пределах самого класса).
Использовать значение NULL В качестве признака незагруженного поля очень удобно. Исключение составляют лишь те ситуации, когда NULL является допустимым значением загруженного поля.
Назначение
Принимая решение об использовании загрузки по требованию, необходимо обдумать следующее: сколько данных требуется извлекать при загрузке одного объекта и сколько обращений к базе данных для этого понадобится. Бессмысленно использовать загрузку по требованию, чтобы извлечь значение поля, хранящегося в той же строке, что и остальное содержимое объекта; в большинстве случаев загрузка данных за одно обращение не приведет к дополнительным расходам, даже если речь идет о полях большого размера.
Вообще говоря, о применении загрузки по требованию следует думать только в том случае, когда доступ к значению поля требует дополнительного обращения к базе данных. В плане производительности использование загрузки по требованию влияет на то, в какой момент времени будут получены необходимые данные. Зачастую все данные удобно извлекать посредством одного обращения к базе данных, в частности если это соответствует одному взаимодействию с пользовательским интерфейсом. Таким образом, к загрузке по требованию лучше всего обращаться тогда, когда для извлечения дополнительных данных необходимо отдельное обращение к базе данных и когда извлекаемые данные не используются вместе с основным объектом.
Применение загрузки по требованию существенно усложняет приложение, поэтому я стараюсь прибегать к ней только тогда, когда без нее действительно не обойтись.
3.2.4 Паттерн Record Set
Множество записей (Record Set). Представление табличных данных в оперативной памяти.
На протяжении последних 20 лет основным способом долгосрочного хранения данных являются таблицы реляционных баз данных. Наличие горячей поддержки со стороны больших и малых производителей баз данных, а также стандартного (в принципе) языка запросов привело к тому, что практически каждая новая разработка опирается на реляционные данные.
На гребне успеха реляционных баз данных рынок программного обеспечения пополнился массой инфраструктур, предназначенных для быстрого построения пользовательских интерфейсов. Все эти инфраструктуры основываются на использовании реляционных данных и предоставляют наборы элементов управления, которые значительно облегчают просмотр и манипулирование данными, не требуя написания громоздкого кода.
К сожалению, подобные средства имеют один существенный недостаток. Предоставляя возможность легкого отображения и выполнения простых обновлений, они не содержатнормальных элементов, в которые можно было быпоместить бизнес-логику. Наличие каких-либо правил проверки, помимо простейших "правильны ли данные?", а также любых бизнес-правил и вычислений здесь просто не предусмотрено. Разработчикам не остается ничего иного, как помещать подобную логику в базу данных в виде хранимых процедур или же внедрять ее прямо в код пользовательского интерфейса.
Типовое решение множество записей значительно облегчает жизнь разработчиков, предоставляя структуру данных, которая хранится в оперативной памяти и в точности напоминает результат выполнения SQL-запроса, однако может быть сгенерирована и использована другими частями системы.
Принцип действия
Обычно множество записей не приходится конструировать самому. Как правило, подобные классы прилагаются к используемой программной платформе. В качестве примера можно привести объекты DataSet библиотеки ADO.NET и объекты RowSet библиотеки JDBС.
Первой ключевой особенностью множества записей является то, что его структура в точности копирует результат выполнения запроса к базе данных. Это значит, что вы можете использовать классический двухуровневый подход выполнения запроса и помещения данных прямо в соответствующие элементы пользовательского интерфейса с теми же преимуществами, которые предоставляют подобные двухуровневые средства. Вторая ключевая особенность заключается в том, что вы можете создать собственное множество записей или же использовать множество записей, полученное в результате выполнения запроса к базе данных, и легко манипулировать им в коде логики домена.
Несмотря на наличие готовых классов для реализации множества записей, их можно создать и самому. Однако следует отметить, что данное типовое решение имеет смысл только при наличии средств пользовательского интерфейса, предназначенных для отображения и считывания данных, которые также приходится создавать самостоятельно. В любом случае в качестве хорошего примера реализации множества записей можно назвать построение списка коллекций, весьма распространенное в динамически типизированных языках сценариев.
При работе с множеством записей очень важно, чтобы последнее было легко отсоединить от источника данных. Это позволяет передавать множество записей по сети, не беспокоясь о наличии соединения с базой данных. Необходимость отсоединения приводит к очевидной проблеме: как выполнять обновление множества записей? Все больше и больше платформ реализуют множество заиписей в виде единицы работы (Unit of Work,), благодаря чему все изменения множества записей могут быть внесены в отсоединенном режиме и затем зафиксированы в базе данных.
Явный интерфейс
Большинство реализаций множества записей используют неявный интерфейс (implicit interface). В этом случае, чтобы извлечь из множества записей требующиеся сведения, необходимо вызвать универсальный метод с аргументом, указывающим на то, какое поленам нужно. Например, чтобы получить сведения о пассажире, забронировавшем билет науказанный авиарейс, необходимо воспользоваться выражением наподобие aReserva-
tion ["passenger"]. Применение явного интерфейса требует реализации отдельного класса Reservation с конкретными методами и атрибутами, а извлечение сведений о пассажире выполняется с помощью выражений типа aReservation. passenger.
Неявные интерфейсы обладают чрезвычайной гибкостью. Универсальное множество записей может быть использовано для любых видов данных, что избавляет от необходимости написания нового класса при определении каждого нового типа множества записей. Несмотря на подобные преимущества, неявные интерфейсы являются весьма спорным решением. Как узнать, какое слово нужно использовать для того, чтобы добраться к сведениям о пассажире, забронировавшем билет, - "passenger" ("пассажир"), "guest" ("клиент") или, может быть, "flyer" ("летящий")? Единственное, что можно сделать, - это "прочесать" весь исходный код приложения в поисках мест, где создаются и используются объекты бронирования. Если же у меня есть явный интерфейс, мы можем открыть определение класса Reservation и посмотреть, какое свойство нужно.
Данная проблема еще более критична для статически типизированных языков программирования. Чтобы узнать фамилию пассажира, забронировавшего билет, придется прибегнуть к выражению вида
((Person) aReservation["passenger"]).lastNameж
Поскольку компилятор утрачивает всю информацию о типах, для извлечения нужных сведений тип данных приходится указывать вручную. В отличие от этого, явный интерфейс сохраняет информацию о типе, поэтому для извлечения фамилии пассажира можно воспользоваться гораздо более простым выражением:
aReservation.passenger.lastName.
В библиотеке ADO.NET возможность применения явного интерфейса обеспечивают строго типизированные объекты DataSet - сгенерированные классы, которые предоставляют явный иполностью типизированный интерфейс к множеству записей. Поскольку объект DataSet может содержать в себе множество таблиц и отношений, в которых они находятся, строго типизированные объекты DataSet включают в себя свойства, использующие информацию об отношениях между таблицами. Генерация классов DataSet выполняется на основе определений схем XML (XML Schema Definition — XSD).
3.2.5 Паттерн Unit of Work
Единица работы (Unit of Work). Содержит список объектов, охватываемых бизнес-транзакцией, координирует запись изменений в базу данных и разрешает проблемы параллелизма.
Извлекая данные из базы данных или записывая в нее обновления, необходимо отслеживать, что именно было изменено; в противном случае сделанные изменения не будут сохранены в базе данных. Точно так же созданные объекты необходимо вставлять, а удаленные - уничтожать. Разумеется, изменения в базу данных можно вносить при каждом изменении содержимого объектной модели, однако это неизбежно выльется в гигантское количество мелких обращений к базе данных, что значительно снизит производительность. Более того, транзакция должна оставаться открытой на протяжении всего сеанса взаимодействия с базой данных, что никак не применимо к реальной бизнес-транзакции, охватывающей множество запросов. Наконец, вам придется отслеживать считываемые объекты для того, чтобы не допустить несогласованности данных.
Типовое решение единица работы позволяет контролировать все действия, выполняемые в рамках бизнес-транзакции, которые так или иначе связаны с базой данных. По завершении всех действий оно определяет окончательные результаты работы, которые и будут внесены в базу данных.
Принцип действия
Базы данных нужны для того, чтобы вносить в них изменения: добавлять новые объекты или же удалять или обновлять уже существующие. Единица работы - это объект, который отслеживает все подобные действия. Как только вы начинаете делать что-нибудь, что может затронуть содержимое базы данных, вы создаете единицу работы, которая должна контролировать все выполняемые изменения. Каждый раз, создавая, изменяя или удаляя объект, вы сообщаете об этом единице работы. Кроме того, следует сообщать, какие объекты были считаны из базы данных, чтобы не допустить их несогласованности.
Когда вы решаете зафиксировать сделанные изменения, единица работы определяет, что ей нужно сделать. Она сама открывает транзакцию, выполняет всю необходимую проверку на наличие параллельных операций (с помощью пессимистической автономной блокировки (Pessimistic Offline Lock [4]) или оптимистической автономной блокировки (Optimistic Offline Lock [4])) и записывает изменения в базу данных. Разработчики приложений никогда явно не вызывают методы, выполняющие обновления базы данных. Таким образом, им не приходится отслеживать, что было изменено, или беспокоитьсяо том, в каком порядке необходимо выполнить нужные действия, чтобы не нарушить целостность на уровне ссылок, - единица работы сделает это за них.
Разумеется, чтобы единица работы действительно вела себя подобным образом, ей должно быть известно, за какими объектами необходимо следить. Об этом ей может сообщить оператор, выполняющий изменение объекта, или же сам объект.
Назначение
Основным назначением единицы работы является отслеживании действий, выполняемых над объектами домена, для дальнейшей синхронизации данных, хранящихся в оперативной памяти, с содержимым базы данных. Если вся работа выполняется в рамках системной транзакции, следует беспокоиться только о тех объектах, которые вы изменяете. Конечно же, для этого лучше воспользоваться единицей работы, однако существуют и другие решения.
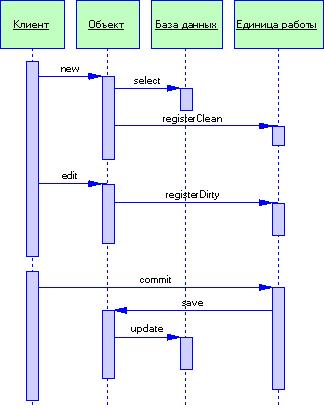
Рисунок 3.3 Регистрация изменяемого объекта
Пожалуй, наиболее простая альтернатива - явно сохранять объект после каждого изменения. Недостатком этого подхода является необходимость большого количества обращений к базе данных; например, если на протяжении выполнения одного метода объект был изменен трижды, вам придется выполнять три обращения к базе данных, вместо того чтобы ограничиться одним обращением по окончании всех изменений.
Во избежание многократных обращений к базе данных запись всех изменений можно отложить до окончания работы. В этом случае вам придется отслеживать все изменения, которые были внесены в содержимое объектов. Для реализации подобной стратегии в код можно ввести дополнительны переменные, однако учтите: если переменных слишком много, они становятся неуправляемыми. Переменные хорошо использовать со сценарием транзакции, но они совсем не подходят для модели предметной области.
Вместо того чтобы хранить измененные объекты в переменных, для каждого объекта можно создать флаг, который будет указывать на состояние объекта - изменен или не изменен. В этом случае по окончании транзакции необходимо отобрать все измененные объекты и записать их содержимое в базу данных. Удобство этого метода зависит от того, насколько просто находить измененные объекты. Если все объекты находятся в одной иерархии, вы можете последовательно просмотреть всю иерархию и записать в базу данных все обнаруженные изменения. В свою очередь, более общие структуры объектов, в частности модель предметной области, просматривать гораздо труднее.
Огромным преимуществом единицы работы является то, что она хранит все данные об изменениях в одном месте. Поэтому вам не придется запоминать море информации, что-бы не упустить из виду все изменения объектов.
Особенность .NET реализации
В .NET для реализации единицы работы используется объект DataSet, лежащий в основе отсоединенной модели доступа к данным. Последнее обстоятельство немного отличает его от остальных разновидностей шаблона. В среде .NET данные загружаются из базы данных в объект DataSet, дальнейшие изменения которого происходят в автономном режиме. Объект DataSet состоит из таблиц (объекты DataTable), которые, в свою очередь, состоят из столбцов (объекты DataColumn) и строк (объекты DataRow). Таким образом, объект DataSet представляет собой "зеркальную" копию множества данных, полученного в результате выполнения одного или нескольких SQL-запросов. У каждой строки DataRow есть версии (Current, Original, Proposed) и состояния (Unchanged, Added, Deleted, Modified). Наличие последних, а также тот факт, что объектная модель DataSet в точности повторяет структуру базы данных, значительно упрощает запись изменений обратно в базу данных.
3.3 Паттерны организация бизнес-логики
Рассматривая структуру логики предметной области (или бизнес-логики) приложения, мы изучаем варианты распределения множества предусматриваемых ею функций по трем типовым решениям: сценарий транзакции (Transaction Script), модель предметной области (Domain Model) и модуль таблицы (Table Module).
Простейший подход к описанию бизнес-логики связан с использованием сценария транзакции - процедуры, которая получает на вход информацию от слоя представления, обрабатывает ее, проводя необходимые проверки и вычисления, сохраняет в базе данных и активизирует операции других систем. Затем процедура возвращает слою представления определенные данные, возможно, осуществляя вспомогательные операции для форматирования содержимого результата. Бизнес-логика в этом случае описывается набором процедур, по одной на каждую (составную) операцию, которую способно выполнять приложение. Типовое решение сценарий транзакции, таким образом, можно трактовать как сценарий действия, или бизнес-транзакцию. Оно не обязательно должно представлять собой единый фрагмент кода. Код делится на подпрограммы, которые распределяются между различными сценариями транзакции.
Типовое решение сценарий транзакции отличается следующими преимуществами:
- представляет собой удобную процедурную модель, легко воспринимаемую всеми разработчиками;
- удачно сочетается с простыми схемами организации слоя источника данных на основе типовых решений шлюз записи данных (Row Data Gateway) и шлюз таблицы данных (Table Data Gateway);
- определяет четкие границы транзакции.
С возрастанием уровня сложности бизнес-логики типовое решение сценарий транзакции демонстрирует и ряд недостатков. Если нескольким транзакциям необходимо осуществлять схожие функции, возникает опасность дублирования фрагментов кода. С этим
явлением удается частично справиться за счет вынесения общих подпрограмм "за скобки", но даже в этом случае большая часть дубликатов остается на месте. В итоге приложение может выглядеть как беспорядочная мешанина без отчетливой структуры.
Конечно, сложная логика - это удачный повод вспомнить об объектах, и объектно-ориентированный вариант решения проблемы связан с использованием модели предметной области, которая, по меньшей мере в первом приближении, структурируется преимущественно вокруг основных сущностей рассматриваемого домена. Так, например, в лизинговой системе следовало бы создать классы, представляющие сущности "аренда", "имущество", "договор" и т.д., и предусмотреть логику проверок и вычислений: так, например, объект, представляющий сущность "имущество", вероятно, уместно снабдить логикой вычисления стоимости.
Выбор модели предметной области в противовес сценарию транзакции - это как раз та смена парадигмы программирования, о которой так любят говорить апологеты объектного подхода. Вместо использования одной подпрограммы, несущей в себе всю логику, которая соответствует некоторому действию пользователя, каждый объект наделяется только функциями, отвечающими его природе. Если прежде вы не пользовались моделью предметной области, процесс обучения может принести немало огорчений, когда в поисках нужных функций вам придется метаться от одного класса к другому.
Стоимость практической реализации модели предметной области обусловлена степенью сложности как самой модели, так и конкретного варианта слоя источника данных. Чтобы добиться успехов в применении модели, новичкам придется затратить немало времени: некоторым требуется несколько месяцев работы над соответствующим проектом, прежде чем их стиль мышления перестроится в нужном направлении. После приобретения опыта работать становится намного проще - в вас даже просыпается энтузиазм. Через это прошли все, кто так одержим объектной парадигмой. Впрочем, сбросить груз привычек и сделать шаг вперед многим, к сожалению, так и не удается.
Разумеется, каким бы ни был подход, необходимость отображать содержимое базы данных в структуры памяти и наоборот все еще остается. Чем более "богата" модель предметной области, тем сложнее становится аппарат взаимного отображения объектных структур в реляционные (обычно реализуемый на основе типового решения преобразователь данных (Data Mapper). Сложный слой источника данных стоит дорого - в финансовом смысле (если вы приобретаете услуги сторонних разработчиков) или в отношении затрат времен (если беретесь за дело самостоятельно), но если он у вас есть, считайте, что добрая половина проблемы уже решена.
Существует и третий вариант структуризации бизнес-логики, предусматривающий применение типового решения модуль таблицы Принципиальное различие модуля талицы от модели предметной области заключается в том, что модель предметной области содержит по одному объекту контракта для каждого контракта, зафиксированного в базе данных, а модуль таблицы является единственным объектом. Модуль таблицы применяется совместно с типовым решением множество записей (Record Set). Посылая запросы к базе данных, пользователь прежде всего формирует объект множество записей, а затем создает объект контракта, передавая ему множество записей в качестве аргумента. Если потребуется выполнять операции над отдельным контрактом, следует сообщить объекту соответствующий идентификатор (ID).
Модуль таблицы во многих смыслах представляет собой промежуточный вариант, компромиссный по отношению к сценарию транзакции и модели предметной области. Организация бизнес-логики вокруг таблиц, а не в виде прямолинейных процедур облегчает структурирование и возможность поиска и удаления повторяющихся фрагментов кода. Однако решение модуль таблицы не позволяет использовать многие технологии (скажем, наследование, стратегии и другие объектно-ориентированные типовые решения), которые применяются в модели предметной области для уточнения структуры логики.
Наибольшее преимущество модуля таблицы состоит в том, как это решение сочетается с остальными аспектами архитектуры. Многие графические интерфейсные среды позволяют работать с результатами обработки SQL-запроса, организованными в виде множества записей. Поскольку решение модуль таблицы также основано на использовании множества записей, открывается возможность выполнения запроса, манипулирования его результатом в контексте модуля таблицы и передачи данных графическому интерфейсу для отображения. Некоторые платформы, в частности Microsoft COM и .NET, поддерживают именно такой стиль разработки.
Выбор типового решения
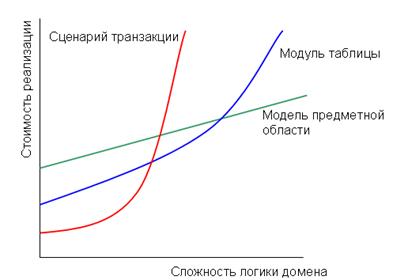
Рисунок 3.4 Зависимость стоимости реализации различных схем организации бмзнес-логики от ее сложности
Итак, какому из трех типовых решений отдать предпочтение. Ответ не очевиден и во многом зависит от степени сложности бизнес-логики. На рис. 3.4 показан один из тех неформальных графиков, которые многим действуют на нервы, когда приходится наблюдать презентации. Причиной раздражения служит отсутствие единиц измерения величин, представляемых координатными осями. Впрочем, в данном случае подобный график кажется уместным, так как помогает визуализировать критерии сопоставления решений. Если логика приложения проста, модель предметной области менее соблазнительна, поскольку затраты на ее реализацию не окупаются. Но с возрастанием сложности альтернативные подходы становятся все менее приемлемыми: трудоемкость пополнения приложения новыми функциями увеличивается по экспоненциальному закону.
Конечно, необходимо разобраться, к какому именно сегменту оси X относится конкретное приложение. Было бы совсем неплохо, если бы мы имели право сказать, что модель предметной области следует применять в тех случаях, когда сложность бизнес-логики составляет, например, 7,42 или больше. Однако никто не знает, как измерять сложность бизнес-логики. Поэтому на практике проблема обычно сводится к выслушиванию мнений сведущих людей, которые способны хоть как-то проанализировать ситуацию и прийти к осмысленным выводам.
Существует ряд факторов, влияющих на кривизну линий графика. Наличие команды разработчиков, уже знакомых с моделью предметной области, позволяет снизить величину начальных затрат - хотя и не до уровней, характерных для двух других зависимостей (последнее обусловлено сложностью слоя источника данных). Таким образом, чем опытнее вы и ваши коллеги, тем больше у вас оснований для применения модели предметной области.
Эффективность модуля таблицы серьезно зависит от уровня поддержки структуры множества записей в конкретной инструментальной среде. Если вы работаете с чем-то наподобие Visual Studio .NET, где многие средства построены именно на основе модели множества записей, это обстоятельство наверняка придаст модулю таблицы дополнительную привлекательность. Что касается сценария транзакции, то трудно найти доводы в пользу его применения в контексте .NET.
Как только архитектура выбрана (пусть и не окончательно), изменить ее со временем становится все труднее. Поэтому целесообразно приложить определенные усилия, чтобы заранее решить, каким путем двигаться. Если вы начали со сценария транзакции, но затем поняли свою ошибку, не мешкая обратитесь к модели предметной области. Если вы с нее и начинали, переход к сценарию транзакции вряд ли окажется удачным, если только вы не сможете серьезно упростить слой источника данных.
Три типовых решения, которые мы бегло рассмотрели, не являются взаимоисключающими альтернативами. На самом деле сценарий транзакции нередко используется для некоторого фрагмента бизнес-логики, а модель предметной области или модуль таблицы - для оставшейся части.
Уровень служб
Один из общих подходов к реализации бизнес-логики состоит в расщеплении слоя предметной области на два самостоятельных слоя: "поверх" модели предметной области или модуля таблицы располагается слой служб (Service Layer [4]). Обычно это целесообразно только при использовании модели предметной области или модуля таблицы, поскольку слой домена, включающий лишь сценарий транзакции, не настолько сложен, чтобы заслужить право на создание дополнительного слоя. Логика слоя представления взаимодействует с бизнес-логикой исключительно при посредничестве слоя служб, который действует как API приложения.
Поддерживая внятный интерфейс приложения (API), слой служб подходит также для размещения логики управления транзакциями и обеспечения безопасности. Это дает возможность снабдить подобными характеристиками каждый метод слоя служб.
Для таких целей обычно применяются файлы свойств, но атрибуты .NET предоставляют удобный способ описания параметров непосредственно в коде. Основное решение, принимаемое при проектировании слоя служб, состоит в том, какую часть функций уместно передать в его ведение. Самый "скромный" вариант - представить слой служб в виде промежуточного интерфейса, который только и делает, что направляет адресуемые ему вызовы к нижележащим объектам. В такой ситуации слой служб обеспечивает API, ориентированный на определенные варианты использования (use cases) приложения, и предоставляет удачную возможность включить в код функции оболочки, ответственные за управление транзакциями и проверку безопасности.
Другая крайность - в рамках слоя служб представить большую часть логики в виде сценариев транзакции. Нижележащие объекты домена в этом случае могут быть тривиальными; если они сосредоточены в модели предметной области, удастся обеспечить их однозначное отображение на элементы базы данных и воспользоваться более простым вариантом слоя источника данных (скажем, активной записью (Active Record).
Между двумя указанными полюсами существует вариант, представляющий собой больше, нежели "смесь" двух подходов: речь идет о модели "контроллер-сущность" ("controller-entity"). Главная особенность модели заключается в том, что логика, относящаяся к отдельным транзакциям или вариантам использования, располагается в соответствующих сценариях транзакции, которые в данном случае называют контроллерами (или службами). Они выполняют роль входных контроллеров в типовых решениях модель-представление-контроллер (Model View Controller,) и контроллер приложения (Application Controller [4]) (вы познакомитесь с ними позже) и поэтому называются также контроллерами вариантов использования (use case controller). Функции, характерные одновременно для нескольких вариантов использования, передаются объектам-сущностям (entities) домена.
Хотя модель "контроллер-сущность" распространена довольно широко, следует иметь ввиду, что контроллеры вариантов использования, подобные любому сценарию транзакции, негласно поощряют дублирование фрагментов кода.
3.3.1 Паттерн Transaction Script
Название
Transaction Script (сценарий транзакции)
Назначение
Способ организации бизнес-логики по процедурам, каждая из которых обслуживает один запрос, инициируемый слоем представления.
Многие бизнес-приложения могут восприниматься как последовательности транзакций. Одна транзакция способна модифицировать данные, другая - воспринимать их в структурированном виде и т.д. Каждый акт взаимодействия клиента с сервером описывается определенным фрагментом логики. В одних случаях задача оказывается настолько же простой, как отображение части содержимого базы данных. В других могут предусматриваться многочисленные вычислительные и контрольные операции. Сценарий транзакции организует логику вычислительного процесса преимущественно в виде единой процедуры, которая обращается к базе данных напрямую или при посредничестве кода тонкой оболочки. Каждой транзакции ставится в соответствие собственный сценарий транзакции (общие подзадачи могут быть вынесены в подчиненные процедуры).
Принцип действия
При использовании типового решения сценарий транзакции логика предметной области распределяется по транзакциям, выполняемым в системе. Если, например, пользователю необходим заказать номер в гостинице, соответствующая процедура должна предусматривать действия по проверке наличия подходящего номера, вычислению суммы оплаты и фиксации заказа в базе данных.
Простые случаи не требуют особых объяснений. Разумеется, как и при написании иных программ, структурировать код по модулям следует осмысленно. Это не должно вызывать затруднений, если только транзакция не оказывается слишком сложной. Одно из основных преимуществ сценария транзакции заключается в том, что вам не приходится беспокоиться о наличии и вариантах функционирования других параллельных транзакций. Ваша задача — получить входную информацию, опросить базу данных, сделать вы- воды и сохранить результаты.
Где расположить сценарий транзакции, зависит от организации слоев системы. Этим местом может быть страница сервера, сценарий CGI или объект распределенного сеанса. Я предпочитаю обособлять сценарии транзакции настолько строго, насколько это возможно. В самом крайнем случае можно размещать их в различных подпрограммах, а лучше - в классах, отличных от тех, которые относятся к слоям представления и источника данных. Помимо того, следует избегать вызовов, направленных из сценариев транзакции к коду логики представления; это облегчит тестирование сценариев транзакции и их возможную модификацию.
Существует два способа разнесения кода сценариев транзакции по классам. Наиболее общий, прямолинейный и удобный во многих ситуациях — использование одного класса для реализации нескольких сценариев транзакции. Второй, следующий схеме типового решения команда (Command), связан с разработкой собственного класса для каждого сценария транзакции (рис. 3.5): определяется тип, базовый по отношению ко всем командам, в котором предусматривается некий метод выполнения, удовлетворяющий логике сценария транзакции. Преимущество такого подхода - возможность манипулировать экземплярами сценариев как объектами в период выполнения, хотя в системах, где бизнес-логика организована с помощью сценариев транзакции, подобная потребность возникает сравнительно редко. Разумеется, во многих языках модель классов можно полностью игнорировать, полагаясь, скажем, только на глобальные функции. Однако вполне очевидно, что аппарат создания объектов помогает преодолевать проблемы потоков вычислений и облегчает изоляцию данных.
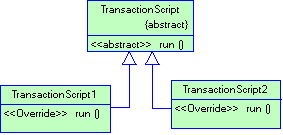
Рисунок 3.5. Применение паттерна Command в паттерне Transaction Script
Применимость
Главным достоинством типового решения сценарий транзакции является простота. Именно такой вид организации логики, эффективный с точки зрения восприятия и производительности, весьма характерен и естествен для небольших приложений. По мере усложнения бизнес-логики становится все труднее содержать ее в хорошо структурированном виде. Одна из достойных внимания проблем связана с повторением фрагментов кода. Поскольку каждый сценарий транзакции призван обслуживать одну транзакцию, все общие порции кода неизбежно приходится воспроизводить вновь и вновь.
Проблема может быть частично решена за счет тщательного анализа кода, но наличие более сложной бизнес-логики требует применять модель предметной области (Domain Model). Последняя предлагает гораздо больше возможностей структурирования кода, повышения степени его удобочитаемости и уменьшения повторяемости. Определить количественные критери выбора конкретного типового решения довольно сложно, особенно если одни решения знакомы вам в большей степени, нежели другие. Проект, основанный на сценарии транзакции, с помощью техники рефакторинга вполне возможно преобразовать в реализацию модели предметной области, но дело слишком хлопотно, чтобы им стоило заниматься. Поэтому, чем раньше вы расставите все точки над i, тем лучше. Однако каким бы ярым приверженцем объектных технологий вы ни становились, не отбрасывайте сценарий транзакции: существует множество простых проблем, и их решения также должны быть простыми.
3.3.2 Паттерн Domain Model
Название
Domain Model (модель предметной области).
Назначение
В своих наихудших проявлениях бизнес-логика бывает чрезвычайно сложной, с множеством правил и условий, оговаривающих различные варианты использования и особенности поведения системы. Для облегчения именно таких трудностей и предназначены объекты. Типовое решение модель предметной области предусматривает создание сети взаимосвязанных объектов, каждый из которых представляет некую осмысленную сущность - либо такую крупную, как промышленная корпорация, либо настолько мелкую, как строка формы заказа.
Принцип действия
Реализация модели предметной области означает пополнение приложения целым слоем объектов, описывающих различные стороны определенной области бизнеса. Одни объекты призваны имитировать элементы данных, которыми оперируют в этой области, а другие должны формализовать те или иные бизнес-правила. Функции тесно сочетаются сданными, которыми они манипулируют.
Объектно-ориентированная модель предметной области часто напоминает схему соответствующей базы данных, хотя между ними все еще остается множество различий. В модели предметной области смешиваются данные и функции, допускаются многозначные атрибуты, создаются сложные сети ассоциаций и используются связи наследования. В сфере корпоративных программных приложений можно выделить две разновидности моделей предметной области. "Простая" во многом походит на схему базы данных и содержит, как правило, по одному объекту домена в расчете на каждую таблицу. "Сложная" модель может отличаться от структуры базы данных и содержать иерархии наследования, стратегии и иные шаблоны, а также сложные сети мелких взаимосвязанных объектов. Сложная модель более адекватно представляет запутанную бизнес-логику, но труднее поддается отображению в реляционную схему базы данных. В простых моделях подчас достаточно применять варианты тривиального типового решения активная запись (Active Record), в то время как в сложных без замысловатых преобразователей данных (Data Mapper) порой просто не обойтись.
Бизнес-логика обычно подвержена частым изменениям, поэтому весьма важна возможность простой модификации и тестирования этого слоя кода. Отсюда следует настоятельная необходимость снижать степень зависимости модели предметной области от других слоев системы. Более того, как вы сможете убедиться, именно это требование является основополагающим аспектом многих типовых решений, имеющих отношение к "расслоению" системы.
С моделью предметной области связано большое количество различных контекстов.Простейший вариант— однопользовательское приложение, где единый граф объектов считывается из дискового файла и располагается в оперативной памяти. Такой стиль работы присущ настольным программам, но менее характерен для многоуровневых прило-жений, поскольку в них намного больше объектов. Размещение каждого объекта в памяти сопряжено с чрезмерными затратами ресурсов памяти и времени. Прелесть объектно-ориентированных систем баз данных заключается в том, что они создают впечатление, будто объекты пребывают в памяти постоянно.
Без такой системы заботиться о создании объектов вам придется самому. Обычно в ходе выполнения сеанса в память загружается полный граф объектов, хотя речь вовсе не идет обо всех объектах и, может быть, классах. Если, например, ведется поиск множества контрактов, достаточно считать информацию только о таких продуктах, которые упоминаются в этих контрактах. Если же в вычислениях участвуют объекты контрактов и зачтенных доходов, объекты продуктов, возможно, создавать вовсе не нужно. Точный перечень данных, загружаемых в память, определяется параметрами объектнореляционного отображения.
Одна из типичных проблем бизнес-логики связана с чрезмерным увеличением объектов. Занимаясь конструированием интерфейсного экрана, позволяющего манипулировать заказами, вы наверняка заметите, что только некоторые функции отличаются сугубо специфическим характером и узким назначением. Возлагая на единственный класс заказа всю полноту ответственности, вы рискуете раздуть его до непомерной величины. Что-бы избежать подобного, можно выделить общие характеристики "заказов" и сосредоточить их в одноименном классе, а все остальные функции вынести во вспомогательные классы сценариев транзакции (Transaction Script) или даже слоя представления. преобразователей данных (Data Mapper) порой просто не обойтись.
При этом, однако, возникает опасность повторения фрагментов кода. Функции, не относящиеся к категории общих, отыскать довольно трудно, и многие предпочитают этим просто не заниматься, соглашаясь с дублированием кода. Повторение часто приводит к усложнению и несогласованности, хотя, по моему мнению, эффекты излишнего увеличения размеров классов наблюдаются значительно реже, чем можно было ожидать
Применимость
Если вопросы как, касающиеся модели предметной области, трудны потому, что предмет чересчур велик, вопрос когда сложен ввиду неопределенности ситуации. Все зависит от степени сложности поведения системы. Если вам приходится иметь дело с изощренными и часто меняющимися бизнес-правилами, включающими проверки, вычисления и ветвления, вполне вероятно, что для их описания вы предпочтете объектную модель. Если, напротив, речь идет о паре сравнений значения с нулем и нескольких операциях сложения, проще прибегнуть к сценарию транзакции (Transaction Script).
Существует еще один фактор, который нельзя обойти вниманием: насколько комфортно чувствует себя команда разработчиков, манипулируя объектами домена. Изучение способов проектирования и применения модели предметной области - урок крайне сложный, пробудивший к жизни целый информационный пласт о "смене парадигмы". Чтобы привыкнуть к модели, нужны практика и советы профессионала, но зато среди тех, кто дошел до цели, редко встречаютсятакие, кто хотел бы вновь вернуться к сценарию транзакции, - разве только в самых простых случаях.
При необходимости взаимодействия с базой данных в контексте модели предметной области прежде всего я обратился бы к преобразователю данных. Это типовое решение поможет сохранить независимость бизнес-модели от схемы базы данных и обеспечить наилучшие возможности изменения их в будущем.
Встречаются ситуации, когда модель предметной области целесообразно снабдить более отчетливым интерфейсом API, и для этого можно порекомендовать типовое решение слой служб (Service Layer [4]) .
3.3.3 Паттерн Table Module
Название
Table Module (модуль таблицы)
Назначение
Одна из ключевых предпосылок объектной модели — сочетание элементов данных и пользующихся ими функций. Традиционный объектно-ориентированный подход основан на концепции объектов с идентификационными признаками в совокупности с требованиями модели предметной области (Domain Model). Если, например, речь идет о классе, представляющем сущность "служащий", любой экземпляр класса соответствует определенному служащему; коль скоро есть ссылка на объект, отвечающий служащему, с ним легко выполнять все необходимые операции, собирать информациюи следовать в направлении связей с другими объектами.
Одна из проблем модели предметной области заключается в сложности создания интерфейсов к реляционным базам данных; последние в подобной ситуации приобретают роль эдаких бедных родственников, с которыми никто не желает иметь дела. Поэтому считывание информации из базы данных и запись ее с необходимыми преобразованиями превращается в прихотливую игру ума.
Типовое решение модуль таблицы предусматривает создание по одному классу на каждую таблицу базы данных, и единственный экземпляр класса содержит всю логику обработки данных таблицы. Основное отличие модуля таблицы от модели предметной области состоит в том, что если, например, приложение обслуживает множество заказов, в соответствии с моделью предметной области придется сконструировать по одному объекту на каждый заказ, а при использовании модуля таблицы понадобится всего один объект, представляющий одновременно все заказы.
Принцип действия
Сильная сторона решения модуль таблицы заключается в том, что оно позволяет сочетать данные и функции для их обработки и в то же время эффективно использовать ресурсы реляционной базы данных. На первый взгляд модуль таблицы во многом напоминает обычный объект, но отличается тем, что не содержит какого бы то ни было упоминания об идентификационном признаке объекта. Если, скажем, требуется получить адрес служащего, для этого применяется метод anEmployeeModule.GetAddress(long empioyeeId). В том случае, когда необходимо выполнить операцию, касающуюся определенного служащего, соответствующему методу следует передать ссылку на идентификатор, значение которого зачастую совпадает с первичным ключом служащего в таблице базы данных.
Модулю таблицы, как правило, отвечает некая табличная структура данных. Подобная информация обычно является результатом выполнения SQL-запроса и сохраняется в виде множества записей (Record Set). Модуль таблицы предоставляет обширный арсенал методов ее обработки. Объединение функций и данных обеспечивает многие преимущества модели инкапсуляции.
Нередко для решения общей задачи необходимо создать несколько модулей таблицыи, более того, позволить им манипулировать одним и тем же множеством записей. Наиболее очевидный пример связан с использованием отдельных модулей таблицы для каждой (хранимой) таблицы базы данных. Кроме того, можно сконструировать модули таблицы для любых достойных SQL-запросов и виртуальных таблиц. Конкретный модуль таблицы может принимать вид экземпляра класса или набора статических методов. Достоинство первого варианта состоит в том, что он позволяет инициировать модуль данными существующего множества записей, чаще всего получаемого в результате обработки SQL-запроса. Для манипуляции записями применяются методы класса. Не исключается и возможность создания иерархии наследования, когда, скажем, определяются базовый класс с описанием контракта общего вида и целое семейство производных классов, отвечающих частным разновидностям контрактов.
Модуль таблицы способен содержать методы-оболочки, представляющие запросы к базе данных. Альтернативой служит шлюз таблицы данных (Table Data Gateway). Недостаток последнего обусловлен необходимостью конструирования дополнительного класса, а преимущество заключается в возможности применения единого модуля таблицы для данных из различных источников, поскольку каждому отвечает собственный шлюз таблицы данных.
Шлюз таблицы данных позволяет структурировать информацию в виде множества записей, которое затем передается конструктору модуля таблицы в качестве аргумента (рис. 3.6). Если необходимо использовать несколько модулей таблицы, все они могут быть созданы на основе одного и того же множества записей. Затем каждый модуль таблицы применяет к множеству записей функции бизнес-логики и передает измененное множество записей слою представления для отображения и редактирования информации средствами графических табличных элементов управления. Последние не "осведомлены", откуда поступили данные — непосредственно от реляционной СУБД или от промежуточного модуля таблицы, который успел осуществить их предварительную обработку. По завершении редактирования информация возвращается модулю таблицы для проверки перед сохранением в базе данных. Одно из преимуществ подобного стиля - возможность тестирования модуля таблицы путем "искусственного" создания множества записей в памяти без обращения к реальной таблице базы данных.
Слово "таблица" в названии типового решения подчеркивает, что в приложении предусматривается по одному модулю таблицы для каждой хранимой таблицы базы данных. Это правда, но не вся. Полезно также иметь модули таблицы для общеупотребительных виртуальных таблиц и запросов, поскольку структура модуля таблицы на самом деле не зависит напрямую от структуры физических таблиц базы данных, а определяется в ос-новном характеристиками виртуальных таблиц и запросов, используемых в приложении
Применимость
Типовое решение модуль таблицы во многом основывается на табличной структуре данных и потому допускает очевидное применение в ситуациях, где доступ к информации обеспечивается при посредничестве множеств записей. Структуре данных отводится центральная роль, так что методы обращения к данным в структуре должны быть прямолинейными и эффективными.
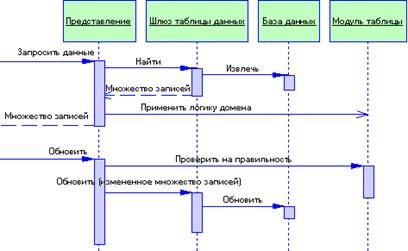
Рисунок 3.6 Схема взаимодействия слоев кода с модулем таблицы
Модуль таблицы, однако, не позволяет воспользоваться всей мощью объектного подхода к организации сложной бизнес-логики. Вам не удастся создать прямые связи от объекта к объекту, да и механизм полиморфизма действует в этих условиях не безукоризненно. Поэтому для реализации особо изощренной логики предпочтительнее модель предметной области. По существу, проблема сводится к поиску компромисса между способностью модели предметной области к эффективному отображению бизнес-логики и простотой интеграции кода приложения и реляционных структур данных, обеспечиваемой модулем таблицы.
Если объекты модели предметной области относительно точно отвечают таблицам базы данных, возможно, целесообразнее применить модель предметной области совместно с активной записью (Active Record). Модуль таблицы, однако, ведет себя лучше, чем комбинация модели предметной области и активной записи, если разные части приложения основаны на общей табличной структуре данных. Впрочем, в среде Java, например, модуль таблицы пока не пользуется популярностью, хотя с распространением модели множеств записей ситуация, возможно, и изменится.
Чаще всего образцы использования модуля таблицы приходится видеть в проектах на основе архитектуры Microsoft COM. В технологии СОМ (и .NET) множество записей представляет собой основное хранилище данных, с которыми оперирует приложение. Множества записей могут передаваться фафическим элементам управления для воспро- изведения информации на экране. Добротный механизм доступа к реляционным данным, представленным в виде множеств записей, реализован в семействе библиотек Microsoft ADO. В подобных случаях модуль таблицы позволяет описать бизнес-логику в хорошо структурированном виде.
3.4 Паттерны организации источников данных
3.4.1 Объектные модели и реляционные базы данных
Роль слоя источника данных состоит в том, чтобы обеспечить возможность взаимодействия приложения с различными компонентами инфраструктуры для выполнения необходимых функций. Главная составляющая подобной проблемы связана с поддержкой диалога с базой данных - в большинстве случаев реляционной. До сих пор изрядные массивы данных все еще хранятся в устаревших форматах, но практически все разработчики современных приложений, предусматривающих связь с системами баз данных, ориентируются на реляционные СУБД.
Одной из самых серьезных причин успеха реляционных систем является поддержка ими SQL - наиболее стандартизованного языка коммуникаций с базой данных. Хотя сегодня SQL все более обрастает раздражающе несовместимыми и сложными "улучшениями", поддерживаемыми различными поставщиками СУБД, синтаксис ядра языка, к счастью, остается неизменным и доступным для всех.
3.4.2 Архитектурные решения
В первую обойму архитектурных решений входят, в частности, и такие, которые оговаривают способы взаимодействия бизнес-логики с базой данных. Выбор, который делается на этом этапе, имеет далеко идущие последствия и отменить его бывает трудно или даже невозможно. Поэтому он заслуживает наиболее тщательного осмысления. Нередко подобными решениями как раз и обусловливаются варианты компоновки бизнес-логики.
Несмотря на широкую поддержку корпоративными приложениями, использование SQL сопряжено с определенными трудностями. Многие разработчики просто не владеют SQL и потому, пытаясь сформулировать эффективные запросы и команды, сталкиваются с проблемами. Помимо того, все без исключения технологии внедрения предложений SQL в код на языке программирования общего назначения страдают теми или иным изъянами. (Безусловно, было бы лучше осуществлять доступ к содержимому базы данных с помощью неких механизмов уровня языка разработки приложения.) А администраторы баз данных хотели бы уяснить нюансы обработки SQL-выражений, чтобы иметь возможность их оптимизировать.
По этим причинам разумнее обособить код SQL от бизнес-логики, разместив его в специальных классах. Удачный способ организации подобных классов состоит в "копировании" структуры каждой таблицы базы данных в отдельном классе, который формирует шлюз (Gateway,), поддерживающий возможности обращения к таблице. Теперь основному коду приложения нет необходимости что-либо "знать" о SQL, а все SQL-операции сосредоточиваются в компактной группе классов.
Существует два основных варианта практического использования типового решения шлюз. Наиболее очевидный - создание экземпляра шлюза для каждой записи, возвращаемой в результате обработки запроса к базе данных (рис. 3.7). Подобный шлюз записи данных (Row Data Gateway,) представляет собой модель, естественным образом отображающую объектно-ориентированный стиль восприятия реляционных данных.
Во многих средах поддерживается модель множества записей (Record Set) - одна из основополагающих структур данных, имитирующая табличную форму представления содержимого базы данных. Инструментальными системами предлагаются даже графические интерфейсные элементы, реализующие схему множества записей. С каждой таблицей базы данных следует сопоставить соответствующий объект типа шлюз таблицы данных (Table Data Gateway) (рис. 3.8), который содержит методы активизации запросов, возвращающих множество записей.
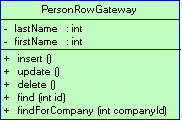
Рисунок 3.7 Для каждой записи, возвращаемой запросом, создается экземпляр шлюза записи данных

Рисунок 3.8 Для каждой таблицы базы данных создается экземпляр шлюза таблицы данных
Тот факт, что шлюз таблицы данных удачно сочетается с множеством записей, обеспечивает такому варианту шлюза очевидные преимущества при использовании модуля таблицы (Table Module). Это типовое решение следует иметь в виду и при работе с хранимыми процедурами. Нередко предпочтительно осуществлять доступ к базе данных только при посредничестве хранимых процедур, а не с помощью прямых обращений.
В подобной ситуации, определяя шлюз таблицы данных для каждой таблицы, следует
предусмотреть и коллекцию соответствующих хранимых процедур. Возможно так же создание в памяти еще и дополнительного шлюза таблицы данных, выполняющий функцию оболочки, которая могла бы скрыть механизм вызовов хранимых процедур.
При использовании модели предметной области (Domain Model) возникают другие альтернативы. В этом контексте уместно применять и шлюз записи данных, и шлюз таблицы данных. Впрочем, иногда в данной ситуации эти решения могут оказаться не вполне целенаправленными или просто несостоятельными.
В простых приложениях модель предметной области представляет отнюдь не сложную структуру, которая может содержать по одному классу домена в расчете на каждую таблицу базы данных. Объекты таких классов часто снабжены умеренно сложной бизнес-логикой. В этом случае имеет смысл возложить на каждый из них и ответственность за ввод-вывод данных, что, по существу, равносильно применению решения активная запись (Active Record) (рис. 3.9). Это решение можно воспринимать и так, будто, начав со шлюза записи данных, мы добавили в класс порцию бизнес-логики (может быть, когда обнаружили в нескольких сценариях транзакции (Transaction Script) повторяющиеся фрагменты кода).
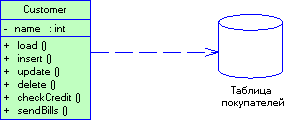
Рисунок 3.9 При использовании паттерна Active Record объект класса домена осведомлен о том, как взаимодействовать с базой данных
В подобного рода ситуациях дополнительный уровень опосредования, формируемый за счет применения шлюза, не представляет большой ценности. По мере усложнения бизнес-логики и возрастания значимости богатой модели предметной области простые решения типа активная запись начинают сдавать свои позиции. При разнесении бизнес-логики по все более мелким классам взаимно однозначное соответствие между классами домена и таблицами базы данных постепенно теряется. Реляционные базы данных не поддерживают механизм наследования, что затрудняет применение стратегий (strategies) и других развитых объектно-ориентированных типовых решений. А когда бизнес-логика становится все более беспорядочной, желательно иметь возможность ее тестирования без необходимости постоянно обращаться к базе данных. С усложнением модели предметной области все эти обстоятельства вынуждают создавать промежуточные функциональные уровни. Так, решение типа шлюза способно устранить некоторые проблемы, но оно все еще оставляет нас с моделью предметной области, тесно привязанной к схеме базы данных. В результате при переходе от полей шлюза к полям объектов домена приходится выполнять определенные преобразования, которые приводят к усложнению объектов домена.

Рисунок 3.10 Преобразователь данных изолирует объекты домена от базы данных
Более удачный вариант состоит в том, чтобы изолировать модель предметной области от базы данных, возложив на промежуточный слой всю полноту ответственности за отображение объектов домена в таблицы базы данных. Подобный преобразователь данных (Data Mapper) (рис. 3.10) обслуживает все операции загрузки и сохранения информции, инициируемые бизнес-логикой, и позволяет независимо варьировать как модель предметной области, так и схему базы данных. Это наиболее сложное из архитектурных решений, обеспечивающих соответствие между объектами приложения и реляционными структурами, но его неоспоримое преимущество заключается в полном обособлении двух слоев.
Я не рекомендовал бы рассматривать шлюз в качестве основного механизма сохранения данных в контексте модели предметной области. Если бизнес-логика действительно проста и степень соответствия между классами и таблицами базы данных высока, удачной альтернативой окажется типовое решение активная запись. Если же вам приходится иметь дело с чем-то более сложным, самым лучшим выбором, вероятнее всего, будет преобразователь данных.
Рассмотренные типовые решения нельзя считать взаимоисключающими. В большинстве случаев речь будет идти о механизме сохранения информации из неких структур памяти в базе данных. Для этого придется выбрать одно из перечисленных решений - смешение подходов чревато неразберихой. Но даже если в качестве инструмента доступа к базе данных применяется, скажем, преобразователь данных, для создания оболочек таблиц или служб, трактуемых как внешние интерфейсы, вы вправе использовать, например, шлюз. Здесь и ниже, употребляя слово таблица (table), имеется в виду, что обсуждаемые приемы и решения применимы в равной мере ко всем данным, отличающимся табличным характером: к хранимым процедурам (stored procedures), представлениям (views), а так-же к промежуточным результатам выполнения "традиционных" запросов и хранимых процедур. К сожалению, какой-либо общий термин, который охватывал бы все эти понятия, отсутствует
Операции обновления (update) содержимого источников, не являющихся хранимыми таблицами, очевидно, более сложны, поскольку представление далеко не всегда можно модифицировать напрямую — вместо этого приходится манипулировать таблицами, на основе которых оно создано. В этом случае инкапсуляция представления/запроса с помощью подходящего типового решения — хороший способ сосредоточить логику операций обновления в одном месте, что делает использование виртуальных структур более простым и безопасным.
Впрочем, проблемы все еще остаются. Непонимание природы формирования виртуальных таблиц приводит к несогласованности операций: если последовательно выполнить операции обновления двух различных структур, построенных на основе одних и тех же хранимых таблиц, вторая операция способна повлиять на результаты первой. Конечно, в логике обновления можно предусмотреть соответствующие проверки, направленные на то, чтобы избежать возникновения подобных эффектов, но какую цену за все это придется заплатить.
Я обязан также упомянуть о самом простом способе сохранения данных, который можно использовать даже в наиболее сложных моделях предметной области. Еще на заре эпохи объектов многие осознали, что существует фундаментальное расхождение между реляционной и объектной моделями; это послужило стимулом создания объектно-ориентированных СУБД, расширяющих парадигму до аспектов сохранения информации об объектах на дисках. При работе с объектно-ориентированной базой данных вам не нужно заботиться об отображении объектов в реляционные структуры. В вашем распоряжении набор взаимосвязанных объектов, а о том, как и когда их считывать или сохранять, "беспокоится" СУБД. Помимо того, с помощью механизма транзакций вы вправе группировать операции и управлять совместным доступом к объектам. Для программиста все это выглядит так, словно он взаимодействует с неограниченным пространством объектов, размещенных в оперативной памяти.
Главное преимущество объектно-ориентированных баз данных - повышение производительности разработки приложений: хотя какие-либо воспроизводимые тестовые показатели официально не публиковались, в неформальных беседах постоянно высказываются суждения о том, что затраты на обеспечение соответствия между объектами приложения и реляционными структурами традиционной базы данных составляют приблизительно треть от общей стоимости проекта и не снижаются в течение всего цикла сопровождения системы.
В большинстве случаев, однако, объектно-ориентированные базы данных применения не находят, и основная причина такого положения вещей - риск. За реляционными СУБД стоят тщательно разработанные, хорошо знакомые и проверенные жизнью технологии, поддерживаемые всеми крупными поставщиками систем баз данных на протяжении длительного времени. SQL представляет собой в достаточной мере унифицированный интерфейс для разнообразных инструментальных средств.
Если у вас нет возможности или желания воспользоваться объектно-ориентированной базой данных, то, делая ставку на модель предметной области, вы должны серьезно изучить варианты приобретения инструментов отображения объектов в реляционные структуры. Хотя рассмотренные в типовые решения сообщат вам многое из того, что необходимо знать для конструирования эффективного преобразователя данных, на этом поприще от вас все еще потребуются значительные усилия. Поставщики коммерческих инструментов, предназначенных для "связывания" объектно-ориентированных приложений с реляционными базами данных, затратили многие годы на разрешение подобных проблем, и их программные продукты во многом более изобретательны, гибки и мощны, нежели те, которые можно "состряпать" кустарным образом. Сразу оговорюсь, что они недешевы, но затраты на их возможную покупку следует сопоставить со значительными расходами, которые вам придется понести, избрав путь самостоятельного создания и сопровождения этого слоя программного кода.
Нельзя не вспомнить о попытках разработки образцов слоя кода в стиле объектно-ориентированных СУБД, способного взаимодействовать с реляционными системами. В мире Java таким "зверем", например, является JDO, но о достоинствах или недостатках этой технологии пока нельзя сказать ничего определенного. У меня слишком малый опыт ее применения, чтобы приводить на страницах этой книги какие-либо категорические заключения.
Даже если вы решились на приобретение готовых инструментов, знакомство с представленными здесь типовыми решениями вовсе не помешает. Хорошие инструментальные системы предлагают обширный арсенал альтернатив "подключения" объектов к реляционным базам данных, и компетентность в сфере типовых решений поможет вам прийти к осмысленному выбору. Не думайте, что система в одночасье избавит вас от всех проблем; чтобы заставить ее работать эффективно, вам придется приложить изрядные усилия.
3.4.3 Паттерн Table Data Gateway
Название
Table Data Gateway (шлюз таблицы данных)
Назначение
Использование SQL в логике приложений может быть связано с некоторыми проблемами. Не все разработчики владеют языком SQL или хорошо в нем разбираются. В свою очередь, администраторы СУБД должны иметь удобный доступ к командам SQL для настройки и расширения своих баз данных.
Типовое решение шлюз таблицы данных содержит в себе все команды SQL, необходимые для извлечения, вставки, обновления и удаления данных из таблицы или представления. Методы этого типового решения используются другими объектами для взаимодействия с базой данных.
Принцип действия
Интерфейс шлюза таблицы данных чрезвычайно прост. Обычно он включает в себя несколько методов поиска, предназначенных для извлечения данных, а также методы обновления, вставки и удаления. Каждый метод передает входные параметры вызову соответствующей команды SQL и выполняет ее в контексте установленного соединения с базой данных. Как правило, это типовое решение не имеет состояний, поскольку всего лишь передает данные в таблицу и из таблицы.
Пожалуй, наиболее интересная особенность шлюза таблицы данных - это то, как он возвращает результат выполнения запроса. Даже простой запрос типа "найти данные с указанным идентификатором" может возвратить несколько записей. Это не составляет проблемы для сред разработки, допускающих множественные результаты, однако большинство классических языков программирования позволяют возвращать только одно значение.
В качестве альтернативы можно отобразить таблицу базы данных в какую-нибудь простую структуру наподобие коллекции. Это позволит работать с множественными результатами, однако потребует копирования данных из результирующего множества записей базы данных в упомянутую коллекцию. На мой взгляд, этот способ не слишком хорош, поскольку не подразумевает выполнения проверки времени компиляции и не предоставляет явного интерфейса, что приводит к многочисленным опечаткам программистов, ссылающихся на содержимое коллекции. Более удачным решением является использование универсального объекта переноса данных (Data Transfer Object).
Вместо всего перечисленного результат выполнения SQL-запроса может быть возвращен в виде множества записей (Record Set). Вообще говоря, это не совсем корректно, поскольку объект, расположенный в оперативной памяти, не должен "знать" об SQL-интерфейсе. Кроме того, если вы не можете создавать множества записей в собственном коде, это вызовет определенные трудности при замене базы данных файлом. Тем не менее этот способ весьма эффективен во многих средах разработки, широко использующих множество записей, например в таких, как .NET. В этом случае шлюз таблицы данных хорошо сочетается с модулем таблицы (Table Module). Если все обновления таблиц выполняются через шлюз таблицы данных, результирующие данные могут ыть основаны на виртуальных, а не на реальных таблицах, что уменьшает зависимость кода от базы данных.
Если вы используете модель предметной области (Domain Model), методы шлюза таблицы данных могут возвращать соответствующий объект домена. Следует, однако, иметь в виду, что это подразумевает двунаправленные зависимости между объектами домена и шлюзом. И те и другие тесно связаны между собой, поэтому необходимость создания таких зависимостей не слишком усложняет дело, однако мне это все равно не нравится.
Как правило, для каждой таблицы базы данных создается собственный шлюз таблицы данных. Впрочем, в наиболее простых случаях можно ограничиться разработкой одного шлюза таблицы данных, который будет включать в себя все методы для всех таблиц. Кроме того, отдельные шлюзы таблицы данных могут быть созданы для представлений (виртуальных таблиц) и даже для некоторых запросов, не хранящихся в базе данных в форме представлений. Конечно же, шлюз таблицы данных для представления не сможет обновлять данные и поэтому не будет обладать соответствующими методами. Тем не менее, если вы можете сами обновлять таблицы, инкапсуляция процедур обновления в методах типового решения шлюз таблицы данных - прекрасный выбор.
Применимость
Принимая решение об использовании шлюза таблицы данных, как, впрочем, и шлюза записи данных (Row Data Gateway), необходимо подумать о том, следует ли вообще обращаться к шлюзу и если да, то к какому именно.
Шлюз таблицы данных — это наиболее простое типовое решение интерфейса базы данных, поскольку оно замечательно отображает таблицы или записи баз данных на объекты. Кроме того, шлюз таблицы данных естественным образом инкапсулирует точную логику доступа к источнику данных. Это решение крайне редко используют с моделью предметной области, потому что гораздо большей изолированности модели предметной области от источника данных можно добиться с помощью преобразователя данных (Data Mapper). Типовое решение шлюз таблицы данных особенно хорошо сочетается с модулем таблицы. Методы шлюза таблицы данных возвращают структуры данных в виде множеств записей, с которыми затем работает модуль таблицы. На самом деле другой подход отображения базы данных для модуля таблицы придумать просто невозможно (по крайней мере, мне так кажется).
Подобно шлюзу записи данных, шлюз таблицы данных прекрасно подходит для использования в сценариях транзакции (Transaction Script). В действительности выбор од- ного из нескольких типовых решений зависит только от того, как они обрабатывают множественные результаты. Некоторые предпочитают осуществлять передачу данных посредством объекта переноса данных, однако мне это решение кажется более трудоемким (если только этот объект уже не был реализован где-нибудь в другом месте вашего проекта). Рекомендую использовать шлюз таблицы данных в том случае, если его представление результирующего множества данных подходит для работы со сценарием транзакции.
Что интересно, шлюзы таблицы данных могут выступать в качестве посредника при обращении к базе данных преобразователей данных. Правда, когда весь код пишется вручную, это не всегда нужно, однако данный прием может быть весьма эффективен, если для реализации шлюза таблицы данных используются метаданные, а реальное отображение содержимого базы данных на объекты домена выполняется вручную.
Одно из преимуществ использования шлюза таблицы данных для инкапсуляци доступа к базе данных состоит в том, что этот интерфейс может применяться и для обращения к базе данных с помощью средств языка SQL, и для работы с хранимыми процедурами. Более того, хранимые процедуры зачастую сами организованы в виде шлюзов таблицы данных. В этом случае хранимые процедуры, предназначенные для вставки и обновления данных, инкапсулируют реальную структуру таблицы. В свою очередь, процедуры поиска могут возвращать представления, что позволяет скрыть фактическую структуру используемой таблицы.
3.4.4 Паттерн Row Data Gateway
Название
Row Data Gateway (шлюз записи данных)
Назначение
Реализация доступа к базам данных в объектах, расположенных в оперативной памяти, имеет ряд недостатков. Прежде всего, если этим объектам присуща собственная бизнес-логика, добавление кода доступа к базе данных значительно повышает их сложность. Кроме того, это серьезно усложняет тестирование. Если объекты, расположенные в оперативной памяти, связаны с базой данных, тестирование выполняется крайне медленно из-за проблем, вызванных необходимостью доступа к базе данных. Особенно раздражает, когда приходится осуществлять доступ к нескольким базам данных, имеющим небольшие (но крайне досадные!) расхождения в реализации SQL
Типовое решение шлюз записи данных предоставляет в ваше распоряжение объекты, которые полностью аналогичны записям базы данных, однако могут быть доступны с помощью обычных механизмов используемого языка программирования. Все деталидоступа к источнику данных скрыты за интерфейсом.
Принцип действия
Шлюз записи данных выступает в роли объекта, полностью повторяющего одну запись, например одну строку таблицы базы данных. Каждому столбцу таблицы соответствует поле записи. Обычно шлюз записи данных должен выполнять все возможные преобразования типов источника данных в типы, используемые приложением, однако эти преобразования весьма просты. Рассматриваемое типовое решение содержит все данные о строке, поэтому клиент имеет возможность непосредственного доступа к шлюзу записи данных. Шлюз выступает в роли интерфейса к строке данных и прекрасно подходит для применения в сценариях транзакции (Transaction Script).
При реализации шлюза записи данных возникает вопрос: куда "пристроить" методы поиска, генерирующие экземпляр данного типового решения? Разумеется, можно воспользоваться статическими методами поиска, однако они исключают возможность полиморфизма (что могло бы пригодиться, если понадобится определить разные методы поиска для различных источников данных). В подобной ситуации часто имеет смысл создать отдельные объекты поиска, чтобы у каждой таблицы реляционной базы данных был один класс для проведения поиска и один класс шлюза для сохранения результатов этого поиска (рис. 3.11).
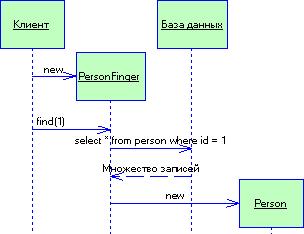
Рисунок 3.11 Взаимодействие со шлюзом записи данных для поиска нужной строки
Иногда шлюз записи данных трудно отличить от активной записи (Active Record). В этом случае следует обратить внимание на наличие какой-либо логики домена; если она есть, значит, это активная запись. Реализация шлюза записи данных должна включать в себя только логику доступа к базе данных и никакой логики домена.
Как и другие формы табличной инкапсуляции, шлюз записи данных можно применять не только к таблице, но и к представлению или запросу. Конечно же, в последних случаях существенно осложняется выполнение обновлений, поскольку приходится обновлять таблицы, на основе которых были созданы соответствующие представления или запросы. Кроме того, если с одними и теми же таблицами работают два шлюза записи данных, обновление второго шлюза может аннулировать обновление первого. Универсального способа предотвратить эту проблему не существует; разработчикам просто необходимо следить за тем, как построены виртуальные шлюзы записи данных. В конце концов, это же может случиться и с обновляемыми представлениями. Разумеется, вы можете вообще не реализовать методы обновления.
Шлюзы записи данных довольно трудоемки в написании. Тем не менее генерацию их кода можно значительно облегчить посредством типового решения отображение метаданных (Metadata Mapping). В этом случае весь код, описывающий доступ к базе данных, может быть автоматически сгенерирован в процессе сборки проекта.
Применимость
Принимая решение об использовании шлюза записи данных, необходимо подумать о двух вещах: следует ли вообще использовать шлюз, и если да, то какой именно — шлюз записи данных или шлюз таблицы данных (Table Data Gateway).
Как правило, шлюз записи данных используют вместе со сценарием транзакции. В этом случае доступ к базе данных легко реализовать таким образом, чтобы соответствующий код мог повторно использоваться другими сценариями транзакции.
Шлюз записи данных не используют с моделью предметной области (Domain Model). Если отображение на объекты домена достаточно простое, его можно реализовать и с помощью активной записи, не добавляя дополнительный слой кода. Если же отображение сложное, для его реализации рекомендуется применить преобразователь данных (Data Mapper). Последний лучше справляется с отделением структуры данных от объектов домена, потому что объектам домена не нужно знать о структуре базы данных. Конечно же, шлюз записи данных можно использовать, чтобы скрыть структуру базы данных от объектов домена. Это очень удобно, если вы собираетесь изменить структуру базы данных и не хотите менять логику домена. Тем не менее в этом случае у вас появится три различных представления данных: одно в бизнес-логике, одно в шлюзе записи данных и еще одно в базе данных. Для крупномасштабных систем это слишком много. Поэтому обычно используют шлюзы записи данных, отражающие структуру базы данных.
Интересно, что шлюз записи данных и преобразователь данных вполне могут сосуществовать. Несмотря на то что с первого взгляда это кажется излишней тратой сил, сочетание шлюза записи данных и преобразователя данных может оказаться весьма эффективным в том случае, если первый автоматически генерируется на основе метаданных, а второй создается вручную.
Если шлюз записи данных используется со сценарием транзакции, вы можете заметить, что в различных сценариях повторяется одна и та же бизнес-логика, которую можно было бы реализовать в шлюзе записи данных. Перенос этой логики в шлюз записи данных превратит его в активную запись. Это весьма удачное решение, поскольку позволяет избежать дублирования элементов бизнес-логики.
3.4.5 Паттерн Active Record
Название
Active Record (активная запись)
Назначение
Объект, выполняющий роль оболочки для строки таблицы или представления базы данных. Он инкапсулирует доступ к базе данных и добавляет к данным логику домена
Этот объект охватывает и данные и поведение. Большая часть его данных является постоянной и должна храниться в базе данных. В типовом решении активная запись используется наиболее очевидный подход, при котором логика доступа к данным включается в объект домена. В этом случае все знают, как считывать данные из базы данных и как их записывать в нее.
Принцип действия
В основе типового решения активная запись лежит модель предметной области (Domain Model), классы которой повторяют структуру записей используемой базы данных. Каждая активная запись отвечает за сохранение и загрузку информации в базу данных, а также за логику домена, применяемую к данным. Это может быть вся бизнес-логика приложения. Впрочем, иногда некоторые фрагменты логики домена содержатся в сценариях транзакции (Transaction Script), а общие элементы кода, ориентированные на работу с данными, в активной записи.
Структура данных активной записи должна в точности соответствовать таковой в таблице базы данных: каждое поле объекта должно соответствовать одному столбцу таблицы. Значения полей следует оставлять такими же, какими они были получены в результате выполнения SQL-команд; никакого преобразования на этом этапе делать не нужно. При необходимости вы можете применить отображение внешних ключей (Foreign Key Mapping), однако это не обязательно. Активная запись может применяться к таблицам или представлениям (хотя в последнем случае реализовать обновления будет значительно сложнее). Использование представлений особенно удобно при составлении отчетов.
Как правило, типовое решение активная запись включает в себя методы, предназначенные для выполнения следующих операций:
- создание экземпляра активной записи на основе строки, полученной в результате выполнения SQL-запроса;
- создание нового экземпляра активной записи для последующей вставки в таблицу;
- статические методы поиска, выполняющие стандартные SQL-запросы и возвращающие активные записи;
- обновление базы данных и вставка в нее данных из активной записи;
- извлечение и установка значений полей (get и set-методы);
- реализация некоторых фрагментов бизнес-логики.
Методы извлечения и установки значений полей могут выполнять и другие действия, например преобразование типов SQL в типы, используемые приложением. Кроме того, get-метод может возвращать соответствующую активную запись таблицы, с которой связана текущая таблица (путем просмотра первой), даже если для структуры данных не было определено поле идентификации (Identity Field).
Классы активной записи довольно удобны с точки зрения разработчиков, однако непозволяют им полностью абстрагироваться от реляционной базы данных. Впрочем, это не так уж плохо, поскольку дает возможность использовать меньше типовых решений, предназначенных для отображения объектной модели на базу данных.
Активная запись очень похожа на шлюз записи данных (Row Data Gateway). Принципиальное отличие между ними состоит в том, что шлюз записи данных содержит только логику доступа к базе данных, в то время как активная запись содержит и логику доступа к данным, и логику домена. Как это часто бывает в мире программного обеспечения, граница между упомянутыми типовыми решениями весьма приблизительна, однако игнорировать ее все-таки не следует.
Поскольку активная запись тесно привязана к базе данных, рекомендую использовать в этом типовом решении статические методы поиска. Однако нет смысла выделть методы поиска в отдельный класс, как это делалось в шлюзе записи данных (здесь это не нужно, да и тестировать будет легче).
Как и другие типовые решения, предназначенные для работы с таблицами, активную запись можно применять не только к таблицам, но и к представлениям или запросам.
Применимость
Активная запись хорошо подходит для реализации не слишком сложной логики домена, в частности операций создания, считывания, обновления и удаления. Кроме того, она прекрасно справляется с извлечением и проверкой на правильность отдельной записи. Как уже отмечалось, при разработке модели предметной области основная проблема
заключается в выборе между активной записью и преобразователем данных (Data Mapper). Преимуществом активной записи является простота ее реализации. Недостаток же состоит в том, что активные записи хороши только тогда, когда точно отображаются на таблицы базы данных (изоморфная схема). Если бизнес-логика приложения достаточно сложна, вам наверняка захочется использовать имеющиеся отношения, коллекции, наследование и т.п. Все это не слишком хорошо отображается на активную запись, а добавление этих элементов "по частям" приведет к страшной неразберихе. В подобных ситуациях лучше воспользоваться преобразователем данных.
Еще одним недостатком использования активной записи является тесная зависимость структуры ее объектов от структуры базы данных. В этом случае изменить структуру базы данных или активной записи довольно сложно, а ведь по мере развития проекта подобная необходимость возникает очень и очень часто.
Активную запись хорошо сочетать со сценарием транзакции, особенно если вас смущает постоянное повторение одного и того же кода и сложность обновления таблиц и сценариев; подобные ситуации нередко сопровождают использование сценариев транзакции. В этом случае вы можете приступить к созданию активных записей, постепенно перенося в них повторяющуюся логику. В качестве еще одного полезного приема могу порекомендовать создать для таблицы оболочку в виде шлюза (Gateway) и затем постепенно перенести в нее логику, превращая шлюз в активную запись.
3.4.6 Паттерн Data Mapper
Название
Data Mapper (преобразователь данных)
Назначение
Слой преобразователей (Mapper), который осуществляет передачу данных между объектами и базой данных, сохраняя последние независимыми друг от друга и от самого преобразователя.
Объекты и реляционные СУБД используют разные механизмы структурирования данных. В реляционных базах данных не отображаются многие характеристики объектов, в частности коллекции и наследование. При построении объектной модели с большим объемом бизнес-логики эти механизмы позволяют лучше организовать данные и соответствующее им поведение. С другой стороны, использование подобных механизмов приводит к несовпадению объектной и реляционной схем.
Объектная модель и реляционная СУБД должны обмениваться данными. Несовпадение схем делает эту задачу крайне сложной. Если объект "знает" о структуре реляционной базы данных, изменение одного из них приводит к необходимости изменения другого.
Типовое решение преобразователь данных представляет собой слой программного обеспечения, которое отделяет объекты, расположенные в оперативной памяти, от базы данных. В функции преобразователя данных входит передача данных между объектами и базой данных и изоляция их друг от друга. Благодаря использованию этого типового решения объекты, расположенные в оперативной памяти, могут даже не "подозревать" о самом факте присутствия базы данных. Им не нужен SQL-интерфейс и тем более схема базы данных. (В свою очередь, схема базы данных никогда не "знает" об объектах, которые ее используют.) Более того, поскольку преобразователь данных является разновидностью преобразователя, он полностью скрыт от уровня домена.
Принцип действия
Основной функцией преобразователя данных является отделение домена от источника данных, однако реализовать эту функцию можно лишь с учетом множества деталей. Кроме того, конструкция слоев отображения также может быть реализована по-разному.
Для начала рассмотрим пример элементарного преобразователя данных. Структура этого слоя слишком проста и, возможно, не стоит тех усилий, которые могут быть потрачены на ее реализацию. Кроме того, простая структура преобразователя влечет за собой применение более простых (и поэтому лучших) типовых решений, что вряд ли подойдет для реальных систем. Тем не менее начинать объяснение новых идей лучше именно на простых примерах.
В этом примере у нас есть классы Person и PersonMapper. Для загрузки данных в объект Person клиент вызывает метод поиска класса PersonMapper (рис. 3.12). Преобразователь использует коллекцию объектов для проверки, загружены ли данные о запрашиваемом лице; если нет, он их загружает. Выполнение обновлений показано на рис. 3.13. Клиент указывает преобразователю на необходимость сохранить объект домена. Преобразователь извлекает данные из объекта домена и отсылает их в базу данных.
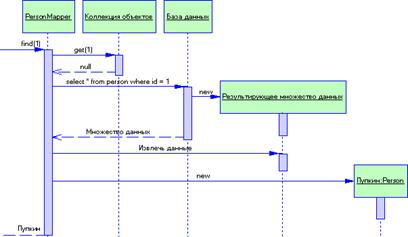
Рисунок 3.12 Извлечение данных их базы данных
При необходимости весь слой преобразователя данных может быть заменен, например, чтобы провести тестирование или чтобы использовать один и тот же уровень домена для работы с несколькими базами данных.
Рассмотренный нами элементарный преобразователь данных всего лишь отображает таблицу базы данных на эквивалентный ей объект по принципу "столбец-на-поле". Конечно же, в реальной жизни не все так просто. Преобразователи должны уметь обрабатывать классы, поля которых объединяются одной таблицей, классы, соответствующие нескольким таблицам, классы с наследованием, а также справляться со связыванием загруженных объектов. Все типовые решения объектно-реляционного отображения, рассмотренные в этой книге, так или иначе направлены на решение подобных проблем. Как правило, эти решения легче создавать на основе преобразователя данных, чем с помощью каких-либо других средств.
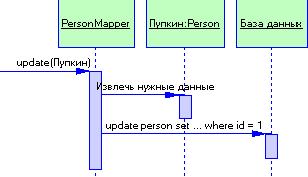
Рисунок 3.13 Сохранение данных
Для выполнения вставки и обновления данных слой отображения должен знать, какие объекты были изменены, какие созданы, а какие уничтожены. Кроме того, все эти действия нужно каким-то образом "уместить" в рамки транзакции. Хороший способ организовать механизм обновления — использовать типовое решение единица работы (Unit of Work).
В схеме, показанной на рис. 3.12, предполагалось, что один вызов метода поиска приводит к выполнению одного SQL-запроса. Это не всегда так. Например, загрузка данных о заказе, состоящем из нескольких пунктов, может включать в себя загрузку каждого пункта заказа. Обычно запрос клиента приводит к загрузке целого графа связанных между собой объектов. В этом случае разработчик преобразователя должен решить, как много объектов можно загрузить за один раз. Поскольку число обращений к базе данных должно быть как можно меньшим, методам поиска должно быть известно, как клиенты используют объекты, чтобы определить оптимальное количество загружаемых данных.
Описанный пример подводит нас к ситуации, когда в результате выполнения одного запроса преобразователь загружает несколько классов объектов домена. Если вы хотите загрузить заказы и пункты заказов, это можно сделать с помощью одного запроса, применив операцию соединения к таблицам заказов и заказываемых товаров. Полученное результирующее множество записей применяется для загрузки экземпляров класса заказов и класса пунктов заказа.
Как правило, объекты тесно связаны между собой, поэтому на каком-то этапе загрузку данных следует прерывать. В противном случае выполнение одного запроса может привести к загрузке всей базы данных! Для решения этой проблемы и одновременной минимизации влияния на объекты, расположенные в памяти, слой отображения использует загрузку по требованию (Lazy Load). По этой причине объекты приложения не могут совсем ничего не "знать" о слое отображения. Скорее всего, они должны быть "осведомлены" о методах поиска и некоторых других механизмах.
В приложении может быть один или несколько преобразователей данных. Если код для преобразователей пишется вручную, рекомендую создать по одному преобразователю для каждого класса домена или для корневого класса в иерархии доменов. Если же вы используете отображение метаданных (Metadata Mapping), можете ограничиться и одним классом преобразователя. В последнем случае все зависит от количества методов поиска. Если приложение достаточно большое, методов поиска может оказаться слишком много для одного преобразователя, поэтому разумнее будет разбить их на несколько классов, создав отдельный класс для каждого класса домена или корневой класс в иерархии доменов. У вас появится масса небольших классов с методами поиска, однако теперь разработчику будет гораздо проще найти то, что ему нужно.
Как и все другие поисковые механизмы баз данных, упомянутые методы поиска должны использовать коллекцию объектов, чтобы отслеживать, какие записи уже были считаны из базы данных. Для этого можно создать реестр (Registry) коллекций объектов либо назначить каждому методу поиска свою коллекцию объектов (при условии, что в течение одного сеанса каждый класс использует только один метод поиска).
Обращение к методам поиска
Чтобы получить возможность работать с объектом, его нужно загрузить из базы данных. Как правило, этот процесс запускается слоем представления, который выполняет загрузку некоторых начальных объектов, после чего передает управление слою домена. Слой домена последовательно загружает объект за объектом, используя установленные между ними ассоциации. Этот прием весьма эффективен при условии, что у слоя домена есть все объекты, которые должны быть загружены в оперативную память, или же что слой домена загружает дополнительные объекты только по мере необходимости путем применения загрузки по требованию.
Иногда объектам домена может понадобиться обратиться к методам поиска, определенным в преобразователе данных. Как показывает практика, удачная реализация загрузки по требованию позволяет полностью избежать подобных ситуаций. Конечно же, при разработке простых приложений применение ассоциаций и загрузки по требованию может не оправдать затраченных усилий, однако добавлять лишнюю зависимость объектов домена от преобразователя данных тоже не следует.
В качестве решения этой дилеммы можно предложить использование отделенного интерфейса (Separated Interface). В этом случае все методы поиска, применяемые кодом домена, можно вынести в интерфейсный класс и поместить его в пакет домена.
Отображение данных на поля объектов домена
Преобразователи должны иметь доступ к полям объектов домена. Зачастую это вызывает трудности, поскольку предполагает наличие методов, открытых для преобразователей, чего в бизнес-логике быть не должно. (Я исхожу из предположения, что вы не совершили страшную ошибку, оставив поля объектов домена открытыми (public).) Универсального решения этой проблемы не существует. Вы можете применить более низкий уровень видимости, поместив преобразователи "поближе" к объектам домена (например, в одном пакете, как это делается в Java), однако подобное решение крайне запутает глобальную картину зависимостей, потому что другие части системы, которые "знают" об объектах домена, не должны "знать" о преобразователях. Вы можете использовать механизм отражения, который зачастую позволяет обойти правила видимости конкретного языка программирования. Это довольно медленный метод, однако он может оказаться гораздо быстрее выполнения SQL-запроса. И наконец, вы можете использовать открытые методы, предварительно снабдив их полями состояния, генерирующими исключение при попытке использовать эти методы не для загрузки данных преобразователем. В этом случае назовите методы так, чтобы их по ошибке не приняли за обычные get и set методы.
Описанная проблема тесно связана с вопросом создания объекта. Последнее можно осуществить двумя способами. Первый состоит в том, чтобы создать объект с помощью конструктора с инициализацией, который сразу же заполнит новый объект всеми необходимыми данными. Второй заключается в создании пустого объекта и последующем заполнении его данными.
При использовании конструктора с инициализацией возникает проблема, связанная с наличием циклических ссылок. Если у вас есть два объекта, ссылающихся друг на друга, попытка загрузки первого объекта приведет к загрузке второго объекта, что, в свою очередь, снова приведет к загрузке первого объекта и так до тех пор, пока не произойдет переполнение стека. Возможный выход— описать частный случай (Special Case). Обычно это делается с использованием типового решения загрузка по требованию. Написание кода для частного случая - задача далеко не из легких, поэтому рекомендую попробовать что-нибудь другое, например воспользоваться конструктором без аргументов для создания пустого объекта (empty object). Создайте пустой объект и сразу же поместите его в коллекцию объектов. Теперь, если загружаемые объекты окажутся связанными циклической ссылкой, коллекция объектов возвратит нужное значение для прекращения "рекурсивной" загрузки.
Как правило, заполнение пустого объекта осуществляется посредством set-методов. Некоторые из них могут устанавливать значения полей, которые после загрузки данных должны оставаться неизменяемыми. Чтобы предотвратить случайное изменение этих полей после загрузки объекта, присвойте set-методам специальные имена и, возможно, оснастите их полями проверки состояния. Кроме того, вы можете выполнить загрузку данных с использованием механизма отражения.
Отображения на основе метаданных
Разрабатывая корпоративное приложение для взаимодействия с базой данных, необходимо решить, как поля объектов домена будут отображаться на столбцы таблиц базы данных. Самый простой (и часто самый лучший) способ выполнить это - явно описать отображение в коде, что требует создания по одному классу преобразователя на каждый объект домена. Преобразователь выполняет отображение путем присвоения значений и содержит в себе SQL-команды для доступа к базе данных (обычно они хранятся в виде текстовых констант). В качестве альтернативы этому способу можно предложить использование отображения метаданных, которое сохраняет метаданные таблиц в виде обыкновенных данных, в классе или в отдельном файле. Огромное преимущество метаданных заключается в том, что они позволяют вносить изменения в преобразователь путем генерации кода или применения отражающего программирования (reflective programming) без написания дополнительного кода вручную.
Применимость
В большинстве случаев преобразователь данных применяется для того, чтобы схема базы данных и объектная модель могли изменяться независимо друг от друга. Как правило, подобная необходимость возникает при использовании модели предметной области. Основным преимуществом преобразователя данных является возможность работы с моделью предметной области без учета структуры базы данных как в процессе проектирования, так и во время сборки и тестирования проекта. В этом случае объектам домена ничего не известно о структуре базы данных, поскольку все отображения выполняются преобразователями.
Применение преобразователей данных помогает и в написании кода, поскольку по-зволяет работать с объектами домена без необходимости понимать принцип хранения соответствующей информации в базе данных. Изменение модели предметной области не требует изменения структуры базы данных и наоборот, что крайне важно при наличии сложных отображений, особенно при использовании уже существующих баз данных.
Разумеется, за все удобства нужно платить. "Ценой" использования преобразователя данных является необходимость реализации дополнительного слоя кода, чего можно избежать, применив, скажем, активную запись (Active Record). Поэтому основным критерием выбора того или иного типового решения является сложность бизнес-логики. Если бизнес-логика довольно проста, ее, скорее всего, можно реализовать и без применения модели предметной области или преобразователя данных. В свою очередь, реализация более сложной логики невозможна без использования модели предметной области и, как следствие этого, преобразователя данных.
Я бы не стал использовать преобразователь данных без модели предметной области. Но можно ли использовать модель предметной области без преобразователя данных? Если модель довольно проста, а ее разработчики сами контролируют изменения структуры базы данных, доступ объектов домена к базе данных можно осуществлять непосредственно с помощью активной записи. В этом случае роль преобразователя с успехом выполняют сами объекты домена. Тем не менее по мере усложнения логики домена функции доступа к базе данных лучше вынести в отдельный слой.
Хочу также обратить ваше внимание на то, что вам не понадобится разрабатывать полнофункциональный слой отображения базы данных на объекты домена с "нуля". Это весьма сложно, да и на рынке программного обеспечения существует масса подобных продуктов. В большинстве случаев рекомендую приобрести готовый преобразователь, вместо того чтобы заниматься его разработкой самому.
3.4.7 Функциональные проблемы
Когда речь заходит о взаимном отображении объектов и таблиц реляционной базы данных, внимание обычно сосредоточивается на структурных аспектах, то есть на том, как следует соотносить таблицы и объекты. Однако самая трудная часть проблемы - это выбор и обоснование архитектурной и функциональной составляющих.
Обсудив основные варианты архитектурных решений, рассмотрим функциональную (поведенческую) сторону, в частности вопрос о том, как обеспечить загрузку различных объектов и сохранение их в базе данных. На первый взгляд это не кажется слишком сложной задачей: объект можно снабдить соответствующими методами загрузки ("load") и сохранения ("save"). Именно такой путь целесообразно избрать, например, при использовании решения активная запись (Active Record). Загружая в память большое количество объектов и модифицируя их, система должна следить за тем, какие объекты подверглись изменению, и гарантировать сохранение их содержимого в базе данных. Если речь идет всего о нескольких записях, это просто. Но по мере увеличения числа объектов растут и проблемы: как быть, скажем, в такой далеко не самой сложной ситуации, когда необходимо создать записи, которые должны ссылаться на ключевые значения друг друга.
При выполнении операций считывания или изменения объектов система должна гарантировать, что состояние базы данных, с которым вы имеете дело, остается согласованным. Так, например, на результат загрузки данных не должны влиять изменения, вносимые другими процессами. В противном случае итог операции окажется непредсказуемым. Подобные вопросы, относящиеся к дисциплине управления параллельными заданиями, весьма серьезны. Они обсуждаются разделе "Управление параллельными заданиями".
Типовым решением, имеющим существенное значение для преодоления такого рода проблем, является единица работы (Unit of Work), использование которой позволяет отследить, какие объекты считываются и какие модифицируются, и обслужить операции обновления содержимого базы данных. Автору прикладной программы нет нужды явно вызывать методы сохранения — достаточно сообщить объекту единица работы о необходимости фиксации (commit) результатов в базе данных. Типовое решение единица работы упорядочивает все функции по взаимодействию с базой данных и сосредоточивает в одном месте сложную логику фиксации. Его лучшие качества проявляются именно тогда, когда интерфейс между приложением и базой данных становится особенно запутанным.
Решение единица работы удобно воспринимать в виде объекта, действующего как контроллер процессов отображения объектов в реляционные структуры. В отсутствие такового роль контроллера, принимающего решения о том, когда и как загружать и сохранять объекты приложения, обычно выполняет слой бизнес-логики. В процессе загрузки данных необходимо тщательно следить за тем, чтобы ни один из объектов не был считан дважды, иначе в памяти будут созданы два объекта, соответствующих одной и той же записи таблицы базы данных. Попробуйте обновить каждую из них, и неприятности не заставят себя ждать. Чтобы уйти от проблем, необходимо вести учет каждой считанной записи, а поможет в этом типовое решение коллекция объектов (Identity Map). Каждый раз при необходимости считывания порции данных вначале следует проверить, не содержится ли она в коллекции объектов. Если информация уже загружалась, можно предусмотреть возврат ссылки на нее. В этом случае любые попытки изменения данных будут скоординированы. Еще одно преимущество - возможность избежать дополнительного обращения к базе данных, поскольку коллекция объектов действует как кэш-память. Не забывайте, однако, что главное назначение коллекции объектов - учет идентификационных номеров объектов, а не повышение производительности приложения.
При использовании модели предметной области (Domain Model) связанные объекты загружаются совместно таким образом, что операция считывания одного объекта инициирует загрузку другого. Если связями охвачено много объектов, считывание любого из них приводит к необходимости загружать из базы данных целый граф объектов. Чтобы исключить подобное неэффективное поведение системы, необходимо умерить аппетит, сократив количество загружаемых объектов, но оставить за собой право завершения операции, если потребность в дополнительной информации действительно возникнет. Типовое решение загрузка по требованию (Lazy Load,) предполагает использование специальных меток вместо ссылок на реальные объекты. Существует несколько вариаций схемы, но во всех случаях реальный объект загружается только тогда, когда предпринимается попытка проследовать по ссылке, которая его адресует. Решение загрузка по требованию позволяет оптимизировать число обращений к базе данных.
3.4.8 Считывание данных
Рассматривая проблему считывания информации из базы данных, рекомегдуется трактовать предназначенные для этого методы в виде функций поиска (finders), скрывающих посредством соответствующих входных интерфейсов SQL-выражения формата "select". Примерами подобных методов могут служить find (id) или findForCustomer (customer). Разумеется, если ваше приложение оперирует тремя десятками выражений "select" с различными критериями выбора, указанная схема становится чересчур громоздкой, но такие ситуации, к счастью, редки. Принадлежность методов зависит от вида используемого интерфейсного типового решения. Если каждый класс, обеспечивающий взаимодействие с базой данных, привязан к определенной таблице, в его состав наряду с методами вставки и замены уместно включить и методы поиска. Если же объект класса соответствует отдельной записи данных, требуется иной подход. В этом случае можно попробовать сделать методы поиска статическими, но за это придется заплатить некоторой долей гибкости, в частности вам более не удастся в целях тестирования заменить базу данных фиктивной службой (Service Stub). Чтобы избежать подобных проблем, лучше предусмотреть специальные классы поиска, включив в состав каждого из них методы, обеспечивающие инкапсуляцию тех или иных SQL-запросов. В результате выполнения запроса метод возвращает коллекцию объектов, соответствующих определенным записям данных.
Применяя методы поиска, следует помнить, что они выполняются в контексте состояния базы данных, а не состояния объекта. Если после создания в памяти объектов-записей данных, отвечающих некоторому критерию, вы активизируете запрос, который предполагает поиск записей, удовлетворяющих тому же критерию, то очевидно, что объекты, созданные, но не зафиксированные в базе данных, в результат обработки запроса не попадут.
При считывании данных проблемы производительности могут приобретать первостепенное значение. Необходимо помнить несколько эмпирических правил. Старайтесь при каждом обращении к базе данных извлекать немного больше записей, чем нужно. В частности, не выполняйте один и тот же запрос повторно для приобретения дополнительной информации. Почти всегда предпочтительнее получить как можно больше данных, но нужно отдавать себе отчет в том, что при использовании пессимистической стратегии управления параллельными заданиями это может привести к ненужному блокированию большого количества записей. Например, если необходимо найти 50 записей, удовлетворяющих определенному условию, лучше выполнить запрос, возвращающий 200 записей, и применить для отбора искомых дополнительную логику, чем инициировать 50 отдельных запросов.
Другой способ исключить необходимость неоднократного обращения к базе данных связан с применением операторов соединения (join), позволяющих с помощью одного запроса извлечь информацию из нескольких таблиц. Итоговый набор записей может содержать больше информации, чем требуется, но скорость его получения, вероятно, выше, чем в случае выполнения нескольких запросов, возвращающих в результате те же данные. Для этого следует воспользоваться шлюзом (Gateway), охватывающим информацию из нескольких таблиц, которые подлежат соединению, или преобразователем данных (Data Mapper), позволяющим загрузить несколько объектов домена с помощью единственного вызова.
Применяя механизм соединения таблиц, имейте в виду, что СУБД способны эффективно обслуживать запросы, в которых соединению подвергнуто не более трех-четырех таблиц. В противном случае производительность системы существенно падает, хотя воспрепятствовать этому, по меньшей мере частично, удается, например, с помощью разумной стратегии кэширования представлений. Работу СУБД можно оптимизировать самыми разными способами, включая компактное группирование взаимосвязанных данных, тщательное проектирование индексов и кэширование порций информации в оперативной памяти. Все эти технологии, однако, выбиваются из контекста книги (хотя должны быть присущи сфере профессиональных интересов хорошего администратора баз данных).
Во всех случаях, тем не менее, следует учитывать особенности конкретных приложений и базы данных. Наставления общего характера хороши до определенного момента, когда необходимо как-то организовать способ мышления, но реальные обстоятельства всегда вносят свои коррективы. Достаточно часто СУБД и серверы приложений обладают сложными механизмами кэширования, затрудняющими дать хоть сколько-нибудь точную оценку производительности приложения. Никакое правило не обходится без исключений, так что тонкой настройки и доводки системы избежать не удастся.
3.4.9 Взаимное отображение объектов и реляционных структур
Во всех разговорах об объектно-реляционном отображении обычно и прежде всего имеется в виду обеспечение взаимно однозначного соответствия между объектами в памяти и табличными структурами базы данных на диске. Подобные решения, как правило, не имеют ничего общего с вариантами шлюза таблицы данных (Table Data Gateway) и находят ограниченное применение совместно с решениями типа шлюза записи данных (Row Data Gateway) и активной записи (Active Record), хотя все они, вероятно, окажутся востребованными в контексте преобразователя данных (Data Mapper).
3.4.9.1.1 Отображение связей
Главная проблема, которая обсуждается в этом разделе, обусловлена тем, что связи объектов и связи таблиц реализуются по-разному. Проблема имеет две стороны. Во-первых, существуют различия в способах представления связей. Объекты манипулируют связями, сохраняя ссылки в виде адресов памяти. В реляционных базах данных связь одной таблицы с другой задается путем формирования соответствующего внешнего ключа (foreign key). Во-вторых, с помощью структуры коллекции объект способен сохранить множество ссылок из одного поля на другие, тогда как правила нормализации таблиц базы данных допускают применение только однозначных ссылок. Все это приводит к расхождениям в структурах объектов и таблиц. Так, например, в объекте, представляющем сущность "заказ", совершенно естественно предусмотреть коллекцию ссылок на объекты, описывающие заказываемые товары, причем последним нет необходимости ссылаться на "родительский" объект заказа. Но в схеме базы данных все обстоит иначе: запись в таблице товаров должна содержать внешний ключ, указывающий на запись в таблице заказов, поскольку заказ не может иметь многозначного поля.
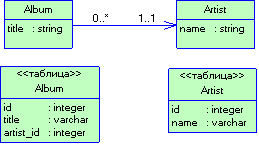
Рисунок 3.14 Пример использования паттерна Отображение внешних ключей для реализации однозначной ссылки
Чтобы решить проблему различий в способах представления связей, достаточно сохранять в составе объекта идентификаторы связанных с ним объектов-записей, используя типовое решение поле идентификации (Identity Field [4]), а также обращаться к этим значениям, если требуется прямое и обратное отображение объектов и ключей таблиц базы данных. Это довольно скучно, но вовсе не так трудно, если усвоить основные приемы. При считывании информации из базы данных для перехода от идентификаторов записей к объектам используется коллекция объектов (Identity Map [4]). Связи, задаваемой внешним ключом, отвечает типовое решение отображение внешних ключей (Foreign Key Mapping [4]), устанавливающее подходящую связь одного объекта с другим (рис. 3.14). Если в коллекции объектов ключа нет, необходимо либо считать его из базы данных, либо применить вариант загрузки по требованию (Lazy Load). При сохранении информации объект фиксируется в таблице базы данных в виде записи с соответствующим ключом, а все ссылки на другие объекты, если таковые существуют, заменяются значениями полей идентификации этих объектов.
Если объект способен содержать коллекцию ссылок, требуется более сложная версия отображения внешних ключей, пример которой представлен на рис. 3.15. В этом случае, чтобы отыскать все записи, содержащие идентификатор объекта-источника, необходимо выполнить дополнительный запрос (или воспользоваться решением загрузка по требованию). Для каждой считанной записи, удовлетворяющей критерию поиска, создается соответствующий объект, и ссылка на него добавляется в коллекцию. Для сохранения коллекции следует обеспечить сохранение каждого объекта в ней, гарантируя корректность значений внешних ключей. Операция может быть довольно сложной, особенно в том случае, когда приходится отслеживать динамику добавления объектов в коллекцию и их удаления. В крупных системах с подобной целью применяются подходы, основанные на метаданных (об этом речь идет несколько позже). Если объекты коллекции не используются вне контекста ее владельца, для упрощения задачи можно обратиться к типовому решению отображение зависимых объектов (Dependent Mapping).
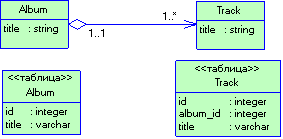
Рисунок 3.15. Пример использования паттерна Отображение внешних ключей для реализации коллекции ссылок
Совсем иная ситуация возникает, когда связь относится к категории "многие ко многим", то есть. коллекции ссылок присутствуют "с обеих сторон" связи. Примером может служить множество служащих и общий набор профессиональных качеств, отдельными из которых обладает каждый служащий. В реляционных базах данных проблема описания такой структуры преодолевается за счет создания дополнительной таблицы, содержащей пары ключей связанных сущностей (именно это предусмотрено в типовом решении отображение с помощью таблицы ассоциаций (Association Table Mapping), пример которого показан на рис. 3.16.

Рисунок 3.16 Пример использования паттерна Отображение с помощью таблицы ассоциаций для реализации связи «многие ко многим»
При работе с коллекциями принято полагаться на критерий упорядочения, с учетом которого она создана. В объектно-ориентированных языках программирования обшей практикой является использование типов упорядоченных коллекций, подобных спискам и массивам. Однако задача сохранения в реляционной базе данных содержимого коллекции с произвольным критерием упорядочения остается сложной. В качестве способов ее решения можно порекомендовать использование неупорядоченных множеств или определение критерия упорядочения на этапе выполнения запроса к коллекции (последний подход связан с большими затратами).
В некоторых случаях проблема обновления данных усугубляется из-за необходимости выполнять условия целостности на уровне ссылок (referential integrity). Современные СУБД позволяют откладывать (defer) проверку таких условий до завершения транзакции. Если "ваша" система такую возможность предоставляет, грех ею не воспользоваться. Если нет, система инициирует проверку после каждой операции записи. В такой ситуации вы обязаны соблюдать верный порядок прохождения операций. Не вдаваясь в детали, напомню, что один из подходов связан с построением и анализом графа, описывающего такой порядок, а другой состоит в задании жесткой схемы выполнения операций непосредственно в коде приложения. Иногда это позволяет снизить вероятность возникновения ситуаций взаимоблокировки (deadlock), для разрешения которых приходится осуществлять откат (rollback) тех или иных транзакций.
Для описания связей между объектами, преобразуемых во внешние ключи, используется типовое решение поле идентификации, но далеко не все связи объектов следует фиксировать в базе данных именно таким образом. Разумеется, небольшие объекты-значения (Value Object), описывающие, скажем, диапазоны дат или денежные величины, нецелесообразно представлять в отдельных таблицах базы данных. Объект-значение уместнее отображать в виде внедренного значения (Embedded Value), то есть набора полей объекта, "владеющего" объектом-значением. При необходимости загрузки данных в память объекты-значения можно легко создавать заново, не утруждая себя использованием коллекции объектов. Сохранить объект-значение также несложно - достаточно зафиксировать значения его полей в таблице объекта-владельца.
Можно пойти дальше и предложить модель группирования объектов-значений с сохранением их в таблице базы данных в виде единого поля типа крупный сериализованный
объект (Serialized LOB). Аббревиатура LOB происходит от словосочетания Large OBject и означает "крупный объект"; различают крупные двоичные объекты (Binary LOBs — BLOBs) и крупные символьные объекты (Character LOBs — CLOBs). Сериализация множества объектов в виде XML-документа — очевидный способ сохранения иерархических объектных структур. В этом случае для считывания исходных объектов будет достаточно одной операции. При выполнении большого количества запросов, предполагающих поиск мелких взаимосвязанных объектов (например, для построения диаграмм или обработки счетов), производительность СУБД часто резко падает, и крупные сериализованные объекты позволяют существенно снизить загрузку системы.
Недостаток такого подхода состоит в том, что в рамках "чистого" SQL сконструировать запросы к отдельным элементам сохраненной структуры не удастся. На помощь может прийти XML, позволяющий внедрить выражения формата XPath в вызовы SQL, хотя такой подход на данный момент пока не стандартизован. Крупные сериализованные объекты лучше всего применять для хранения относительно небольших групп объектов. Злоупотребление этим подходом приведет к тому, что база данных со временем будет напоминать файловую систему.
3.4.9.1.2 Наследование
Выше уже упоминались составные иерархические структуры, которые традиционно плохо отображаются средствами реляционных систем баз данных. Существует и другая разновидность иерархий, еще более усугубляющих страдания приверженцев реляционной модели: речь идет об иерархиях классов, создаваемых на основе механизма наследования (inheritance). Поскольку SQL не предоставляет стандартизованных инструментов поддержки наследования, придется вновь прибегнуть к аппарату отображения.
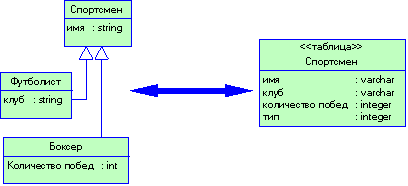
Рисунок 3.17 Паттерн Наследование с одной таблицей предусматривает сохранение значений атрибутов всех классов иерархии в одной таблице
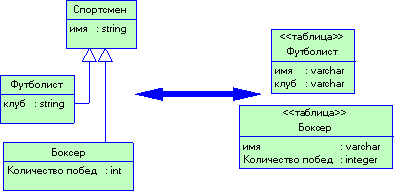
Рисунок 3.18 Паттерн Наследование таблиц для каждого конкретного класса предусматривает использование отдельных таблиц для каждого конкретного класса иерархии
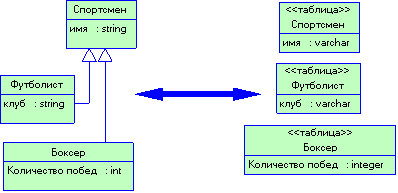
Рисунок 3.19 Паттерн Наследование таблиц для каждого класса предусматривает использование отдельных таблиц для каждого класса иерархии
Существует три основных варианта представления структуры наследования: "одна таблица для всех классов иерархии" (наследование с одной таблицей (Single Table Inheritance) - рис. 3.18; "таблица для каждого конкретного класса" (наследование с таблицами для каждого конкретного класса (Concrete Table Inheritance) - рис. 3.19; "таблица для каждого класса" (наследование с таблицами для каждого класса (Class Table Inheritance) - рис. 3.20.
Возможен компромисс между необходимостью дублирования элементов данных и потребностью в ускорении доступа к ним. Решение наследование с таблицами для каждого класса - самый простой и прямолинейный вариант соответствия между классами и таблицами базы данных, но для загрузки информации об отдельном объекте в этом случае приходится осуществлять несколько операций соединения (join), что обычно сопряжено со снижением производительности системы. Решение наследование с таблицами для каждого конкретного класса позволяет обойти соединения, предоставляя возможность считывания всех данных об объекте из единственной таблицы, но существенно препятствует внесению изменений. При любой модификации базового класса нельзя забывать о необходимости соответствующего преобразования всех таблиц дочерних классов (и кода, обеспечивающего корректное отображение). Изменение самой иерархической структуры способно вызвать еще более серьезные проблемы. Помимо того, отсутствие таблицы для базового класса может усложнить управление ключами. Что касается наследования с одной таблицей, то самым большим недостатком этого решения является нерациональное расходование дискового пространства, поскольку каждая запись таблицы содержит поля для атрибутов всех созданных дочерних классов и многие из этих полей остаются пустыми. (Впрочем, некоторые СУБД "умеют" осуществлять сжатие неиспользуемых областей.) Большой размер записи приводит и к замедлению ее загрузки. Преимущество же наследования с одной таблицей заключается в том, что все данные, относящиеся к любому классу, сосредоточены в одном месте, а это значительно упрощает возможность внесения изменений и позволяет избежать операций соединения. Три упомянутых решения не являются взаимоисключающими - их вполне можно сочетать в рамках одной и той же иерархии классов: например, информацию о наиболее важных классах уместно объединить посредством наследования с одной таблицей, а для других классов воспользоваться решением наследование с таблицами для каждого класса. Разумеется, совмещение решений повышает сложность их применения.
Среди названных способов отображения иерархии наследования трудно выделить какой-либо один. Как и при использовании всех других типовых решений, необходимо принять во внимание конкретные обстоятельства и требования.
3.4.9.1.3 Реализация отображения
Отображение объектов в реляционные структуры, по существу, сводится к одной из трех общих ситуаций:
- готовой схемы базы данных нет, и ее можно выбирать;
- приходится работать с существующей схемой, которую не разрешается изменять;
- схема задана, но возможность ее модификации оговаривается дополнительно.
В простейшем случае, когда схема создается самостоятельно, а бизнес-логика отличается умеренной сложностью, оправдан подход, основанный на сценарии транзакции (Transaction Script) или модуле таблицы (Table Module); таблицы могут создаваться с помощью традиционных инструментов проектирования баз данных. Для исключения кода SQL из бизнес-логики применяется шлюз записи данных (Row Data Gateway,) или шлюз таблицы данных (Table Data Gateway). Используя модель предметной области (Domain Model), остерегайтесь структурировать приложение с оглядкой на схему базы данных и больше заботьтесь об упрощении бизнес-логики. Воспринимайте базу данных только как инструмент сохранения содержимого объектов. Наибольший уровень гибкости взаимного отображения объектов и реляционных структур обеспечивает преобразователь данных (Data Mapper), но это типовое решение отличается повышенной сложностью. Если структура базы данных изоморфна модели предметной области, можно воспользоваться активной записью (Active Record).
Хотя первоочередное построение модели представляет собой удобный способ восприятия предметной области, этот вариант действий правомерен только тогда, когда он реализуется в течение короткого итеративного цикла. Провести шесть месяцев за построением модели предметной области, не предусматривающей применения базы данных, а затем в один момент прийти к заключению о том, что сохранять кое-какую информацию все-таки было бы неплохо, не только несерьезно, но и весьма рискованно. Опасность заключается в том, что, если проект продемонстрирует изъяны на уровне производительности, исправить положение будет непросто. Каждую полуторамесячную или даже более краткую итерацию разработки модели и приложения следует сопровождать принятием решений, касающихся уточнения и расширения схемы базы данных. В этом случае у вас всегда будет самая свежая информация о том, как интерфейс взаимодействия приложения с базой данных ведет себя на практике. Итак, решая любую частную задачу, в первую очередь необходимо думать о модели предметной области, не забывая немедленно интегрировать каждую ее часть в базу данных.
Если схема базы данных создана загодя, в вашем распоряжении примерно те же альтернативы, но процесс несколько отличается. Если бизнес-логика проста, ее слой располагается "поверх" создаваемых классов шлюза записи данных или шлюза таблицы данных, имитирующих функции базы данных. При повышении уровня сложности бизнес-логики приходится прибегать к помощи модели предметной области, дополненной преобразователем данных, который должен обеспечить сохранение содержимого объектов приложения в существующей базе данных.
3.4.9.1.4 Использование метаданных
Наличие в тексте приложения повторяющихся фрагментов кода - признак его плохо продуманной структуры. Общие функции можно вынести "за скобки", например средствами наследования и делегирования - одними из главных механизмов объектно-ориентированного программирования, но существует и более изощренный подход, связанный с отображением метаданных (Metadata Mapping).
Типовое решение отображение метаданных основано на вынесении функций отображения в файл метаданных, задающий соответствие между столбцами таблиц базы данных и полями объектов. Наличие метаданных позволяет не повторять код отображения и заново генерировать его по мере необходимости. Даже пустяковый фрагмент метаданных, подобный приведенному ниже, способен весьма выразительно сообщить большой объем информации.
<class name = ‘Person’ tableName = ‘Person’>
<attr name=’id’ field=’person_id’>
<attr name=’lastName’ field=’last_name>
</class>
С помощью этой информации вам удастся определить операции считывания и записи данных, автоматического формирования любых SQL-выражений, поддержки множественных связей и т.п. Вот почему модель метаданных находит широкое применение в коммерческих инструментальных средствах отображения объектов и реляционных структур.
Отображение метаданных предлагает все необходимое для конструирования запросов в терминах прикладных объектов. Типовое решение объект запроса (Query Object) позволяет создавать запросы на основе объектов и данных в памяти, не требуя знаний SQL и деталей реляционной схемы, и применять инструменты отображения метаданных для трансляции таких выражений в соответствующие конструкции SQL.
Воспользуйтесь этими решениями на наиболее ранних стадиях проекта, и вам удастся применить одну из форм хранилища (Repository,), полностью скрывающего базу данных от взгляда извне. Любые запросы к базе данных могут трактоваться как объекты запроса в контексте хранилища: в этой ситуации разработчику приложения неведомо, откуда извлекаются объекты - из памяти или из базы данных. Решение хранилище весьма удачно сочетается с богатыми моделями предметной области (Domain Model).
3.4.10 Соединение с базой данных
В большинстве случаев приложение взаимодействует с базой данных при посредничестве некоторого объекта соединения (connection). Прежде чем выполнять команды и запросы к базе данных, соединение обычно необходимо открыть. Объект соединения должен пребывать в открытом состоянии на протяжении всего сеанса работы с базой данных. По завершении обслуживания запроса возвращается объект типа множество записей (Record Set). Некоторые интерфейсы позволяют манипулировать полученным множеством записей даже после закрытия соединения, а некоторые требуют наличия активного соединения. Если действия выполняются в рамках транзакции, последняя, как правило, ограничена контекстом определенного соединения, которое должно оставаться открытым, как минимум, до завершения транзакции.
Во многих средах открытие выделенного соединения сопряжено с расходованием строго ограниченных ресурсов, поэтому применение находят так называемые пулы соединений (connection pools). В этом случае приложение не открывает и закрывает соединение, а запрашивает его из пула и освобождает, когда оно больше не требуется. Сегодня поддержка пула соединений обеспечивается большинством вычислительных платформ, поэтому потребность в самостоятельной реализации подобной структуры возникает редко. Если все-таки вам приходится этим заниматься, прежде всего выясните, действительно ли применение пула повышает производительность системы. Нередко среда способна обеспечить более быстрое создание нового соединения, нежели повторное использование соединения из пула.
Платформы, поддерживающие механизм пула соединений, часто скрывают последний посредством дополнительных интерфейсов, так что операции создания нового объекта соединения и выделения объекта из пула для разработчика прикладной системы выглядят совершенно идентично. Аналогично, закрытие соединения в реальности может означать возврат соединения в общий пул, доступный для других процессов. Подобная инкапсуляция, безусловно, является положительным решением. Ниже будут употребляться термины "открытие" и "закрытие", но имейте в виду, что в конкретной ситуации они могут означать соответственно "захват" соединения из пула и его "освобождение" с возвращением в пул.
Неважно, как создаются соединения, но ими необходимо надлежащим образом управлять. Поскольку, как уже отмечалось, речь в данном случае идет о дорогостоящих вычислительных ресурсах, соединения следует закрывать сразу по завершении их использования. Помимо того, если применяется аппарат транзакций, необходимо гарантировать, что каждая команда внутри определенной транзакции активизируется при посредничестве одного и того же объекта соединения. Наиболее общая рекомендация такова: следует запросить объект соединения явно, используя вызов, обращенный к пулу или диспетчеру соединений, а затем ссылаться на этот объект в каждой команде, адресуемой к базе данных; по окончании использования объект необходимо закрыть. Но как поручиться, что ссылки на объект соединения присутствуют везде, где необходимо, и не забыть закрыть соединение по окончании работы.
Решение первой части проблемы состоит в передаче объекта соединения в любую команду в виде явно задаваемого параметра. К сожалению, при этом может оказаться, что объект соединения не будет передан единственному методу, расположенному в стеке вызовов на несколько уровней ниже, а присутствует во всевозможных вызовах методов. В этой ситуации целесообразно вспомнить о реестре (Registry). Поскольку вам наверняка не хочется, чтобы соединением пользовались несколько вычислительных потоков, необходимо применять вариант реестра уровня одного потока.
Даже если вы не так забывчивы, как я, то и в этом случае согласитесь, что требование
явного закрытия соединений довольно обременительно, поскольку его слишком легко оставить без внимания, что, разумеется, недопустимо. Соединение нельзя закрывать и после выполнения каждой команды, так как первая же попытка сделать подобное внутри транзакции приведет к ее откату.
Оперативная память, как и соединения, относится к числу ресурсов, которые надлежит возвращать системе сразу по завершении их использования. В современных средах разработки управление памятью и функции сборки мусора осуществляются автоматически. Поэтому один из способов закрытия соединения состоит в том, чтобы довериться сборщику мусора. При таком подходе соединение закрывается, если в ходе сборки мусора утилизируются объект соединения как таковой и все объекты, которые на него ссылаются. Удобно то, что здесь применяется та же хорошо знакомая схема управления памятью. Однако есть и проблема: соединение закрывается только тогда, когда сборщик мусора действительно утилизирует память, а это может произойти гораздо позже, чем исчезнет последняя ссылка, адресующая объект соединения, т.е. в ожидании закрытия он проведет немало времени. Возникнет подобная проблема или нет, во многом определяется особенностями среды разработки, которой вы пользуетесь.
Если рассуждать в более широком смысле, я не стал бы слишком полагаться на механизм сборки мусора. Другие схемы - даже с принудительным закрытием соединений - кажутся более надежными. Впрочем, сборку мусора можно считать своего рода страхвочным вариантом: как говорится, лучше позже, чем никогда.
Поскольку соединения логически тяготеют к транзакциям, удобная стратегия управления ими состоит в трактовке соединения как неотъемлемого "атрибута" транзакции: оно открывается в начале транзакции и закрывается по завершении операций фиксации или отката. Транзакции известно, с каким соединением она взаимодействует, и потому вы можете сосредоточиться на транзакции, более не заботясь о соединении как таковом. Поскольку завершение транзакции обычно имеет более "видимый" эффект, чем завершение соединения, вы вряд ли забудете ее зафиксировать (а если и забудете, то, поверьте мне, быстро об этом вспомните). Один из вариантов совместного управления транзакциями и соединениями демонстрируется в типовом решении единица работы (Unit Of Work).
Если речь идет о выполнении операций вне транзакций (например, о чтении заведомо неизменяемых данных), для каждой операции можно использовать "свежий" объект соединения. Совладать с любыми проблемами, касающимися использования объектов соединений с короткими периодами существования, поможет схема организации пула соединений.
При необходимости обработки данных в автономном режиме в контексте множества записей можно открыть соединение для загрузки информации в структуру данных, закрыть его и приступить к обработке. По завершении следует открыть новое соединение, активизировать транзакцию и сохранить результаты в базе данных. Если действовать по такой схеме, придется позаботиться о синхронизации данных с той информацией, которая изменялась другими транзакциями в период обработки содержимого множества записей.
Особенности процедур управления соединениями во многом обусловлены параметрами конкретных среды разработки и приложения
3.5 Паттерны представления данных в WEB
Одно из самых впечатляющих изменений, происшедших с корпоративными приложениями за последние несколько лет, связано с появлением пользовательских интерфейсовв стиле Web-обозревателей. Они принесли с собой ряд преимуществ: исключили потребность в применении специального клиентского программного слоя, обобщили и унифицировали процедуры доступа и упростили проблему конструирования Web-приложений.
Функции Web-сервера состоят в интерпретации адреса URL запроса и передаче управления соответствующей программе (вариант, когда WEB-сервер считывает с диска и отправляет клиету обычный файл не рассматривается). Существует две основные формы представления программы Web-сервера - сценарий (script) и страница сервера (serverpage).
Сценарий состоит из функций или методов, предназначенных для обработки запросов HTTP. Типичными примерами могут служить сценарии CGI и сервлеты Java. Подобная программа способна выполнять практически все то же, что и традиционное приложение.
Сценарий часто разбивается на подпрогаммы и пользуется сторонними службами. Он получает данные с Web-страницы, проверяя строковый объект HTTP-запроса и вычленяя из него регулярные выражения; простота реализации подобных функций с помощью языка Perl снискали последнему славу одного из наиболее адекватных средств разработки сценариев CGI. В иных случаях, например при использовании сервлетов Java, прогрраммист получает доступ к информации запроса через интерфейс ключевых слов, что нередко значительно удобнее. Результатом работы Web-сервера служит другая - ответная - строка, образуемая сценарием с привлечением обычных функций поточного вывода.
Задача формирования кода HTML посредством команд поточного вывода не очень привлекательна для программистов, а непрограммистам она вообще не по силам, хотя они с удовольствием взялись бы за Web-дизайн с помощью других инструментов. Это естественным образом подводит к модели страниц сервера, где функции программы сводятся к возврату порции текстовых данных. Страница содержит текст HTML с "вкраплениями" исполняемого кода. Подобный подход, реализуемый, например, в PHP, ASP и JSP, особенно удобен, если требуется незначительная дополнительная обработка текста с учетом реакции пользователя.
Поскольку модель сценариев лучше подходит для интерпретации запросов, а схема страниц сервера - для форматирования ответов, вполне разумно применять их совместно. На самом деле это довольно старая идея, впервые реализованная в пользовательских интерфейсах на основе паттерна модель-представление-контроллер.
Решение находит широкое применение, но зачастую трактуется неверно (это особенно характерно для приложений, написанных до появления Web). Основная причина состоит в неоднозначном толковании термина "контроллер". Он употребляется во многих контекстах, и ему придается самый разный смысл, иногда совершенно противоречащий тому, который заключен в решении MVC. Вот почему, говоря об этом решении, предпочитают использовать словосочетание входной контроллер (input controller).
Входной контроллер принимает запрос и извлекает из него информацию. Затем он передает бизнес-логику надлежащему объекту модели, который обращается к источнику данных и выполняет действия, предусмотренные в запросе, включая сбор информации, необходимой для ответа. По завершении функций он передает управление входному контроллеру, который, анализируя полученный результат, принимает решение о выборе варианта представления ответа. Управление и соответствующие данные передаются представлению. Взаимодействие входного контроллера представления зачастую осуществляется не в виде прямых вызовов, а при посредничестве некоторого объекта HTTP-сеанса, который служит для передачи данных в обоих направлениях.
Основной довод в пользу применения решения модель-представление-контроллер состоит в том, что оно предусматривает полное отмежевание модели от Web-представления. Это упрощает возможности модификации существующих и добавления новых представлений. А размещение логики в отдельных объектах сценария транзакции (Transaction Script) и модели предметной области (Domain Model) облегчает их тестирование. Это особенно важно, когда в качестве представления используется страница сервера. Здесь наступает черед практического применения второго варианта толкования термина "контроллер". Во многи версиях пользовательского интерфейса объекты представленияотделяются от объектов домена промежуточным слоем объектов контроллера приложения (Application Controller), назначением которого является управление потоком функций приложения и выбор порядка демонстрации интерфейсных экранов. Контроллер приложения выглядит как часть слоя представления либо как самостоятельная "прослойка" между уровнями представления и предметной области. Контроллеры приложения могут быть реализованы независимо от какого бы то ни было частного представления, и тогда их удается использовать повторно для различных представлений.
Контроллеры приложения нужны далеко не всем системам. Они удобны, когда приложение отличается богатством логики, касающейся порядка воспроизведения экранов интерфейса и навигации между ними, либо отсутствием простой зависимости между страницами и сущностям предметной области. Когда же порядок следования страниц несуществен, необходимости в использовании контроллеров приложения практически не возникает. Вот простой тест, позволяющий определить, целесообразно ли применять контроллеры приложения: если потоком функций системы управляет машина, ответ положителен, а если пользователь - отрицателен.
3.5.1 Паттерн Model-View-Controller
Паттерн распределяет обработку взаимодействия с пользовательским интерфейсом между тремя участниками
Типовое решение модель-представление-контроллер - одно из наиболее часто цитируемых (и, к сожалению, неверно истолковываемых). Первоначально оно появилось в виде инфраструктуры, разработанной Тригве Реенскаугом (Trigve Reenskaug) для платформы Smalltalk в конце 70-х годов прошлого столетия. С тех пор оно сыграло значительную роль в разработке множества инфраструктур и легло в основу целого ряда концепций проектирования пользовательского интерфейса.
Принцип действия
Типовое решение модель-представление-контроллер подразумевает выделение трех отдельных ролей. Модель - это объект, предоставляющий некотору информацию о домене. У модели нет визуального интерфейса, она содержит в себе все данные и поведение, не связанные с пользовательским интерфейсом. В объектно-ориентированном кон-тексте наиболее "чистой" формой модели является объект модели предметной области (Domain Model). В качествемодели можно рассматривать и сценарий транзакции (Transaction Script), если он не содержит в себе никакой логики, связанной с пользовательским интерфейсом. Подобное определение не очень расширяет понятие модели, однако полностью соответствует распределению ролей в рассматриваемом типовом решении.
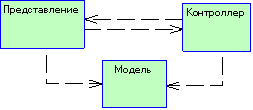
Рисунок 3.20 Структура паттерна MVC
Представление отображает содержимое модели средствами графического интерфейса. Таким образом, если наша модель - это объект покупателя, соответствующее представление может быть фреймом с кучей элементов управления или HTML-страницей, заполненной информацией о покупателе. Функции представления заключаются только в отображении информации на экране. Все изменения информации обрабатываются третьим "участником" нашей системы - контроллером. Контроллер получает входные данные от пользователя, выполняет операции над моделью и указывает представлению на необходимость соответствующего обновления. В этом плане графический интерфейс можно рассматривать как совокупность представления и контроллера.
Говоря о типовом решении MVC, нельзя не подчеркнуть два принципиальных типа разделения: отделение представления от модели и отделение контроллера от представления.
Отделение представления от модели - это один из фундаментальных принципов проектирования программного обеспечения. Наличие подобного разделения весьма важно по ряду причин.
- Представление и модель относятся к совершенно разным сферам программирова ния. Разрабатывая представление, вы думаете о механизмах пользовательского интерфейса и о том, как сделать интерфейс приложения максимально удобным для пользователя. В свою очередь, при работе с моделью ваше внимание сосредоточе но на бизнес-политиках и, возможно, на взаимодействии с базой данных. Очевидно, при разработке модели и представления применяются разные (совершенно разные!) библиотеки. Кроме того, большинство разработчиков специализируются только в одной из этих областей.
- Пользователи хотят, чтобы, в зависимости от ситуации, одна и та же информация могла быть отображена разными способами. Отделение представления от модели позволяет разработать для одного и того же кода модели несколько представлений, а точнее, несколько абсолютно разных интерфейсов. Наиболее наглядно данный подход проявляется в том случае, когда одна и та же модель может быть представлена с помощью толстого клиента, Web-обозревателя, удаленного API или интер фейса командной строки. Даже в пределах одного и того же Web-интерфейса в разных местах приложения одному и тому же покупателю могут соответствовать разные страницы.
- Объекты, не имеющие визуального интерфейса, гораздо легче тестировать, чем объекты с интерфейсом. Отделение представления от модели позволяет легко протестировать всю логику домена, не прибегая к таким "ужасным" вещам, как средства написания сценариев для поддержки графического интерфейса пользователя.
Ключевым моментом в отделении представления от модели является направление зависимостей: представление зависит от модели, но модель не зависит от представления. Программисты, занимающиеся разработкой модели, вообще не должны быть осведомлены о том, какое представление будет использоваться. Это существенно облегчает разра-ботку модели и одновременно упрощает последующее добавление новых представлений.
Кроме того, это означает, что изменение представления не требует изменения модели. Данный принцип тесно связан с распространенной проблемой. При использовании толстого клиента с множеством диалоговых окон на экране могут одновременно находиться несколько представлений одной и той же модели. Если пользователь внесет изменения в модель посредством одного представления, эти изменения должны быть отражены и во всех остальных представлениях. Чтобы это было возможным при отсутствии двунаправленной зависимости, необходимо реализовать типовое решение наблюдатель (Observer). В этом случае представление будет выполнять роль "наблюдателя" за моделью: как только модель будет изменена, представление генерирует соответствующее событие и все остальные представления обновляют свое содержимое.
Отделение контроллера от представления не играет такой важной роли, как предыдущий тип разделения. Дествительно, по иронии судьбы практически вовсех версиях Smalltalk разделение на контроллер и представление не проводилось. Классическим примером необходимости подобного разделения является поддержка редактируемого и нередактируемого поведения. Этого можно достичь при наличии одного представления и двух контроллеров (для двух вариантов использования), где контроллеры являются стратегиями, используемыми представлением. Между тем на практике в большинстве систем каждому представлению соответствует только один контроллер, поэтому разделение между ними непроводится.
О данном решении вспомнили только при появлении Web-интерфейсов, где отделение контроллера от представления оказалось чрезвычайно полезным. Тот факт, что в большинстве инфраструктур пользовательских интерфейсов не проводилось разделение на представление и контроллер, привел к множеству неверных толкований паттерна MVC. Да, наличие модели и представления очевидно, но где же контроллер? Многие решили, что контроллер находится между моделью и представлением, как в контроллере приложения (Application Controller). Данное заблуждение еще более усугубил тот факт, что в обоих названиях фигурирует слово "контроллер". Между тем, несмотря на все полож тельные качестваконтроллера приложения, он ничем не похож на контроллер MVC.
Назначение
Как уже отмечалось, MVC заключается в наличии двух типов разделения. Отделение представления от модели - один из основополагающих принципов, на котором держится все проектирование программного обеспечения, и пренебрегать им можно только тогда, когда речь идет о совсем простых системах, в которых модель вообще не имеет какого-либо реального поведения. Как только в приложении появляется невизуализированная логика, разделение становится крайне необходимым. К сожалению, во многих инфраструктурах пользовательских интерфейсов реализовать подобное разделение довольно сложно, а там, где это несложно, о нем все равно забывают.
Отделение представления от контроллера не так важно, поэтому рекомендую проводить его только в том случае, когда оно действительно нужно. Подобная необходимость практически не возникает в системах с толстыми клиентами, а вот в Web-интерфейсах отделение контроллера весьма полезно. Большинство рассматриваемых здесь типовыхрешений, предназначенных для проектирования Web-приложений, основаны именно на этом принципе.
3.5.2 Паттерн Page Controller
Контроллер страниц (Page Controller). Объект, который обрабатывает запрос к конкретной Web-странице или выполнение конкретного действия на Web-сайте.
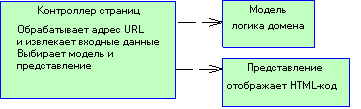
Рисунок 3.21. Структура паттерна Page Controller
Большинство пользователей Internet когда-либо сталкивались со статическими HTML-страницами. Когда посетитель сайта запрашивает статическую страницу, он передает Web-серверу имя и путь к HTML-документу, который хранится на этом сервере. Ключевым моментом здесь является то, что каждая страница Web-сайта представлена на сервере отдельным документом. С динамическими страницами дело обстоит далеко не так просто из-за более сложных отношений между именами путей и соответствующими файлами. Несмотря на это, простая модель, при которой одному пути соответствует один документ, обрабатывающий запрос, может быть применена и здесь.
Типовое решение контроллер страниц предполагает наличие отдельного контроллера для каждой логической страницы Web-сайта. Этим контроллером может быть сама страница (как часто бывает в окружениях страниц сервера) или отдельный объект, соответствующий данной странице.
Принцип действия
В основе контроллера страниц лежит идея создания компонентов, которые будут выполнять роль контроллеров для каждой страницы Web-сайта. На практике количество контроллеров не всегда в точности соответствует количеству страниц, поскольку иногда при щелчке на ссылке открываются страницы с разным динамическим содержимым. Если говорить более точно, контроллер необходим для каждого действия, под которым подразумевается щелчок на кнопке или гиперссылке.
Контроллер страниц может быть реализован в виде сценария (сценария CGI, сервлета и т.п.) или страницы сервера (ASP, PHP, JSP и т.п.). Использование страницы сервера обычно предполагает сочетание в одном файле контроллера страниц и представления по шаблону (Template View). Это хорошо для представления по шаблону, но не очень подходит для контроллера страниц, поскольку значительно затрудняет правильное структурирование этого компонента. Данная проблема не столь важна, если страница применяется только для простого отображения информации. Тем не менее, если использование страницы предполагает наличие логики, связанной с извлечением пользовательских данных или выбором представления для отображения результатов, страница сервера может заполниться кошмарным кодом "скриптлета", т.е. внедренного сценария. Чтобы избежать подобных проблем, можно воспользоваться вспомогательным объектом (helper object). При получении запроса страница сервера вызывает вспомогательный объект для обработки всей имеющейся логики. В зависимости от ситуации, вспомогательный объект может вернуть управление первоначальной странице сервера или же обратиться к другой странице сервера, чтобы она выступила в качестве представления. В этом случае обработчиком запросов является страница сервера, однако большая часть логики контроллера заключена во вспомогательном объекте.
Возможной альтернативой описанному подходу является реализация обработчика и контроллера в виде сценария. В этом случае при поступлении запроса Web-сервер передает управление сценарию; сценарий выполняет все действия, возложенные на контроллер, после чего отображает полученные результаты с помощью нужного представления.
Ниже перечислены основные обязанности контроллера страниц.
- Проанализировать адрес URL и извлечь данные, введенные пользователем в соответствующие формы, чтобы собрать все сведения, необходимые для выполнения действия.
- Создать объекты модели и вызвать их методы, необходимые для обработки данных. Все нужные данные из HTTP-запроса должны быть переданы модели, чтобы ее объекты были полностью независимы от этого запроса.
- Определить представление, которое должно быть использовано для отображения результатов, и передать ему необходимую информацию, полученную от модели.
Контроллер страниц не обязательно должен представлять собой единственный класс, зато все классы контроллеров могут использовать одни и те же вспомогательные объекты. Это особенно удобно, если на Web-сервере должно быть несколько обработчиков, выполняющих аналогичные задания. В этом случае использование вспомогательного объекта позволяет избежать дублирования кода.
При необходимости одни адреса URL можно обрабатывать с помощью страниц сервера, а другие - с помощью сценариев. Те адреса URL, у которых нет или почти нет логики контроллера, хорошо обрабатывать с помощью страниц сервера, потому что последние представляют собой простой механизм, удобный для понимания и внесения изменений. Все остальные адреса, для обработки которых необходима более сложная логика, требуют применения сценариев.
Назначение
Выбирая способ обработки запросов к Web-сайту, необходимо решить, какой контроллер следует использовать контроллер страниц или контроллер запросов (Front Controller). Контроллер страниц более прост в работе и представляет собой естественный механизм структуризации, при котором конкретные действия обрабатываются соответствующими страницами сервера или классами сценариев. Контроллер запросов гораздо сложнее, однако имеет массу разнообразных преимуществ, многие из которых крайне важны для Web-сайтов со сложной системой навигации.
Контроллер страниц хорошо применять для сайтов с достаточно простой логикой контроллера. В этом случае большинство адресов URL могут обрабатываться с помощью
страниц сервера, а более сложные случаи — с применением вспомогательных объектов.
Если логика контроллера довольно проста, использование контроллера запросов приведет к ненужным расходам. Нередки ситуации, когда одни запросы к Web-сайту обрабатываются с помощью контроллеров страниц, а другие с помощью контроллеров запросов, особенно когда разработчики выполняют рефакторинг элементов из одного контроллера в другой. В действительности эти типовые решения хорошо сочетаются между собой.
3.5.3 Паттерн Front Controller
Контроллер запросов (Front Controller). Контроллер, который обрабатывает все запросы к Web-серверу.
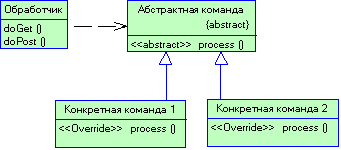
Рисунок 3.22 Структура паттерна Front Controller
Обработка запросов к Web-сайтам со сложной структурой подразумевает выполнение большого количества аналогичных действий. Это проверка безопасности, обеспечение поддержки интернационализации и открытие специальных представлений для особых категорий пользователей. Если поведение входного контроллера будет разбросано по нескольким объектам, это приведет к дублированию большей части кода. Кроме того, это значительно затруднит изменение поведения контроллера во время выполнения.
Типовое решение контроллер запросов объединяет все действия по обработке запросов в одном месте, распределяя их выполнение посредством единственного объекта обработчика. Как правило, этот объект реализует общее поведение, которое может быть изменено во время выполнения с помощью декораторов. Для выполнения конкретного запроса обработчик вызывает соответствующий объект команды.
Принцип действия
Контроллер запросов обрабатывает все запросы, поступающие к Web-сайту, и обычно состоит из двух частей: Web-обработчика и иерархии команд. Web-обработчик - это объект, который выполняет фактическое получение POST или GET запросов, поступивших на Web-сервер. Он извлекает необходимую информацию из адреса URL и входных данных запроса, после чего решает, какое действие необходимо инициировать, и делегирует его выполнение соответствующей команде (рис. 3.23).
Web-обработчик обычно реализуется в виде класса, а не страницы сервера, поскольку он не генерирует никаких откликов. Команды также являются классами, а не страница-ми сервера; более того, им не нужно знать о наличии Web-окружения, несмотря на то что им часто передается информация из HTTP-запросов. В большинстве случаев Web-обработчик - это довольно простая программа, функции которой заключаются в выборе нужной команды.
Выбор команды может происходить статически или динамически. Статический выбор команды подразумевает проведение синтаксического анализа адреса URL и применение условной логики, а динамический - извлечение некоторого стандартного фрагмента адреса URL и динамическое создание экземпляра класса команды.
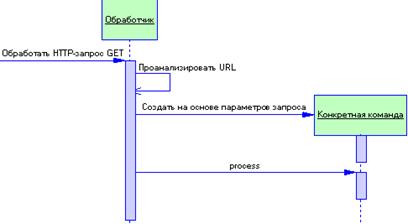
Рисунок 3.23 Принцип работы контроллера запросов
Преимущества статического выбора команды состоят в использовании явного кода, наличии проверки времени компиляции и высокой гибкости возможных вариантов написания адресов URL. В свою очередь, использование динамического подхода позволяет добавлять новые команды, не требуя изменения Web-обработчика.
При динамическом выборе команд имя класса команды можно поместить непосредственно в адрес URL либо воспользоваться файлом свойств, который будет привязывать адреса URL к именам классов команд. Разумеется, это потребует создания дополнительного файла свойств, однако позволит легко и непринужденно изменять имена классов, не просматривая все имеющиеся на сервере Web-страницы.
Назначение
Контроллер запросов имеет более сложную структуру, чем его очевидный соперник - контроллер страниц Чтобы быть удостоенным внимания разработчиков, контроллер запросов должен иметь хотя бы несколько преимуществ, и они у него, разумеется, есть.
Во-первых, Web-сервер должен быть настроен на использование только одного контроллера запросов; всю остальную работу по распределению запросов будет выполнять Web-обработчик. Это значительно облегчит конфигурирование Web-сервера . Использование динамического выбора команд позволяет добавлять новые команды без каких-либо изменений. Кроме того, динамические команды облегчают переносимость, так как от вас требуется лишь зарегистрировать обработчик в настройках сервера. Поскольку для выполнения каждого запроса создаются новые экземпляры классов команд, вам не придется беспокоиться о том, чтобы они функционировали в отдельных потоках. Это позволит избежать всех неприятностей, связанных с многопоточным программированием; тем не менее вам придется следить за отсутствием совместного использования других объектов, таких, как объекты модели.
Наиболее часто упоминаемым преимуществом контроллера запросов является возможность реализации общего кода, который так или иначе дублируется в многочисленных контроллерах страниц. Тем не менее многие забывают, что общее поведение последних с не меньшим успехом может быть вынесено в суперкласс контроллеров страниц.
Контроллер запросов только один, что позволяет легко изменять его поведение во время выполнения с помощью многочисленных декораторов. Декораторы могут применяться для проведения аутентификации, выбора кодировки, обеспечения поддержки интернационализации и т.п. Более того, их можно добавлять не только с помощью файла настроек, но и прямо во время работы сервера
3.5.4 Паттерн Template View
Представление по шаблону (Template View). Преобразует результаты выполнения запроса в формат HTML путем внедрения маркеров в HTML-страницу.
Написать программу, генерирующую код HTML, гораздо сложнее, чем может показаться на первый взгляд. Хотя современные языки программирования справляютсяс созданием текста гораздо лучше, чем в былые времена, создание и конкатенация строковых конструкций все еще связаны с массой неудобств. Данная проблема не так страшна, если текста не слишком много, однако создание целой HTML-страницы может потребовать множества "изуверских" манипуляций над текстом.
Для редактирования статических HTML-страниц (тех, содержимое которых не изменяется от запроса к запросу) можно использовать замечательные текстовые редакторы, работающие по принципу WYSIWYG (What You See Is What You Get — что видишь на экране, то и получишь при печати). Даже тем, кто предпочитает самые примитивные редакторы, набирать текст и дескрипторы намного приятнее, чем заниматься конкатенацией строк в коде программы.
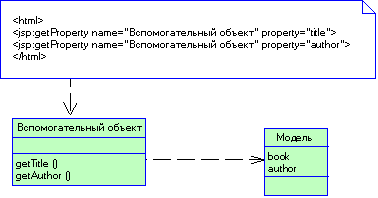
Рисунок 3.24 Структура паттерна Template View
Основные трудности связаны с созданием динамических Web-страниц — тех, которые принимают результаты выполнения какого-нибудь запроса (например, к базе данных) и внедряют их в код HTML. Содержимое такой страницы меняется с каждым запросом, а потому обыкновенные редакторы HTML здесь бессильны.
Наиболее удобный способ создания динамической Web-страницы - конструирование обычной статической страницы и последующая вставка в нее специальных маркеров, которые могут быть преобразованы в вызовы функций, предоставляющих динамическую информацию. Поскольку статическаячасть страницы выступает в роли своеобразного шаблона, типовое решение и называется представлением по шаблону.
Принцип действия
Основная идея, лежащая в основе типового решения представление по шаблону, - вставка маркеров в текст готовой статической HTML-страницы. При вызове страницы для обслуживания запроса эти маркеры будут заменены результатами некоторых вычислений (например, результатами ыполнения запросов к базе данных). Подобная схема позволяет создавать статическую часть страницы с помощью обычных средств, например текстовых редакторов, работающих по принципу WYSIWYG, и не требует знания языков программирования. Для получения динамической информации маркеры обращаются к отдельным программам.
Представление по шаблону используется целым рядом программных средств. Таким образом, ваша задача состоит не столько в том, чтобы разработать данное решение самому, сколько в том, чтобы научиться его эффективно использовать и познакомиться с возможными альтернативами.
Вставка маркеров
Существует несколько способов внедрения маркеров в HTML-страницу. Один из них - это использование HTML-подобных дескрипторов. Данный способ хорошо подходит для редакторов, работающих по принципу WYSIWYG, поскольку они распознают элементы, заключенные в угловые скобки (<>), как специальное содержимое и поэтому игнорируют их либо обращаются с ними иначе, чем с обычным текстом. Если дескрипторы удовлетворяют правилам форматирования языка XML, для работы с полученным документом можно использовать средства XML (разумеется, при условии, что результирующий документ HTML является документом XHTML).
Еще один способ внедрения динамического содержимого - вставка специальных текстовых маркеров в тело страницы. В этом случае текстовые редакторы WYSIWYG будут воспринимать вставленные маркер как обычный текст. Разумеется, содержимое маркеров от этого не изменится, однако может быть подвергнуто разнообразным назойливым операциям, например проверке орфографии. Тем не менее данный способ позволяет обойтись без запутанного синтаксиса HTML/XML.
Некоторые среды разработки содержат наборы готовых маркеров, однако все больше и больше платформ позволяют разработчику определять собственные дескрипторы и маркеры в соответствии с нуждами конкретных приложений.
Одной из наиболее популярных форм представления по шаблону является страница сервера (serverpage) - ASP, JSP или PHP. Вообще говоря, страницы сервера - это нечто большее, чем представление по шаблону, поскольку они позволяют внедрять в страницу элементы программной логики, называемые скриптлетами (scriptlets). Однако, скриплеты в трудно назвать удачным решением. Наиболее очевидный недостаток внедрения в страницу сервера множества скриптлетов состоит в том, что ее могут редактировать исключительно программисты. Данная проблема особенно критична, если проектированием страницы занимаются графические дизайнеры. Однако самые существенные недостатки скриптлетов связаны с тем, что страница - далеко не самый подходящий модуль для программы. Даже при использовании объектно-ориентированных языков программирования внедрение кода в текст страницы лишает вас возможности применять многие средства структурирования, необходимые для построения модулей как в объектно-ориентированном, так и в процедурном стиле.
Однако гораздо неприятнее то, что внедрение в страницу большого числа скриптлетов приводит к "перемешиванию" слоев корпоративного приложения. Если логика домена запускается прямо на страницах сервера, она практически не поддается структурированию и вместе с тем может легко привести к дублированию логики на других страницах сервера.
Вспомогательный объект
Чтобы избежать использования скриптлетов, каждой странице можно назначить собственный вспомогательный объект (helper object). Этот объект будет содержать в себе всю фактическую логику домена, а сама страница - только вызовы вспомогательного объекта, что значительно упростит структуру страницы и максимально приблизит ее к "чистой" форме представления по шаблону. Более того, это обеспечит возможность "разделения труда", при котором непрограммисты смогут спокойно заняться редактированием страницы, а программисты - сосредоточиться на разработке вспомогательного объекта. В зависимости от используемого средства, все "шаблонное" содержимое страницы зачастую можно свести к набору HTML/XML - дескрипторов, что повысит согласованность страницы и сделает ее более пригодной для поддержки стандартными средствами.
Описанная схема кажется простой и вполне заслуживающей доверия. Тем не менее, как всегда, здесь есть несколько но. Самые простые маркеры - это те, которые получают информацию из остальной части системы и помещают эту информацию в нужное место страницы. Подобные маркеры могут быть легко преобразованы в вызовы методов вспомогательного объекта, результатом выполнения которых является текст (или то, что может быть легко преобразовано в текст). Этот текст и помещается в указанное место страницы.
Условное отображение
Гораздо сложнее реализовать условное поведение страницы. Самый простой пример условного поведения - это когда результат выполнения запроса отображается только в том случае, если значением условного выражения является истина. Подобное поведение может быть реализовано с помощью условных дескрипторов наподобие
<IF condition = "$a>отобразить__что_нибудь</IF>.
К сожалению, иcпользование условных дескрипторов постепенно превращает шаблонные страницы в некое подобие языков программирования. Это чревато теми же проблемами, что и использование скриптлетов. Если вам нужен полноценный язык программирования, вы можете таким же успехом воспользоваться скриптлетами.
Из всего сказанного выше можно понять, что использование условных дескрипторов лучше избегать. Разумеется, это не всегда возможно, однако вы должны постараться придумать что-то более подходящее к потребностямконкретного приложения, чем универсальный дескриптор <IF>.
Если отображение текста должно выполняться при соблюдении определенных условий, их можно перенести во вспомогательный объект. В этом случае страница всегда будет отображать результаты выполнения методов вспомогательного объекта. Если условие не соблюдено, вспомогательный объект возвратит пустую строку. Этот подход хорошо применять тогда, когда возвращаемый текст не нуждается в разметке либо допускает возможность возвращения пустой разметки, которая будет проигнорирована обозревателем.
Иногда данный прием не срабатывает, например если вы хотите акцентировать внимание посетителей сайта на наиболее продаваемых товарах, выделив их названия полужирным шрифтом. В этом случае, помимо отображения названий товаров, может понадобиться специальная разметка текста. Одно из возможных решений этой проблемы - генерация разметки вспомогательным объектом. Это позволит очистить страницу от программной логики, однако создаст дополнительную нагрузку для программиста, которому придется принять на себя обязанности дизайнера, реализуя механизм выделения текста.
Чтобы управление HTML-разметкой осталось в руках дизайнера страниц, необходимо воспользоваться условными дескрипторами. В такой ситуации очень важно не опуститься до применения простого дескриптора <IF>. Удачным решением является применение дескрипторов, направленных на выполнение определенных действий. Например, вместо дескриптора
<IF expression = "isHighSelling()"><B></IF>
<property name = "price"/>
<IF expression = "isHighSelling () "></Bx/IF>
можно применить дескриптор
<highlight condition = "isHighSelling" style = "bold">
<property name = "price"/>
</highlight>
И в том и в другом случае очень важно, чтобы проверка условия выполнялась на основе единственного булева свойства вспомогательного объекта. Наличие на странице более сложных условных выражений будет означать перенесение логики на саму страницу. Еще одним примером условного поведения является отображение той или иной информации в зависимости от используемого в системе регионального стандарта. Предпо-ложим, что некоторый текст должен отображаться на экране только для пользователей из ША или Канады. В этом случае вместо универсального дескриптора
<IF expression= " locale='US'>текст >
рекомендуется использовать дескриптор вида
<locale includes = "US ">текст</locale>
Итерация
Похожие проблемы связаны с итерацией по коллекциям объектов. Если вы хотите отобразить таблицу, где каждая строка будет соответствовать пункту заказа, вам понадобится реализовать конструкцию, которая позволит легко отображать сведения по каждой строке. В данном примере практически невозможно избежать итерации по дескриптору коллекций, однако обычно она выполняется довольно легко.
Разумеется, набор доступных дескрипторов ограничивается используемой средой разработки. Некоторые среды разработки предоставляют фиксированный набор дескрипторов, которых может оказаться недостаточно для реализации описанных выше приемов. Тем не менее в большинстве сред разработки набор доступных дескрипторов более обширен, а некоторые платформы даже позволяют создавать собственные библиотеки дескрипторов.
Обработка страницы
Как следует из названия, главной функцией типового решения представление по шаблону является выполнение роли представления в системе MVC. В большинстве корпоративных систем представление по шаблону должно выступать исключительно в качестве представления. В более простых системах его можно использовать как контроллер, а возможно, и как модель. Если представление по шаблону выполняет еще какие-либо функции, помимо функций представления, необходимо тщательно следить за тем, чтобы реализацию этих функций обеспечивал вспомогательный объект, а не страница сервера. Выполнение обязанностей контроллера и модели подразумевает наличие программной логики, которая, как и всякая другая программная логика, должна находиться во вспомогательном объекте.
Система, связанная с применением шаблонов, требует дополнительной обработки Web-сервером. Эта обработка может выполняться посредством компиляции страницы сразу после ее создания, компиляции страницы при поступлении первого запроса или же интерпретации страницы при поступлении каждого запроса. Последний вариант, очевидно, является неудачным, особенно если обработка страницы занимает определенное время.
Работая с представлением по шаблону, следует обращать внимание на исключения. Если исключение срабатывает "по пути" к Web-контейнеру, оно может прервать обработку страницы и привести к появлению в окне обозревателя весьма странного содержимого. Понаблюдайте, как Web-сервер обрабатывает исключения. Если он делает что-то не то, рекомендую обрабатывать все исключения самому, перехватывая их во вспомогательном классе (еще одна причина, по которой следует избегать скриптлетов).
Использование сценариев
Хотя наиболее популярной формой представления по шаблону были и остаются страницы сервера, в случае необходимости их можно заменить сценариями. Главное при написании такого сценария - избежать конкатенации строк, используя вызовы функций, которые будут возвращать необходимые дескрипторы (это особенно хорошо демонстрируют сценарии CGI). Данный прием позволит создавать сценарий на привычном языке программирования, избегая досадных "вкраплений" в программную логику в виде функций вывода строк на экран.
Назначение
Основными альтернативами для реализации представления в MVC являются представление по шаблону и представление с преобразованием (Transform View,). Преимущество представления по шаблону состоит в том, что оно позволяет оформлять представление в соответствии со структурой страницы. Данная возможность весьма привлекательна для тех, кто не умеет программировать. В частности, она позволяет воплотить в жизнь идею, когда графический дизайнер занимается проектированием страницы, а программист работает над вспомогательным объектом.
Представление по шаблону имеет два существенных недостатка. Во-первых, реализуя представление в виде страницы сервера, последнюю весьма легко переполнить логикой. Это значительно усложнит ее дальнейшую поддержку, особенно для людей, не являющихся программистами. Необходимо тщательно следить за тем, чтобы страница оставалась простой и ориентированной только на отображение, а вся программная логика была реализована во вспомогательном объекте. Во-вторых, представление по шаблону сложнее тестировать, чем представление с преобразованием. Большинство реализаций представления по шаблону ориентированы на использование в рамках Web-сервера, в результате чего их невозможно или практически невозможно протестировать в другом контексте. Реализации представления с преобразованием значительно легче поддаются тестированию и могут функционировать и при отсутствии запущенного Web-сервера.
Обсуждая варианты представления, нельзя не вспомнить о двухэтапном представлении (Two Step View). В зависимости от используемой схемы шаблона, это типовое решение можно реализовать и с применением специальных дескрипторов. Тем не менее реализация двухэтапного представления на основе представления с преобразованием может оказаться значительно легче.
3.5.5 Паттерн Transform View
Представление с преобразованием (Transform View) Представление, которое поочередно обрабатывает элементы данных домена и преобразует их в код HTML.
Выполняя запросы к слоям домена и источника данных, вы получаете от них нужные данные, однако без форматирования, необходимого для создания Web-страницы. Визуализацией полученных данных в элементы Web-страницы занимается объект, выполняющий роль представления в шаблоне MVC. В типовом решении представление с преобразованием процесс визуализации данных рассматривается как преобразование, на вход которого подаются данные из модели, а на выходе принимается код HTML.
Принцип действия
В основе типового решения представление с преобразованием лежит идея написания программы, которая бы просматривала данные домена и преобразовывала их в код
HTML. В процессе выполнения такая программа последовательно проходит по структуре данных домена и, обнаруживая новый фрагмент данных, создает их описание в терминах HTML
Основное отличие представления с преобразованием от представления по шаблону заключается в способе организации представления. Представление по шаблону организовано с учетом размещения на экране выходных данных. Представление с преобразованием ориентировано на использование отдельных преобразований для каждого вида входных данных. Преобразованиями управляет нечто наподобие простого цикла, который поочередно просматривает каждый входной элемент, подбирает для него подходящее преобразование и применяет это преобразование. Таким образом, правила представления с преобразованием могут быть организованы в любом порядке - на результат это не повлияет.
Представление с преобразованием может быть написано на любом языке. Тем не менеена данный момент наиболее популярным языком для написания представлений с преобразованием является XSLT.
Для применения преобразований XSLT данные домена должны находиться в формате XML Этого проще достичь, когда логика домена сразу же возвращает данные в формате XML или любом другом, который может быть легко преобразован в XML, например объекты .NET. В противном случае придется самостоятельно генерировать код XML
Код XML, поступающий на вход преобразования, не обязательно должен быть строкой (если только этого не требует канал передачи данных). Как правило, гораздо быстрее и легче организовать входные данные в модель DOM.
Данные домена в формате XML передаются процессору XSLT. В последнее время на рынке программного обеспечения доступно все больше и больше коммерческих процессоров XSLT. Логика преобразования содержится в таблице стилей XSLT, которая также передается процессору. Последний применяет таблицу стилей к входным данным XML и преобразует их в код HTML, который сразу же может быть помещен в HTTP-запрос.
Назначение
Выбор между представлением с преобразованием и представлением по шаблону зависит от того, какую среду разработки предпочитает команда, занимающаяся проектированием представлений. Ключевым фактором здесь является наличие необходимых средств. Для написания представлений по шаблону можно использовать практически любой HTML-редактор, в то время как средства для работы с XSLT не так распространены, да и возможностей у них значительно меньше. Кроме того, язык XSLT представляет собой достаточно сложную смесь функционального программирования и синтаксиса XML, а потому овладеть им сможет далеко не каждый.
3.5.6 Паттерн Two Step View
Двухэтапное представление (Two Step View). Выполняет визуализацию данных домена в два этапа: вначале формирует некое подобие логической страницы, после чего преобразует логическую странииу в формат HTML.
Если разрабатываемое Web-приложение содержит много страниц, вам, скорее всего, захочется оформить и организовать их в одном стиле. Действительно, сайт, каждая страница которого имеет совершенно другой вид, способен окончательно запутать посетителей. Кроме того, вам может понадобиться быстрый способ глобального изменения внешнего вида приложения. К сожалению, использование представления по шаблону или представления с преобразованием значительно затруднит этот процесс. Данные типовые решения не исключают дублирования фрагментов представлений в нескольких страницах или компонентах преобразований, в результате чего глобальное изменение внешнего вида может потребовать внесения изменений в несколько различных файлов.
Избежать подобных проблем помогает двухэтапное представление, выполняющее преобразование данных в два этапа. Вначале данные модели преобразуются в логическое представление, не содержащее какого-либо специального форматирования. Затем полученное логическое представление путем применения необходимого форматирования трансформируется в HTML. В этом случае глобальные изменения внешнего вида Web-сайта приходится проводить только в одном месте, а именно на втором этапе преобразования. Кроме того, подобная схема позволяет отображать одни и те же данные несколькими способами, что также определяется на втором этапе.
Принцип действия
Главной особенностью этого типового решения является выполнение преобразования данных в формат HTML в два этапа. На первом этапе информация, полученная от модели, организуется в некую логическую структуру, которая описывает визуальные элементы будущего отображения, однако еще не содержит кода HTML. На втором этапе полученная структура преобразуется в код HTML.
Упомянутая промежуточная структура представляет собой некоторое подобие логического "экрана". Ее элементами могут быть поля ввода, верхние и нижние колонтитулы, таблицы, переключатели и т.п. В связи с этим данную структуру можно по праву назвать моделью представления. Очевидно также, что она вынуждает будущие страницы сайта следовать одному стилю. Для большей наглядности модель представления можно представить себе как систему, которая определяет элементы управления страницы и содержащиеся в них данные, однако не описывает их внешний вид в терминах HTML.
Для построения каждого логического окна применяется собственный код. Методы первого этапа обращаются к модели данных домена, будь то база данных, модель предметной области (Domain Model) или объект переноса данных (Data Transfer Object), извлекают из нее информацию, необходимую для построения экрана, и помещают эту информацию в логическое представление.
На втором этапе полученная логическая структура преобразуется в код HTML. Методы второго этапа "знают", какие элементы есть в логической структуре и как визуализировать каждый из этих элементов. Таким образом, система с множеством экранов может быть трансформирована в код HTML путем единственного прохождения второго этапа, благодаря чему решение о варианте преобразования в HTML принимается в одном месте. Разумеется, воспользоваться таким преимуществом удастся только в том случае, когда логические экраны компонуются по одному принципу.
Существует несколько способов построени двухэтапного представления. Наиболее простой из них — двухэтапное применение XSLT. Одноэтапное применение технологии XSLT следует подходу, реализованному в представлении с преобразованием, при котором каждой странице соответствует своя таблица стилей XSLT, преобразующая данные домена в формате XML в код HTML. В двухэтапном варианте этого подхода применяются две таблицы стилей XSLT: первая преобразует данные домена в формате XML в логическое представление в формате XML, а вторая преобразует логическое представление в формате ХМL в код HTML
Возможной альтернативой этому подходу является использование классов. В этом случае логическое представление определяется как набор классов: класс таблицы, класс строки и т.п. (рис. 3.25). Методы первого этапа извлекают данные домена и создают экземпляры описанных классов, помещая данные в структуру, моделирующую логический экран. На втором этапе для полученных экземпляров классов генерируется код HTML Это делают либо сами классы, либо специальный класс, предназначенный для выполнения визуализации. И первый и второй подход основан на применении представления с преобразованием.
Вместо этого двухэтапное представление может быть построено на основе представления по шаблону. В этом случае шаблон страницы составляется с учетом структуры логического экрана, например:
<field label = "Name" value = "getName" />
Рисунок 3.25 Пример двухэтапного преобразования с ипользованием классов
После этого система шаблонов преобразует "логические" дескрипторы, подобные показанному выше, в формат HTML При такой схеме определение страницы не содержит кода HTML, а только дескрипторы логического экрана, вследствие чего полученная страница будет представлять собой документ XML и не сможет быть отредактирована с помощью HTML-редакторов типа WYSIWYG.
Назначение
Главным преимуществом двухэтапного представления является возможность разбить преобразование данных на два этапа, что облегчает проведение глобальных изменений. Подобная схема преобразования может оказаться чрезвычайно полезной в двух ситуациях: Web-приложения с несколькими вариантами внешнего вида и Web-приложения с одним варианто внешнего вида. Что касается Web-приложений с несколькими вариантами внешнего вида, они еще не так распространены, однако все больше и больше входят в употребление. В таких приложениях одна и та же базовая функциональность используется разными компаниями и сайт каждой компании имеет собственное оформление. Хорошим примером подобных приложений являются системы бронирования билетов различных авиакомпаний. Каждая из этих систем имеет свой внешний вид, однако, приглядевшись к структуре их страниц, легко заметить, что в их основе лежит одно и то же базовое решение
Список используемой (рекомендуемой) литературы
1. Г. Буч. Объектно-ориентированный анализ и проектирование с примерами приложений на С++. Бином, 1998 г.
2. К. Ларман. Применение UML и шаблонов проектирования. Второе издание. Издательский дом "Вильямс", 2004 г.
3. Гамма, Хелм, Джонсон, Влиссидес. Приемы объектно-ориентированного проектирования. Паттерны проектирования. Питер, 2001
4. М. Фаулер. Архитектура корпоративных программных приложений. Издательский дом "Вильямс", 2006 г.
Дополнительная литература
5. Len Bass, Paul Clements, Rick Kazman. Software Architecture in Practice, Second Edition. Addison Wesley, 2003 г.
6. Raphael Malveau, Thomas J. Mowbray. Software Acchitect Bootcamp. Prentice Hall PTR, 2000 г